





文章目录
1. 题目
It is a regression task: Given 10m data samples as train set, each of 13 features, please predict the label (range unlimited) for the whole test set containing 10915121 data samples. This project expects you to design and implement a parallel decision tree algorithm, i.e. GDBT or Random Forest.
2. 题目分析
题目要求实现一个并行决策树用于回归任务,训练集有10m个数据项,测试集有10915121 个数据项。
3. 解决过程
一开始准备自己搭建GBDT树,看了一下sklearn中的源代码,发现太过于复杂,由于这学期课程太多,无力实现,所以最终决定调用现成的库来实现。
决策树有很多种,常见的有随机森林和GBDT树。随机森林在训练时,树与树之间是相互独立的,可以实现并行化生成,所以一开始打算使用随机森林来完成该任务。而GBDT在迭代的过程中,一棵树的生成依赖上一棵树的残差,整个流程是串行化的。鉴于这个特点,一开始试着用随机森林来解决问题,但是随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
此路不通就另寻他法,了解到有一个叫lightGBM的东西,而且性能不错。更快的训练效率,低内存使用,更高的准确率并且支持并行化学习这就决定了它可以处理大规模数据。因此下面将一个个介绍这些模型以及模型的基本原理,最后再加上我的实现。
1. Bagging
介绍随机森林之前必须先介绍Bagging。RF与GBDT不同的地方就在于RF使用Bagging而GBDT使用的是Boosting。
产生n个样本的方法可以采用Bootstraping法,其实就是一种用于产生n个样本的有放回的抽样方法。这意味着如果我们把训练数据随机分成两部分,并且给二者都训练一个决策树,我们得到的结果可能就会相当不同。Bootstrap 聚集,或者叫做Bagging,是减少统计学习方法的方差的通用过程。
