







· 进阶提升:MyBatis一级缓存
MyBatis做为持久层的框架,跟数据库的交互式是最多的,在互联网的这种经常面临的高并发情况下,缓存的中要性不言而喻,比如大家常见的Redis、Memcached等,同样MyBatis也提供了缓存的的机制,MyBatis`提供了两种缓存机制,一级缓存和二级缓存,接下来我们就来先来看下一级缓存的是怎么实现的

一级缓存是MyBatis中的默认提供的缓存的,也就是说,我们在使用Mybatis的时候本身就在使用,他是默认开启的, 一级缓存是SqlSession级别的缓存,只有在一个SqlSession内的查询才能共享缓存的数据,当我们关闭sqlSession的时候或者执行增删改查的操作的时候,缓存就会被清空
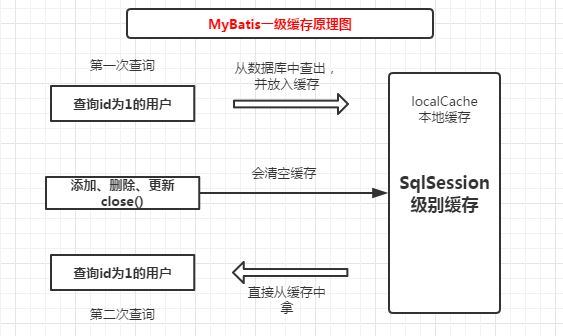
接下来我们来验证下,上代码
/**
* 测试一级缓存
*/
@Test
public void testCacheOne() throws Exception {
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory builder = new SqlSessionFactoryBuilder().build(inputStream);
// 第一次获取sqlsession对象
SqlSession sqlSession = builder.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
System.out.println("第一次查询....");
User user = mapper.selectUserById(1);
System.out.println(user);
// 修改数据
// user.setName("哈哈");
// user.setAge(12);
// int i = mapper.updateUserByUserId(user);
// sqlSession.commit();
// 第二次查询
System.out.println("第一次查询....");
UserMapper mapper1 = sqlSession.getMapper(UserMapper.class);
User user1 = mapper1.selectUserById(1);
System.out.println(user1);
sqlSession.close();
}
验证一级缓存
看下运行结果图
第一次查询....
==> Preparing: select * from t_user where id=?;
==> Parameters: 1(Integer)
<== Columns: id, name, age
<== Row: 1, 嘿嘿, 21
<== Total: 1
User(id=1, name=嘿嘿, age=21)
第一次查询....
User(id=1, name=嘿嘿, age=21)
我们看到在第一次查询的时候,发送了sql去数据库中去查询,在第二次查询的时候没有发送任何sql,并且返回了同样的结果,这就说明在第二次查询的时候,并没有去数据库查询而是去缓存中拿了
清空一级缓存
接着我们在看下清空缓存的测试
第一次查询....
==> Preparing: select * from t_user where id=?;
==> Parameters: 1(Integer)
<== Columns: id, name, age
<== Row: 1, 嘿嘿, 21
<== Total: 1
User(id=1, name=嘿嘿, age=21)
==> Preparing: update t_user set name=?,age=? where id=?
==> Parameters: 哈哈(String), 12(Integer), 1(Integer)
<== Updates: 1
第二次查询....
