







我这里选用scrapydweb作为爬虫程序的监控平台。
1.程序安装
pip install scrapydweb
或者去GitHub:https://github.com/my8100/scrapydweb
2.启动
启动前需要保证对应的scrapyd服务已经启动。
scrapydweb
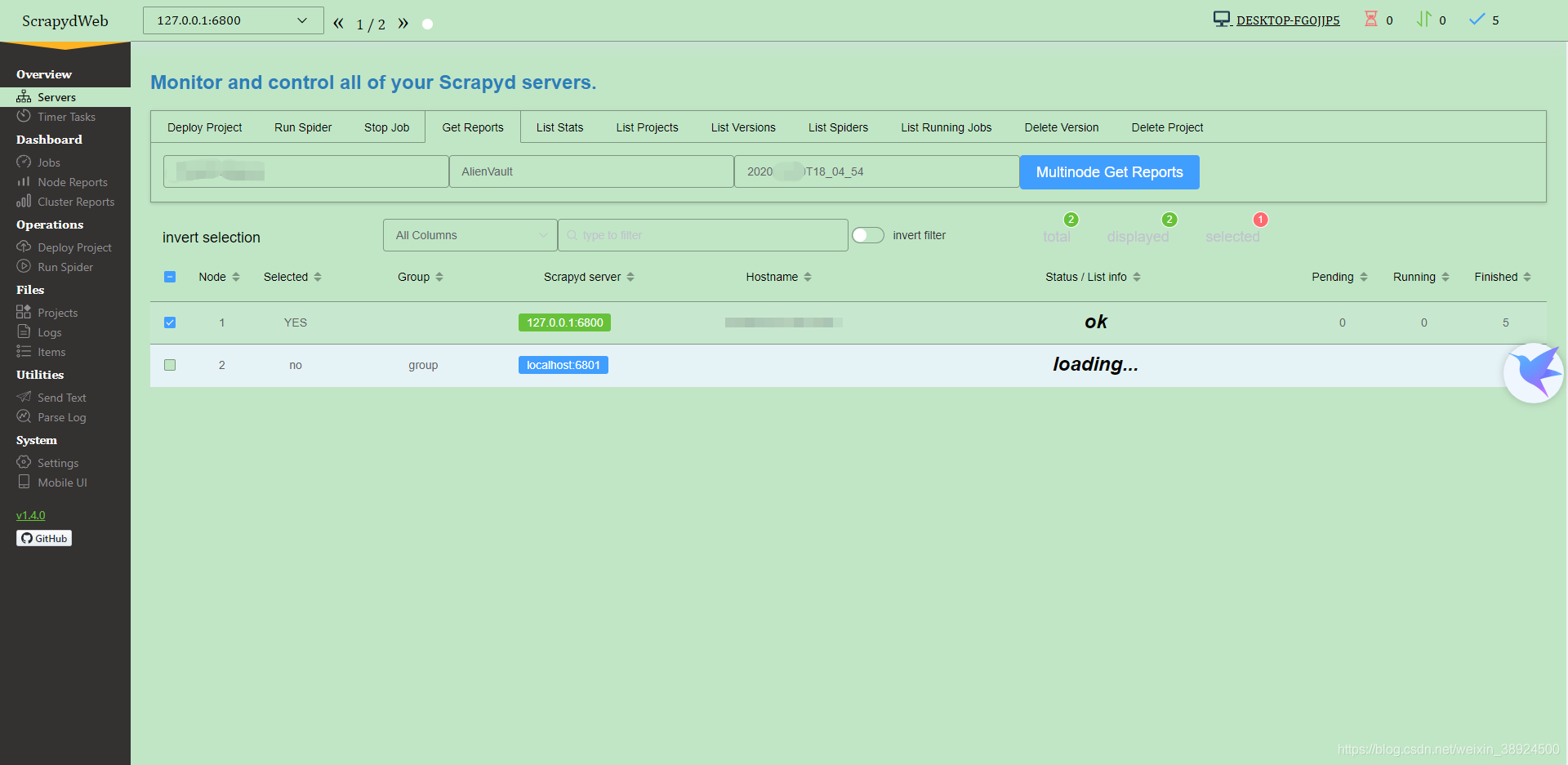
注意:如果出现6801端口无法连接,这个是因为你没有配置集群环境,不用担心。
3.配置
配置文件会在我们当前启动scrapydweb路径下,scrapyweb_settings_v10.py
配置文件中都会有详细的注解,大家可以根据实际需求尽心修改。
3.1启用 HTTP 基本认证(可选)
ENABLE_AUTH = True
USERNAME = 'username'
PASSWORD = 'password'
3.2配置项目路径