Bagging即套袋法,其算法过程如下:
- 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中,实际上大约有30%的数据不会被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
2. Boosting
bagging的核心思想是针对样本进行有放回的抽样,而boosting的核心思想则是将弱分类器组装成一个强分类器。GBDT在回归问题中,把回归任务分成多个小任务,用多棵树来拟合残差。在PAC(概率近似正确)学习框架下,则一定可以将弱分类器组装成一个强分类器。
boosting类型的算法主要面临有两个核心问题:
- 在每一轮如何改变训练数据的权值或概率分布?
boosting一般的做法是通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。 - 通过什么方式来组合弱分类器?
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。而提升树(GBDT)通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
Bagging和Boosting的区别:
-
样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。 -
样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。 -
预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。 -
并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
3. 随机森林(Random Forest)
随机森林的集成学习方法是bagging ,但是和bagging 不同的是bagging只使用bootstrap有放回的采样样本,但随机森林即随机采样样本,也随机选择特征,因此防止过拟合能力更强,降低方差。
对于普通的决策树,我们会在节点上所有的n个样本特征中选择一个最优的特征来做决策树的左右子树划分,但是RF通过随机选择节点上的一部分样本特征,这个数字小于n。
随机森林的随机性主要体现在两个方面:
- 数据集的随机选取:从原始的数据集中采取有放回的抽样(bagging),构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。
- 待选特征的随机选取:与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。
随机森林的优点:
- 实现简单,训练速度快,泛化能力强,可以并行实现,因为训练时树与树之间是相互独立的,可以并行这点对于数据量大的场景就很重要。
- 能处理高维数据(即特征很多),并且不用做特征选择,因为特征子集是随机选取的。这一点对于大数据量也很重要,因为大数据集上通常会面临维度灾难(Dimensional disaster)。
- 相比其他算法,不是很怕特征缺失,因为待选特征也是随机选取;
- 相比单一决策树,能学习到特征之间的相互影响,且不容易过拟合;
- 对于不平衡的数据集,可以平衡误差;
- 训练完成后可以给出哪些特征比较重要,这一点对于提高模型的可解释性也很重要。
随机森林的不足之处在于:
- 在噪声过大的分类和回归问题还是容易过拟合;
- 相比于单一决策树,它的随机性让我们难以对模型进行解释。
4. 梯度提升决策树(Gradient Boosting Decision Tree)
GBDT中的树都是回归树,不是分类树 ,因为gradient boost 需要按照损失函数的梯度近似的拟合残差,这样拟合的是连续数值,因此只有回归树。
