






Solr的工作原理可以简单地概括为以下几个步骤:
1. 索引创建:首先,Solr需要创建一个索引,用于存储要搜索的数据。索引是基于Apache Lucene构建的,它将文档拆分为字段,并对字段进行分析和标记化,以便进行更有效的搜索和匹配。
2. 数据导入:Solr可以从多种数据源导入数据,包括数据库、文件、Web服务等。数据导入可以通过Solr的数据导入处理器或使用SolrJ等客户端库进行。
3. 查询处理:当用户发送查询请求时,Solr会接收并处理该请求。Solr使用查询解析器解析查询语句,并将其转换为可执行的搜索操作。查询解析器支持各种查询类型,包括全文搜索、范围搜索、布尔搜索等。
4. 搜索执行:Solr执行搜索操作,它使用索引中的倒排索引数据结构来查找匹配查询的文档。倒排索引是一种将术语映射到文档的数据结构,以便快速查找匹配的文档。
5. 结果返回:一旦搜索操作完成,Solr将返回匹配查询的文档结果。结果可以根据相关性进行排序,并且可以应用各种过滤器和转换器来处理结果。
6. 高级功能:Solr还提供了许多高级功能,如分面搜索(faceted search),拼写检查(spell checking),结果高亮显示(result highlighting),结果分组(result grouping)等。这些功能可以帮助用户更好地理解和处理搜索结果。
总的来说,Solr通过创建索引、导入数据、处理查询、执行搜索和返回结果等步骤来实现搜索功能。它使用倒排索引来加速搜索,并提供了丰富的功能来满足各种搜索需求。安装Solr
1、下载Solr

wget http://archive.apache.org/dist/lucene/solr/8.9.0/solr-8.9.0.tgz2、上传solr的安装包