这里是scrapydweb比较方便的地方,不用事先将项目先上传到scrapyd服务器,scrapydweb能够帮我们上传。

3.3配置LogParser
如果我们的ScrapydWeb 和某个 Scrapyd 运行于同一台主机,这三个设置项都需要配置。
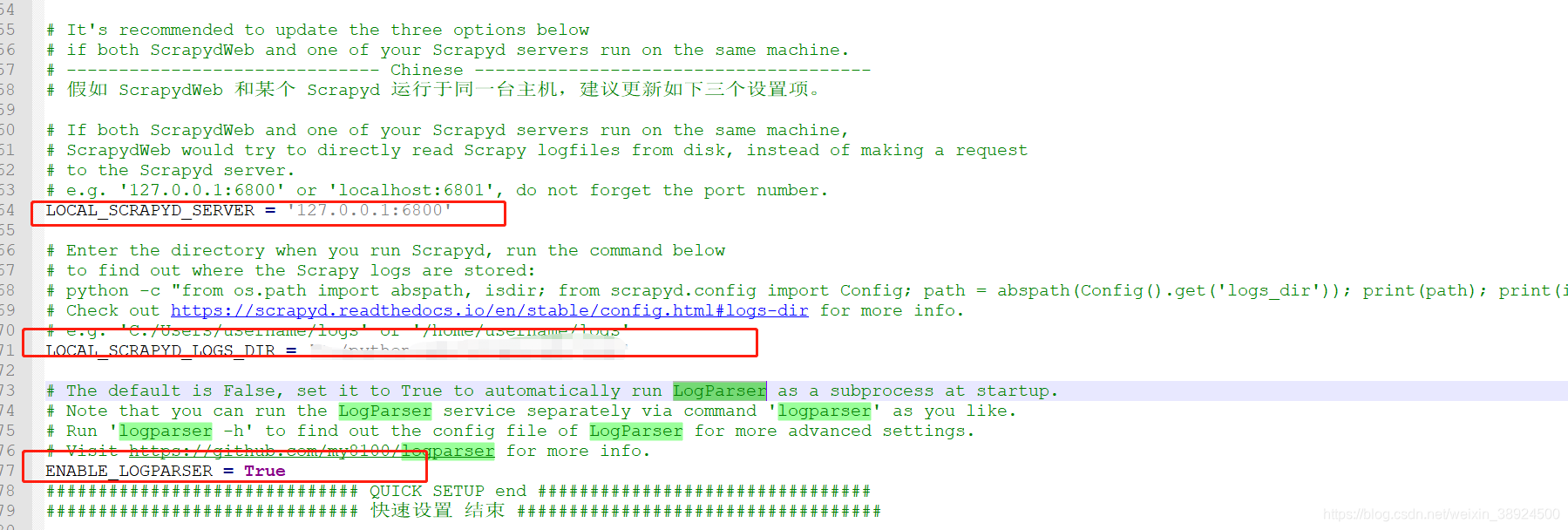
#这个配置时scrapd的server请求地址。
LOCAL_SCRAPYD_SERVER = '127.0.0.1:6800'
注意:如果我们的ScrapydWeb 和某个 Scrapyd 运行于同一台主机,scrapydweb会直接去访问log文件,而不是去请求这地址。
#我们运行scrapyd时会产生一个logs文件夹,这里需要将logs的位置配置
LOCAL_SCRAPYD_LOGS_DIR =‘’
#默认值为False,将其设置为True,可在ScrapydWeb启动时自动将LogParser作为子进程运行。
ENABLE_LOGPARSER = True