Gradient Boosting是一种Boosting的方法,其与传统的Boosting的区别是,每一次的计算是为了减少上一次的残差(residual),而为了消除残差,可以在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boosting中,每个新的模型的建立是为了使得之前模型的残差往梯度方向减少,与传统Boosting对正确、错误样本进行加权有着很大的区别。这个梯度代表上一轮学习器损失函数对预测值求导。
算法原理:

实例:
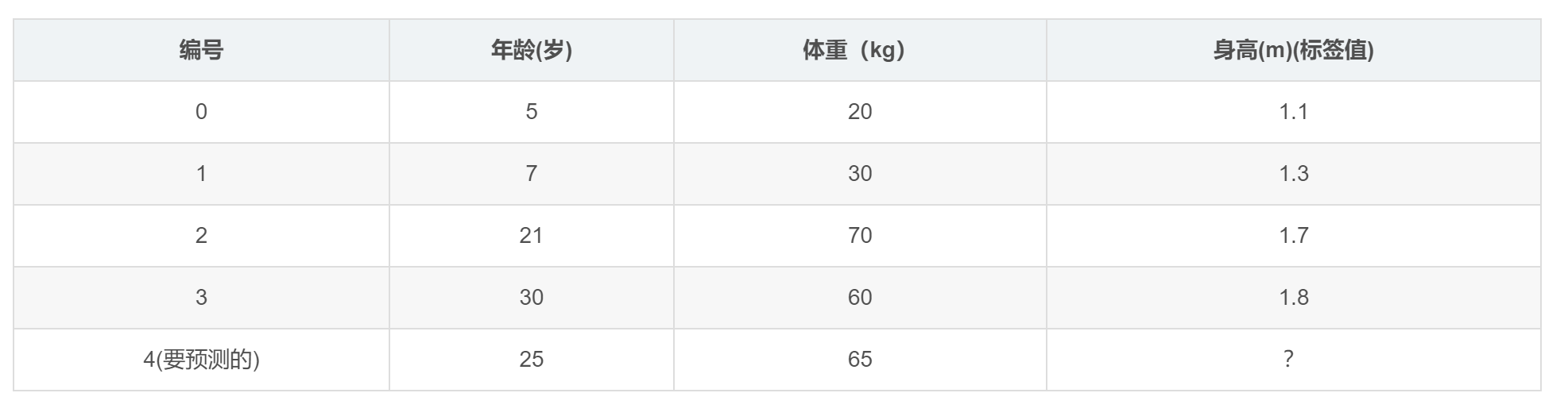
参数设置:
- 学习率:learning_rate=0.1
- 迭代次数:n_trees=5
- 树的深度:max_depth=3
初始化时,c 取值为所有训练样本标签值的均值,也就是1.475。
第一轮迭代的残差:
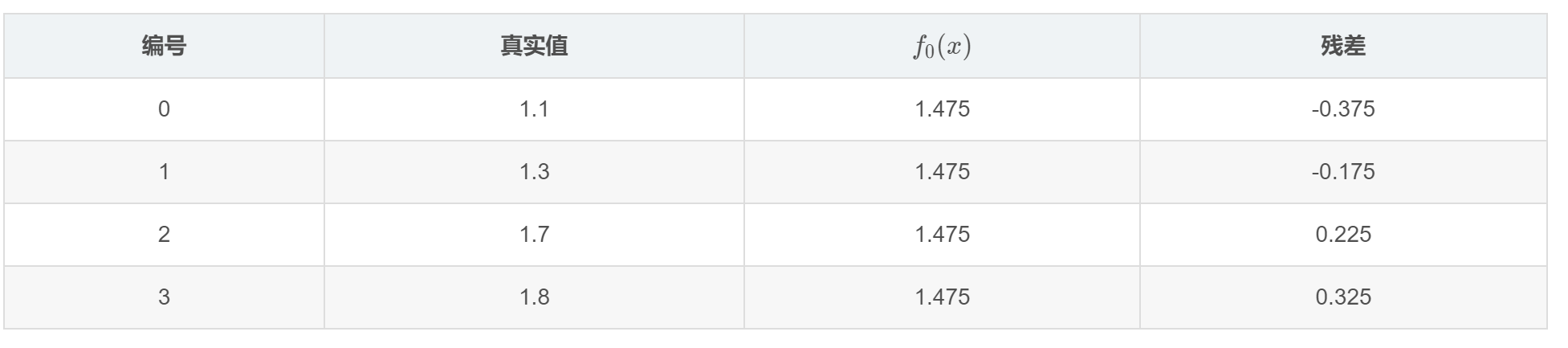
用残差作为目标值,用它来训练第一棵树拟合
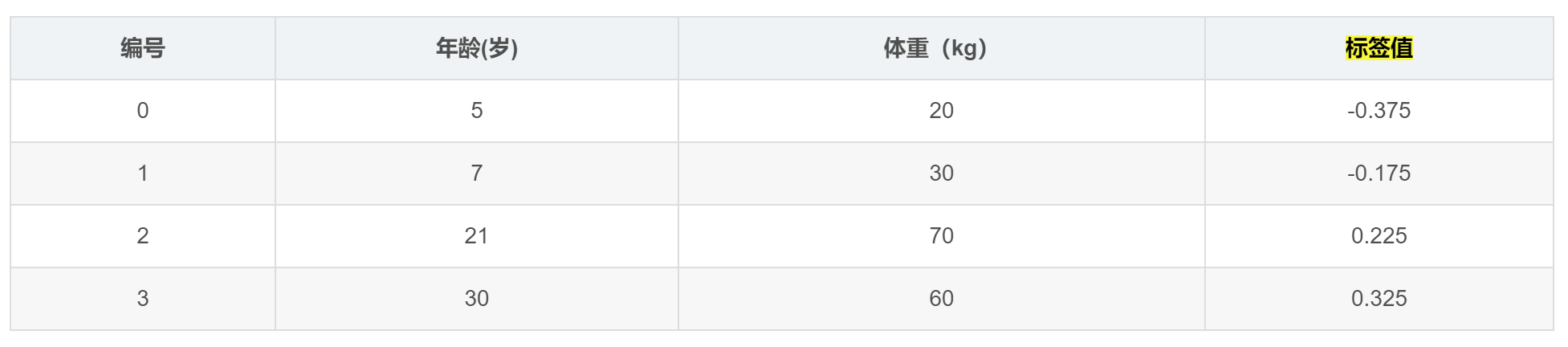
接着,寻找回归树的最佳划分节点,遍历每个特征的每个可能取值,找到最佳划分点。

根据上表,选年龄21为划分点,得到树:
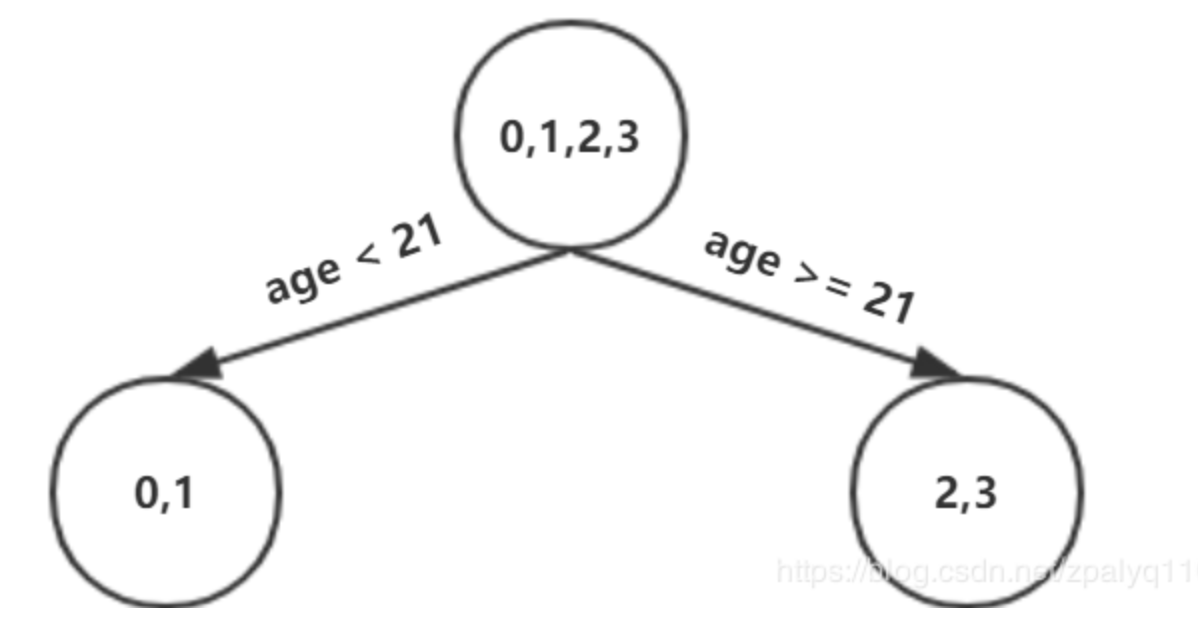
由于我们设置了树的深度为3,则需要进行再次分裂:
对于左节点,只含有0,1两个样本,根据下表我们选择年龄7划分
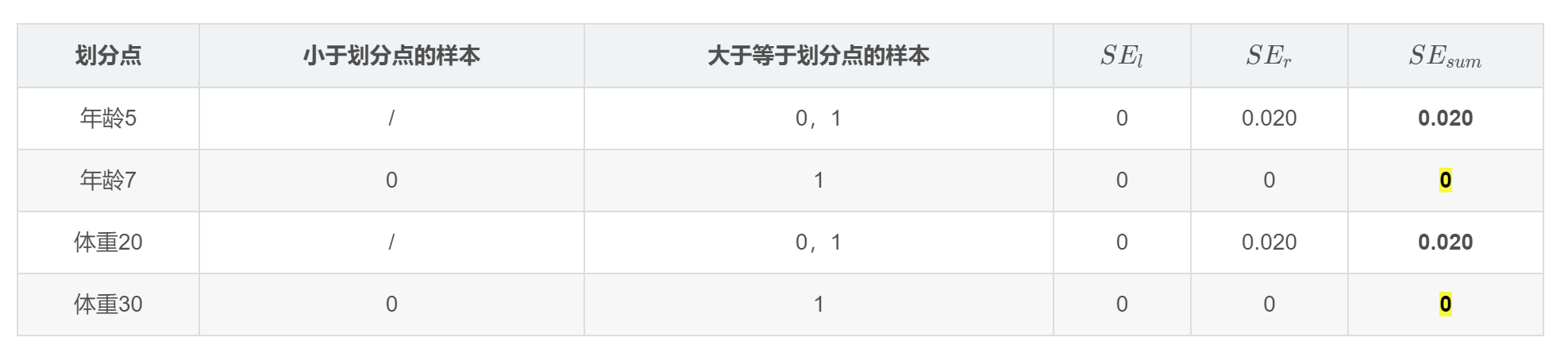
对于右节点,只含有2,3两个样本,根据下表我们选择年龄30划分
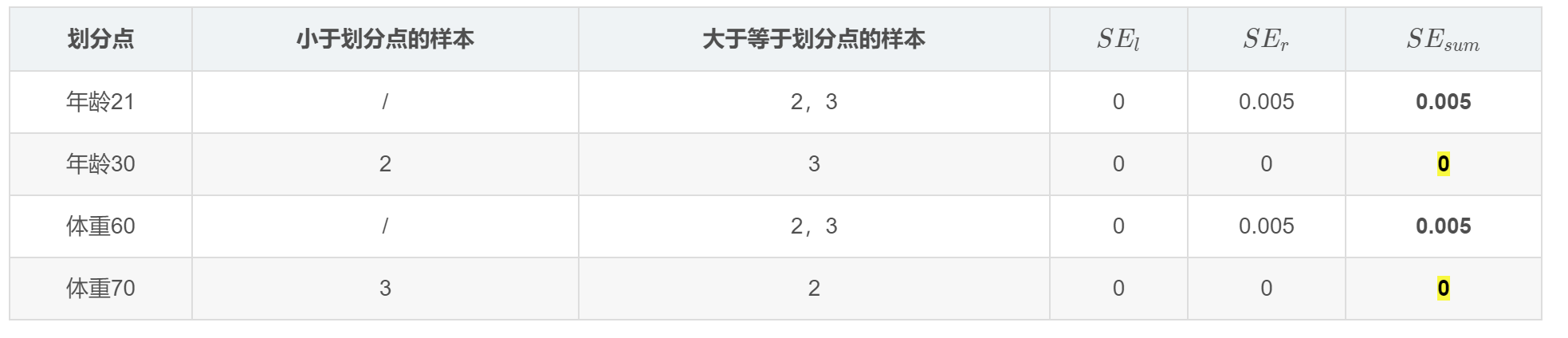
可以得到
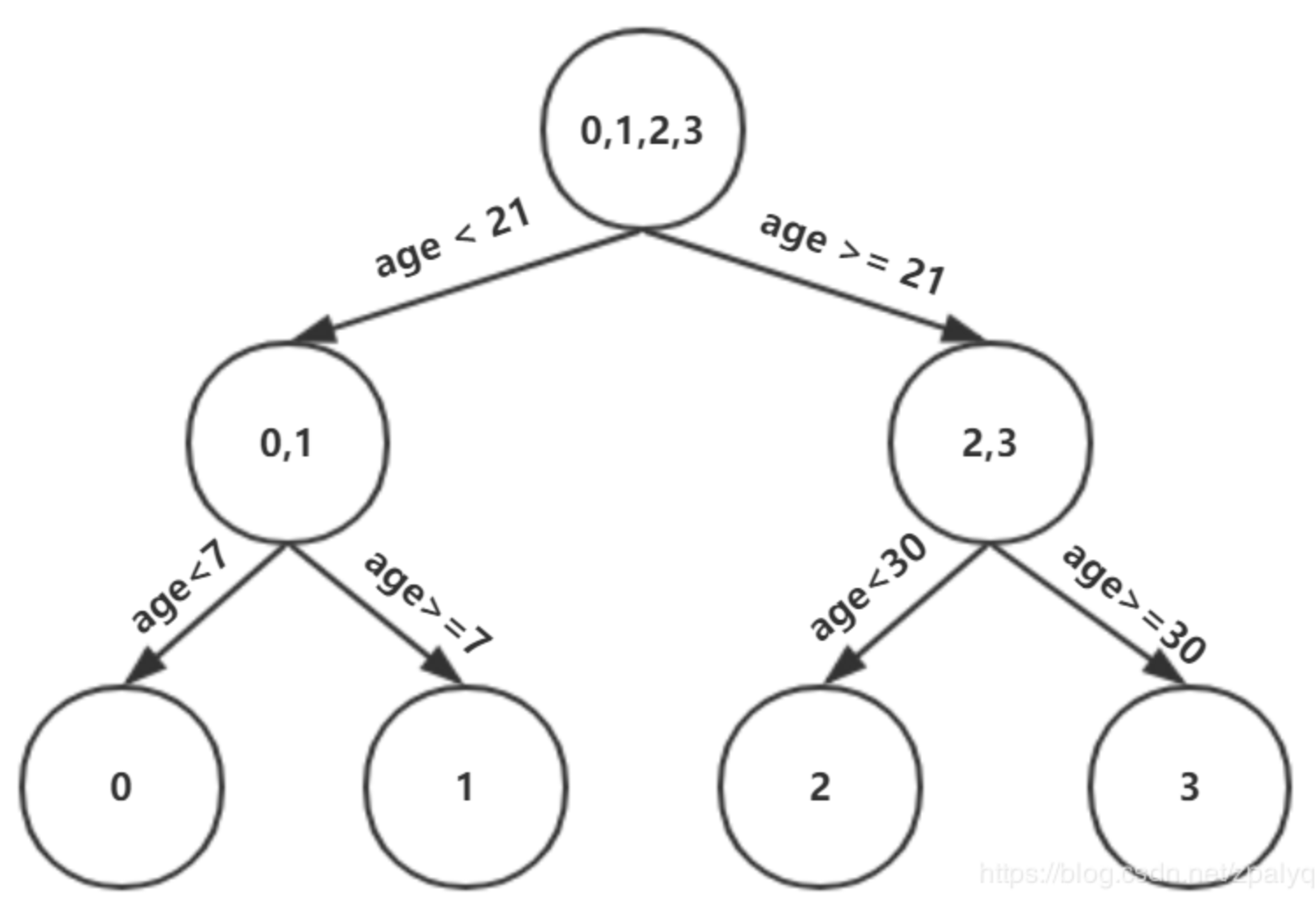
此时我们的树深度满足了设置,还需要做一件事情,给这每个叶子节点分别赋一个参数r,来拟合残差。每个叶节点的参数r在回归任务中其实就是对应节点中所有项目的y值的均值,最终得到树

拟合第二棵树时,目标值是加上第一棵树的对应的叶子节点的值乘学习率后的到的值与原本y值的差,重复这个过程。最终得到的树为:
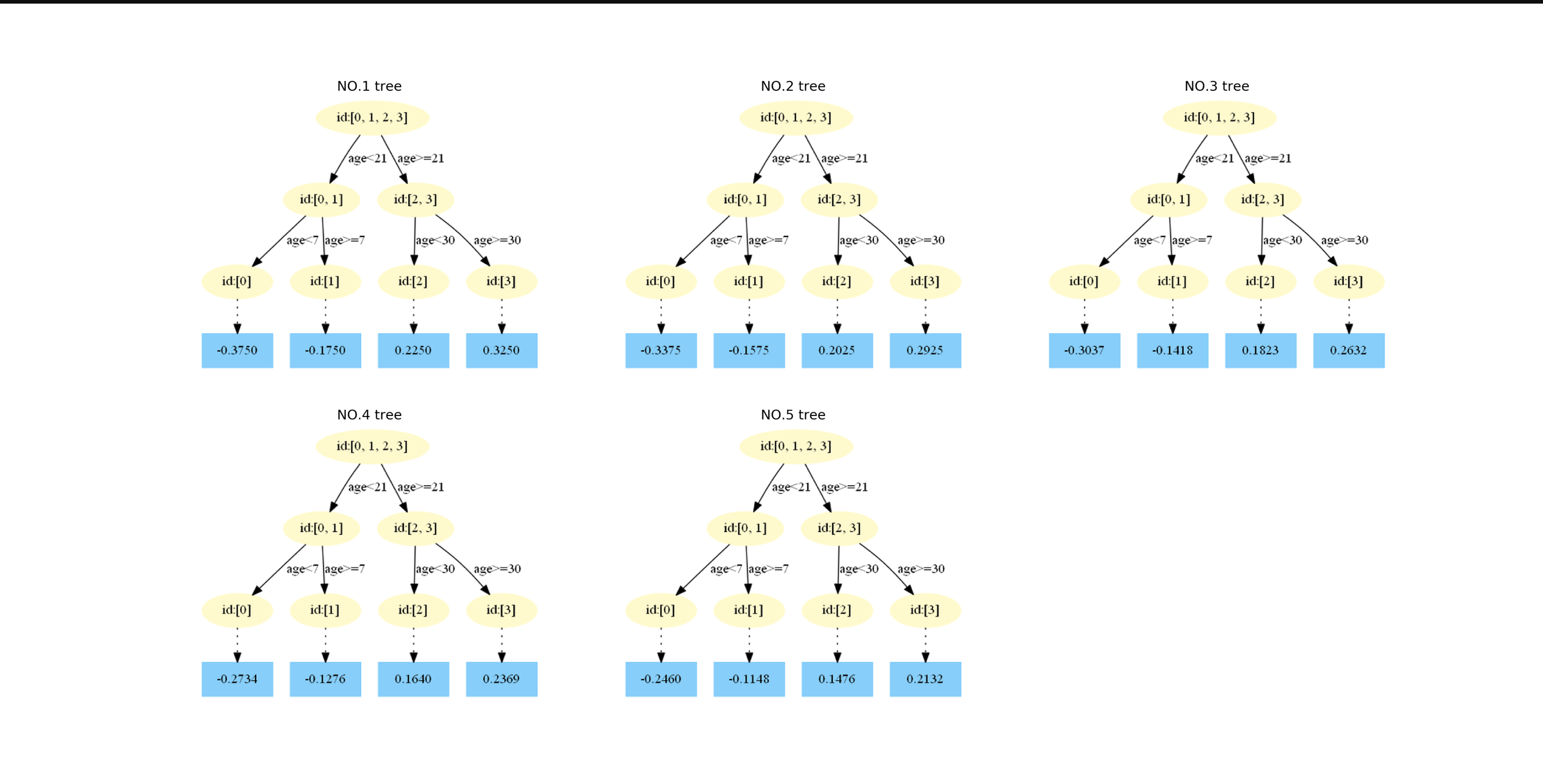
GBDT的优点:
- GBDT适用面广,离散或连续的数据都可以处理。
- GBDT几乎可用于所有回归问题(线性/非线性),也可以用于二分类问题。
缺点: - 由于弱分类器的依赖关系,GBDT的并行训练比较难。
5. LightGBM
LightGBM 是一个梯度Boosting框架,使用基于决策树的学习算法。它可以说是分布式的,高效的,有以下优势:
- 更快的训练效率
- 低内存使用
- 更高的准确率
- 支持并行化学习
- 可以处理大规模数据
LightGBM一大的特点是在传统的GBDT基础上引入了两个 新技术和一个改进:
(1)Gradient-based One-Side Sampling(GOSS)技术是去掉了很大一部分梯度很小的数据,只使用剩下的去估计信息增益,避免低梯度长尾部分的影响。由于梯度大的数据在计算信息增益的时候更重要,所以GOSS在小很多的数据上仍然可以取得相当准确的估计值。
(2)Exclusive Feature Bundling(EFB)技术是指捆绑互斥的特征(i.e.,他们经常同时取值为0),以减少特征的数量。但对互斥特征寻找最佳的捆绑方式是一个NP难问题,当时贪婪算法可以取得相当好的近似率(因此可以在不显著影响分裂点选择的准确性的情况下,显著地减少特征数量)。
(3)在传统GBDT算法中,最耗时的步骤是找到最优划分点,传统方法是Pre-Sorted方式,其会在排好序的特征值上枚举所有可能的特征点,而LightGBM中会使用histogram算法替换了传统的Pre-Sorted。基本思想是先把连续的浮点特征值离散化成k个整数,同时构造出图8所示的一个宽度为k的直方图。最开始时将离散化后的值作为索引在直方图中累积统计量,当遍历完一次数据后,直方图累积了离散化需要的统计量,之后进行节点分裂时,可以根据直方图上的离散值,从这k个桶中找到最佳的划分点,从而能更快的找到最优的分割点,而且因为直方图算法无需像Pre-Sorted那样存储预排序的结果,而只是保存特征离散过得数值,所以使用直方图的方式可以减少对内存的消耗。
原理:
-