solr-8.9.0.tgz #Xshell工具可以使用命令RZ,没安装的使用yum安装,yum install lrzsz 。3、解压缩solr安装包
tar -xvf solr-8.9.0.tgz -C /data/4、进入solr解压目录,修改目录名称
cd /data/ && mv solr-8.9.0 solr
5、启动solr
cd solr/bin
./solr start -force #force,表示使用root账号启动。6、添加防火墙规则
firewall-cmd --add-port=8983/tcp --permanent
firewall-cmd --reload
systemctl start firewalld #或者直接关闭7、正式访问solr
http://82.157.66.134:8983/solr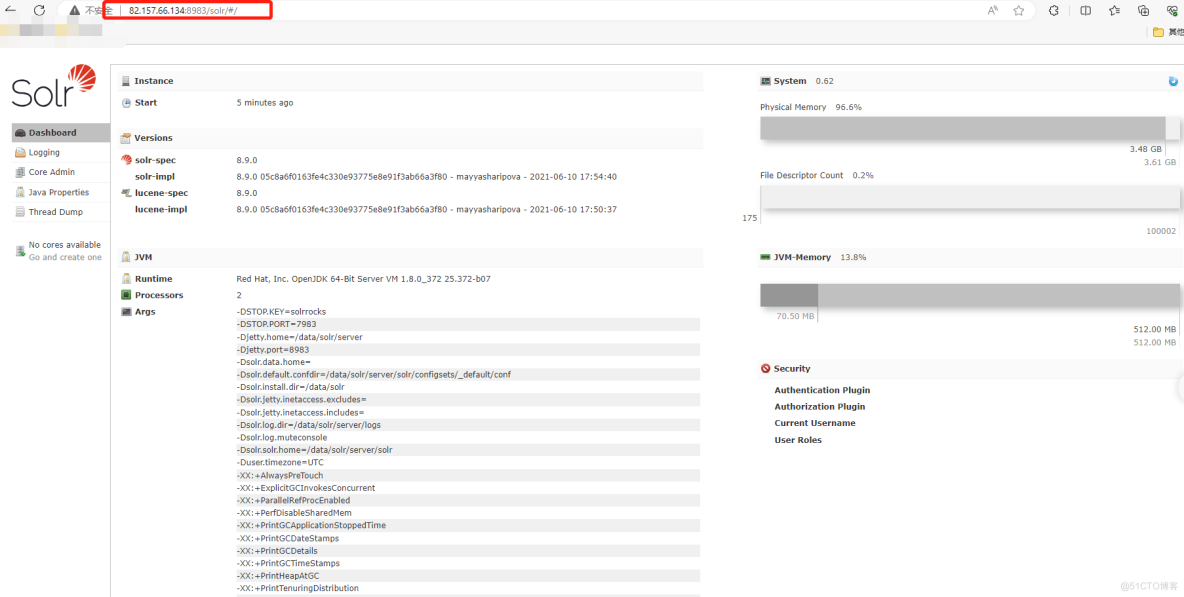
配置Solr
1、创建一个core
cd /data/solr/bin执行如下命令:
./solr create -c core1 -force # -c 后面跟的是core的名称。
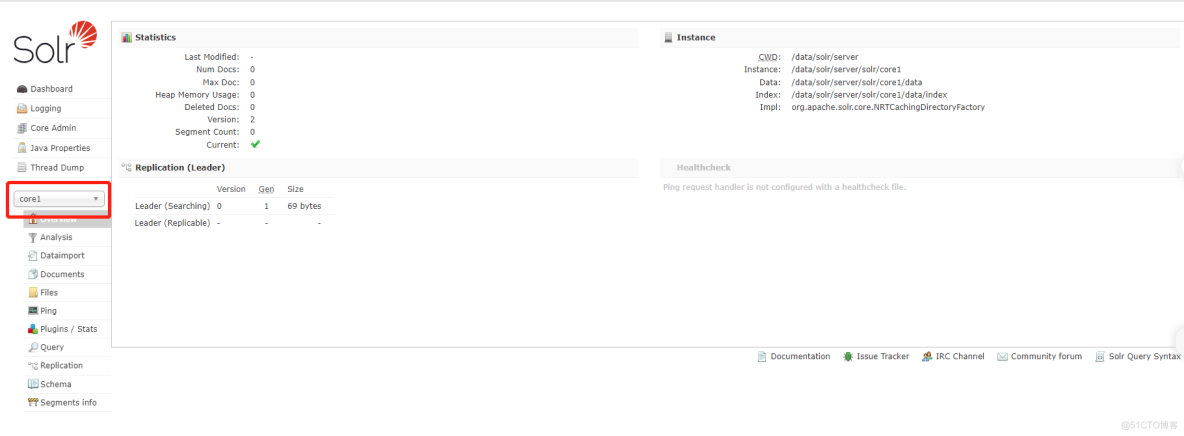
2、测试分词器

3、下载 IKAnalyzer 中文拆词器
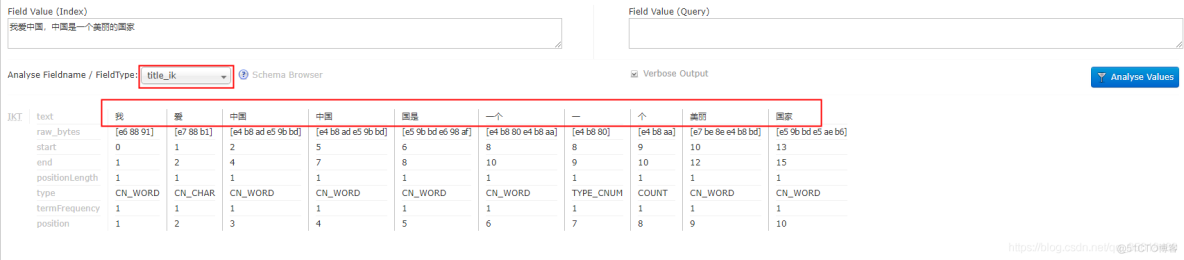
先输入中文,在选择 Analyse Fieldname / FieldType 为title,点击 Analyse Values 按钮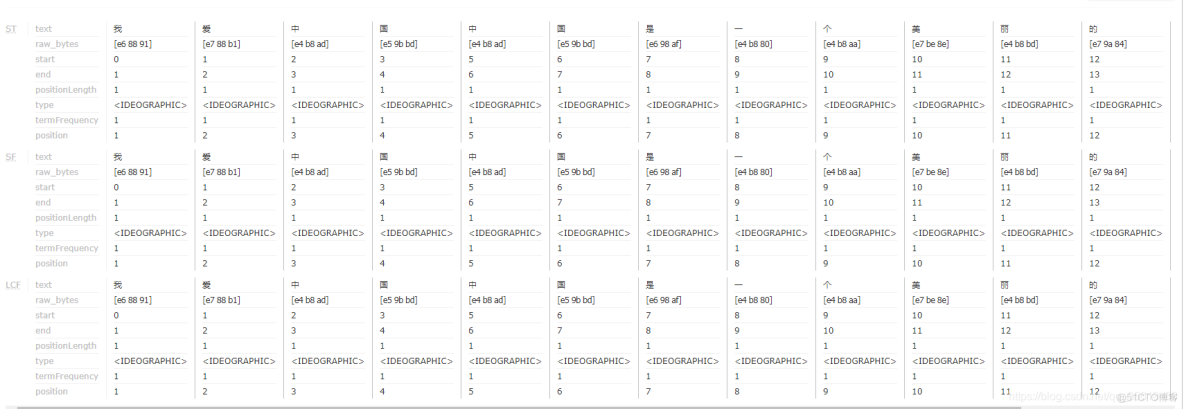