3.4远程访问scrapyd
如果需要远程访问 Scrapyd,则需将 Scrapyd 配置文件中的 bind_address 修改为
bind_address = 0.0.0.0
然后重启 Scrapyd service。
4.Scrapydweb使用
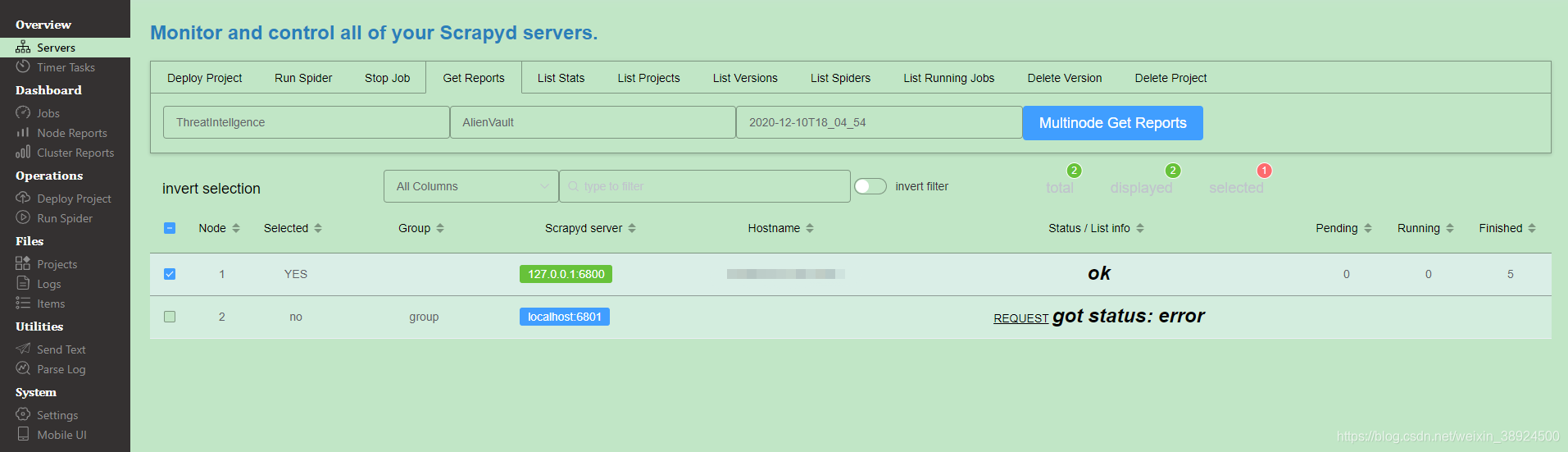
4.1Servers监视和控制所有Scrapyd服务器。
- Servers 页面自动输出所有 Scrapyd server 的运行状态。
- 通过分组和过滤可以自由选择若干台 Scrapyd server,然后在上方 Tabs 标签页中选择 Scrapyd 提供的任一 HTTP JSON API,实现一次操作,批量执行。
4.2Timer tasks计时器任务
4.3 Dashboarder
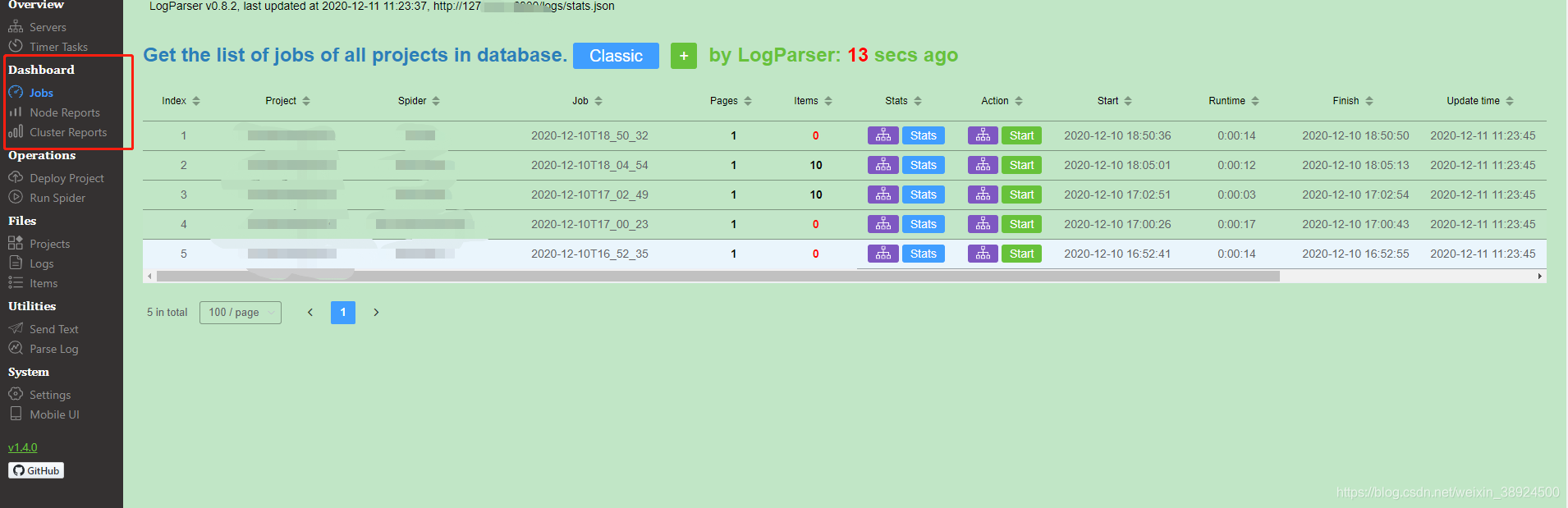