直方图算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。在XGBoost中需要遍历所有离散化的值,而在这里只要遍历k个直方图的值。 -
LightGBM的直方图做差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后(父节点在上一轮就已经计算出来了),可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。 -
带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。 -
直接支持高效并行
-
LightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。
- 特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
- 数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化,在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
6. 代码实现
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import r2_score
x = np.array(pd.read_csv("./data1/train/train.csv"))
y = pd.read_csv("./data1/label/label.csv")
min_max_scaler = preprocessing.MinMaxScaler()
x = min_max_scaler.fit_transform(x)
#划分训练集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.15, random_state=16319058)
train_data = lgb.Dataset(data=x_train,label=y_train)
test_data = lgb.Dataset(data=x_test,label=y_test)
#网格搜索查找最优参数
model_lgb = lgb.LGBMRegressor(objective='regression', n_estimators=43,metric='rmse')
params_test1={
'learning_rate':[0.01, 0.1, 1],
'max_depth':range(4, 7),
'num_leaves':range(100, 124, 2)
}
gsearch1 = GridSearchCV(estimator=model_lgb, param_grid=params_test1, scoring='neg_mean_squared_error', cv=5, verbose=1, n_jobs=4)
gsearch1.fit(x_train, y_train)
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
#模型参数
param = {
'objective':'regression',
'num_leaves':124,
'max_depth':7,
'learning_rate': 0.01,
'metric': 'rmse',
}
num_round = 1000
evals_result = {}
#模型训练
bst = lgb.train(param, train_data, num_round, valid_sets=[test_data], early_stopping_rounds=2,evals_result=evals_result)
#存储模型
bst.save_model('model1.txt')
bst = lgb.Booster(model_file='model1.txt')
#测试集预测
ypred = bst.predict(x, num_iteration=bst.best_iteration)
RMSE = np.sqrt(mean_squared_error(y, ypred))