==> Preparing: select * from t_user where id=?;
==> Parameters: 1(Integer)
<== Columns: id, name, age
<== Row: 1, 哈哈, 12
<== Total: 1
User(id=1, name=哈哈, age=12)
这里可以看出来,在我们执行了update更新语句的时候,MyBatis清空了一级缓存,第二次查询的时候,再一次发送了Sql去数据库中查询
知其然,知其所以然
到这里案例已经帮我证明的了一级缓存的存在,以及使用的过程中是如何清空的,但是作为一名合格的架构师,当然不能停留在知道,会用的层面,凡事都要问个究竟那接下来我们就一起探寻源码,看看一级缓存是咱么实现的,又是怎么清除的
咱么按照第二次的测试,先去查询,在执行update操作,然后再去查询的步骤,来探寻源码的执行
在这里我直接找到缓存的执行的逻辑,不在去看其他的执行细节,因为之前源码分析的环节,已经分析过详细的执行流程
执行查询
第一次
在执行openSession的时候,会创建Executor对象,根据执行器的类型ExecutorType选择的是SIMPLE类型,
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
// 创建简单执行器
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
// 创建缓存执行器
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
然后创建的SimpleExecutor对象,在这个对象创建的过程中,是调用的父类BaseExecutor对象,在父类实例化的过程中,创建PerpetualCache缓存对象
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
// 延迟加载
this.deferredLoads = new ConcurrentLinkedQueue<>();
// 创建本地缓存,即一级缓存
this.localCache = new PerpetualCache("LocalCache");
// 处理存储过程缓存,这里不讨论存储过程
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
this.wrapper = this;
}
紧接着又创建了CachingExecutor对象,进到这个对象中,这里是处理二级缓存的地方装饰器对象,在执行的查询的时候,MyBatis会先去二级缓存中去查找
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
//Cache是从MappedStatement中获取到的,而MappedStatement又和每一个<insert>、<delete>、<update>、<select>绑定并在MyBatis启动的时候存入Configuration中:
Cache cache = ms.getCache();
if(cache != null) {
this.flushCacheIfRequired(ms);
if(ms.isUseCache() && resultHandler == null) {
this.ensureNoOutParams(ms, parameterObject, boundSql);/
List list = (List)this.tcm.getObject(cache, key);
if(list == null) {
list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
this.tcm.putObject(cache, key, list);
}
return list;
}
}
//先读取二级缓存,再去查询
return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
接下来的查询从一级缓存中查找,测试的是第一次查询,一级缓存中是没有数据
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 删除不必要代码。。。。
List<E> list;
try {
queryStack++;
// 去本地缓存中查询,这次是第一次查询,缓存中没有返回空
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
// 延迟加载
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
到这里一级缓存没有,就要去数据库中查询了
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 设置缓存占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 去数据库查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 把查询结果放入一级缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
// 返回结果
return list;
}
到这里第一查询就完成了,主要是去数据库中查询中结果,并且放入数据库中
更新数据
刚才的测试结果中,我看到更新数据会清空缓存这里我们主要看下在执行更新的时候,是怎么清空缓存的
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空一级缓存(本地缓存)
clearLocalCache();
// 执行更新操作
return doUpdate(ms, parameter);
}
在执行更新操作前 ,会先清空一级缓存,所以到这里我们就能才到,在第二次执行的时候,缓存中已经没有数据了,所以会在此执行和第一次一样的逻辑,继续从数据库中查找,所以在控制台我们看到会再一次的发送sql语句。其他的删除、新增等操作对对缓存的影响,也是同样的逻辑(因为新增和删除底层都是执行的update()方法),大家可以试着自己去看下
所以,这里第二查询其实和第一查询是一致的。这里就不在源码分析了。
小结
这篇文章主要给大家介绍了MyBatis一级缓存的原理,以及底层代码的实现,这样大家就能从根上理解一级缓存,进一步了解MyBatis持久层框架是怎么处理缓存的,可以对比分析其他持久层框架有没有缓存?缓存是怎么实现的?