这里有Jobs(任务列表)、Node reports(节点报告)、cluster reports(集群报告),三个模块。
- 通过集成 LogParser,Jobs 页面自动输出爬虫任务的 pages 和 items 数据。
- ScrapydWeb 默认通过定时创建快照将爬虫任务列表信息保存到数据库,即使重启 Scrapyd server 也不会丢失任务信息。
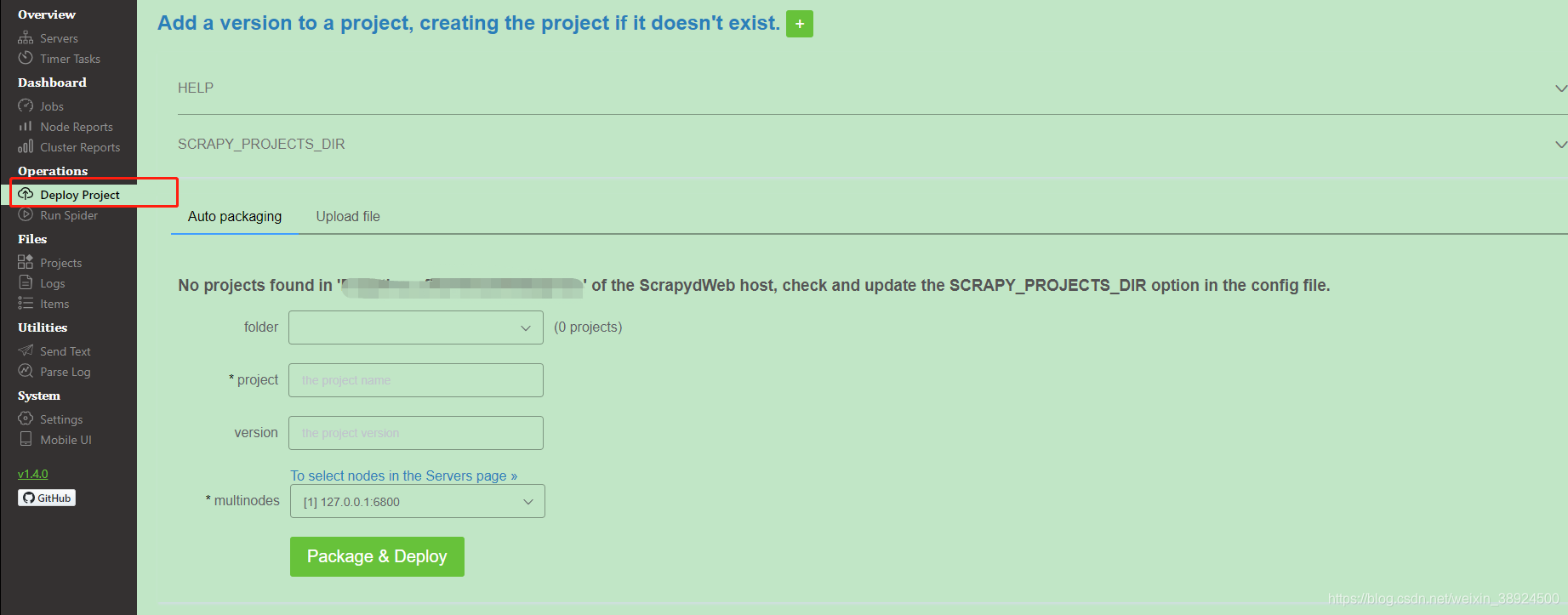
Deploy Project(部署项目)
- 通过配置 SCRAPY_PROJECTS_DIR 指定 Scrapy 项目开发目录,ScrapydWeb 将自动列出该路径下的所有项目,默认选定最新编辑的项目,选择项目后即可自动打包和部署指定项目。
- 如果 ScrapydWeb 运行在远程服务器上,除了通过当前开发主机上传常规的 egg 文件,也可以将整个项目文件夹添加到 zip/tar/tar.gz 压缩文件后直接上传即可,无需手动打包为 egg 文件。