发现拆词器将中文全部拆分,这样是不符合要求的。需要导入中文拆词器。wget http://download.how2j.cn/1687/IKAnalyzer6.5.0.jar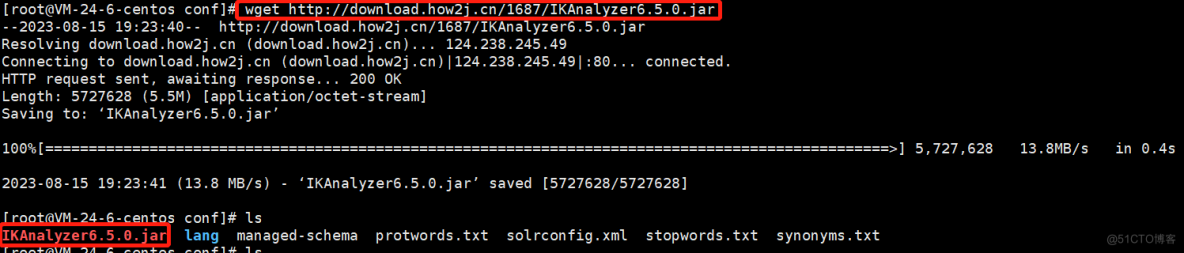
把这个jar包拷贝到 /usr/local/tomcat/tomcat-8.5.37/webapps/solr/WEB-INF/lib/ 目录下面。cp IKAnalyzer6.5.0.jar /usr/local/tomcat/tomcat-8.5.37/webapps/solr/WEB-INF/lib/同时还要修改另外一处。/usr/local/solr/solrhome/co1/conf/目录下面的 managed-schema 添加一段配置。
添加:
<!-- 自定义字段名 start -->
<!--配置中文分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--配置中文分词器使用的field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true"/>
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true" />
<!-- 自定义字段名 end -->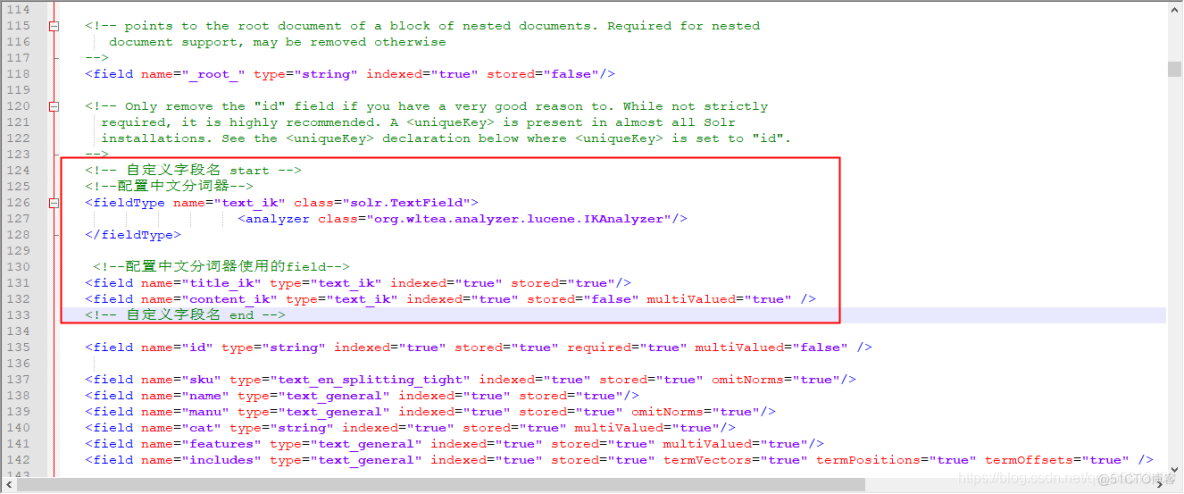
大功告成,重启tomcat,这样拆分就是比较符合要求的。















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