print("RMSE of predict :",RMSE)
r2_score_ = r2_score(y, ypred)
print('r2 score of predict :', r2_score_)
print('plt result...')
ax = lgb.plot_metric(evals_result, metric='rmse')
plt.show()
print('rank the feature...')
ax = lgb.plot_importance(bst, max_num_features=20)
plt.show()
#预测结果写入
test = pd.read_csv("./data1/test/test.csv", header=None)
x_pred = np.array(test)
x_pred = min_max_scaler.transform(x_pred)
y_pred = bst.predict(x_pred, num_iteration=bst.best_iteration)
id_ = []
for i in range(len(y_pred)):
id_.append(i + 1)
dataframe = pd.DataFrame({'id':id_,'Predicted':y_pred})
dataframe.to_csv("result1.csv",index=False,sep=',')
其中用到网格搜索来获取一定区间内模型的最优参数,比如树的最大深度以及学习率等,但这个操作比较耗时,还用到了归一化来提高模型的泛化能力。
4. 实验感想
- 一开始打算自己完全从决策树开始搭建是在是太难了,决策树涉及到了许多知识点;
- 在本次实验中也加强了对决策树的理解,在模型调参上还需要努力;
- 模型调参真的很耗时而且还不一定能得到好的结果,也许有时间可以试试用多个模型组装,也许能提高泛化能力。















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