- 支持一键部署项目到 Scrapyd server 集群。
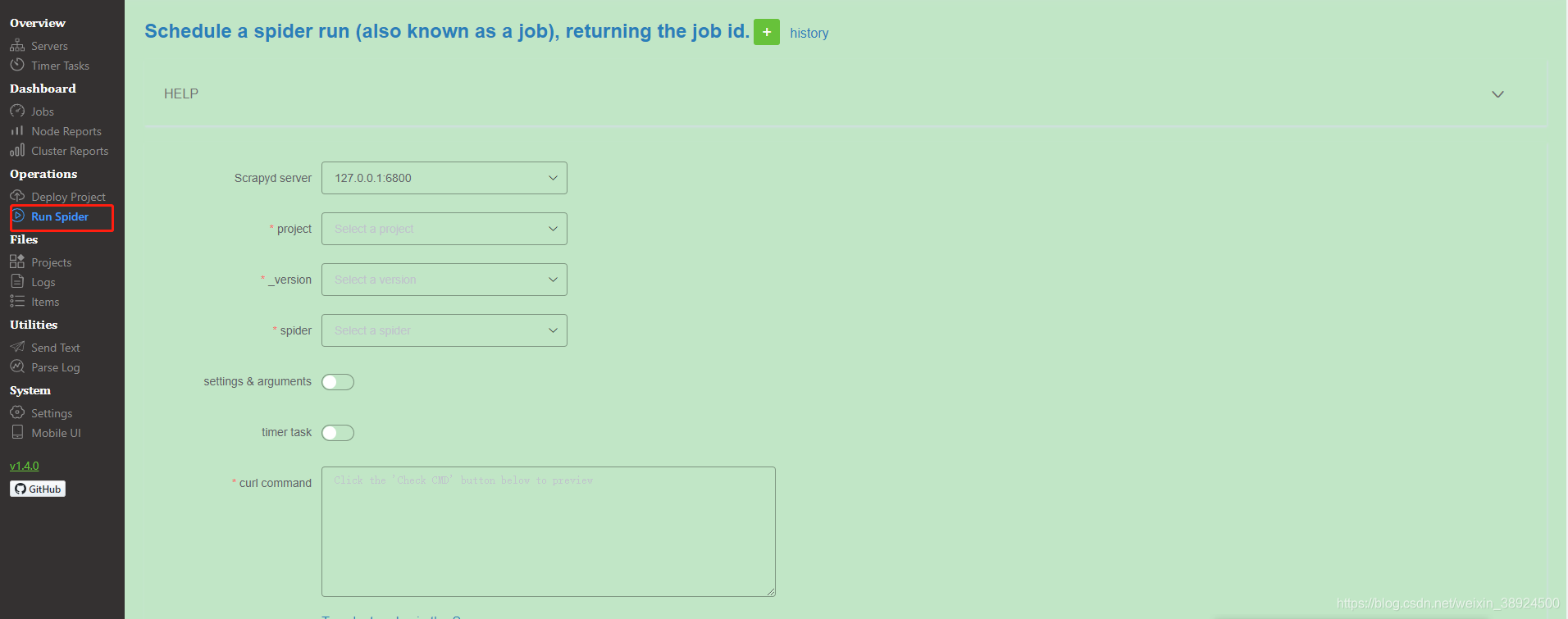
Run Spider(运行爬虫)
- 通过下拉框依次选择 project,version 和 spider。
- 支持传入 Scrapy settings 和 spider arguments。
- 支持创建基于 APScheduler 的定时爬虫任务。(如需同时启动大量爬虫任务,则需调整 Scrapyd 配置文件的 max-proc 参数)
- 支持在 Scrapyd server 集群上一键启动分布式爬虫。
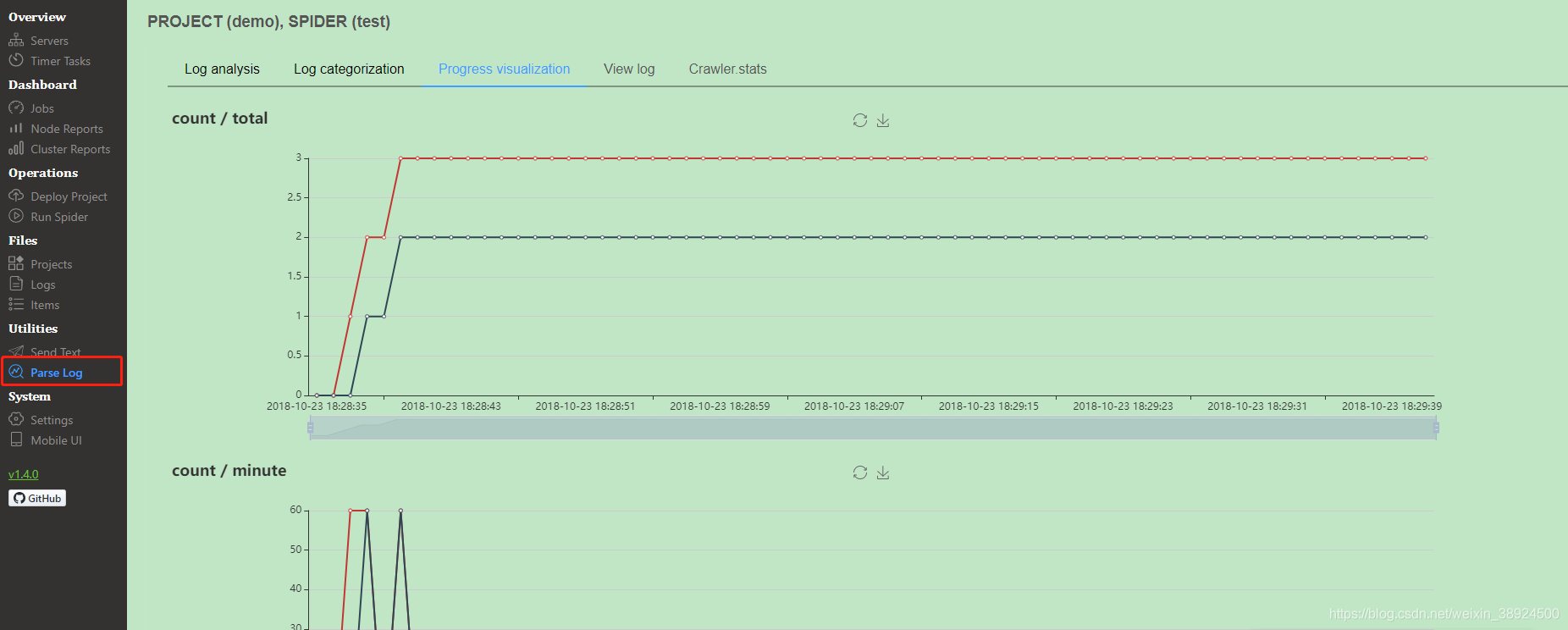
pares log
- 如果在同一台主机运行 Scrapyd 和 ScrapydWeb,建议设置 SCRAPYD_LOGS_DIR 和 - ENABLE_LOGPARSER,则启动 ScrapydWeb 时将自动运行 LogParser,该子进程通过定时增量式解析指定目录下的 Scrapy 日志文件以加快 Stats 页面的生成,避免因请求原始日志文件而占用大量内存和网络资源。
- 同理,如果需要管理 Scrapyd server 集群,建议在其余主机单独安装和启动 LogParser。
- 如果安装的 Scrapy 版本不大于 1.5.1,LogParser 将能够自动通过 Scrapy 内建的 Telnet Console 读取 Crawler.stats 和 Crawler.engine 数据,以便掌握 Scrapy 内部运行状态。
使用文档参靠:https://github.com/my8100/files/blob/master/scrapydweb/README_CN.md














 2580
2580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