· 进阶提升:MyBatis二级缓存
前面介绍了一级缓存,了解它的是sqlSession级别的缓存,是默认开启的,我们在使用MyBatis的时候其实就在使用,只是如果我们不去关注sql可能不会注意到它;这篇文章我们就来了解一下另一个MyBatis内提供的缓存-二级缓存,与一级缓存不同的二级缓存是mapper(namespace)级别的缓存,也就是说多个sqlsession对同一个Mapper进行查询操作时是可以共享这个namespace中的缓存数据,但是当我们去当前这个mapper中的进行增、删、改或者commit的时候,同样是会清空缓存的
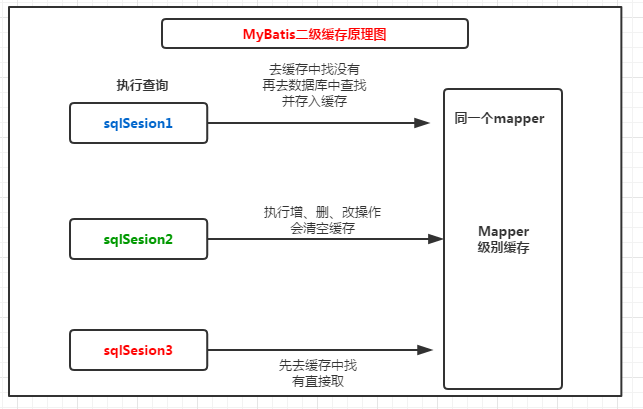
从图中我们可以看出来,sqlSession1在去查询数据的时候都会先去二级缓存中去查,如果没有的话在去数据库中查询,同时会存入到二级缓存中,等sqlsession2再去查询的时候,就可以直接从个缓存中拿了,但是sqlsession3去查询之前sqlsession2去修改了查询的这个数据,那么就会二级缓存就会被清空;这样才不会出现脏数据的情况。
好了接下来我们就去代码中去验证二级缓存存在,然后通过源码的方式来探究它的实现原理
MyBatis的二级缓存是需要手动开启的,这里需要两步配置
-
在核心配置文件中(
mybatis-config.xml)<settings> <!--全局缓存开关,默认开启--> <setting name="cacheEnabled " value="true"/> </settings> -
映射文件中(
UserMapper.xml)<!--开启二级缓存--> <cache/>
测试代码
/**
* 使用二级缓存实体类要实现序列化接口
*
* @throws Exception
*/
@Test
public void testCache2() throws Exception {
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
System.out.println("===============第一次查询===================");
User user = mapper.selectUserById(1);
sqlSession.close();
System.out.println(user);
// 第二次查询
System.out.println("===============第二次查询===================");
SqlSession sqlSession2 = build.openSession();
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
User user2 = mapper2.selectUserById(1);
System.out.println(user2);
System.out.println("===============更新数据===================");
// user.setName("嘿嘿");
// user.setAge(21);
// mapper2.updateUserByUserId(user);
// sqlSession2.commit();
// sqlSession2.close();
// 第三次查询
System.out.println("===============第三次查询==================");
SqlSession sqlSession3 = build.openSession();
UserMapper mapper1 = sqlSession3.getMapper(UserMapper.class);
User user1 = mapper1.selectUserById(1);
System.out.println(user1);
sqlSession3.close();
}
第一次查询
看下测试结果
===============第一次查询===================
Cache Hit Ratio [test.UserMapper]: 0.0
==> Preparing: select * from t_user where id=?;
==> Parameters: 1(Integer)
<== Columns: id, name, age
<== Row: 1, 哈哈1, 12
<== Total: 1
User{id=1, username='null', age=12}
===============第二次查询===================
Cache Hit Ratio [test.UserMapper]: 0.5
User{id=1, username='null', age=12}
===============更新数据===================
===============第三次查询==================
Cache Hit Ratio [test.UserMapper]: 0.6666666666666666
User{id=1, username='null', age=12}
第一次查询的时候,出现了Cache Hit Ratio [test.UserMapper]: 0.0这个表示命中率的意思,0.0说明是缓存没有命中,并且发送了一条sql查询语句;第二查询的时候命中率是0.5说明两次查询命中了一次, 50%的命中率,更新操作被注释没有执行,第三次在此查询命中率是0,66666666说明是三次查询命中了2次,命中率约是66%,第二次和第三次查询都没有发送sql语句;说明二级缓存是存在并且生效的。
接着我们打开更新操作
===============第一次查询===================
==> Preparing: select * from t_user where id=?;
==> Parameters: 1(Integer)
<== Columns: id, name, age
<== Row: 1, 哈哈1, 12
<== Total: 1
User{id=1, username='null', age=12}
===============第二次查询===================
Cache Hit Ratio [test.UserMapper]: 0.5
User{id=1, username='null', age=12}
===============更新数据===================
==> Preparing: update t_user set name=?,age=? where id=?
==> Parameters: 嘿嘿(String), 21(Integer), 1(Integer)
<== Updates: 1
===============第三次查询==================
Cache Hit Ratio [test.UserMapper]: 0.3333333333333333
==> Preparing: select * from t_user where id=?;
==> Parameters: 1(Integer)
<== Columns: id, name, age
<== Row: 1, 嘿嘿, 21
<== Total: 1
User{id=1, username='嘿嘿', age=21}
从结果中我们可以看出,前两次查询和上次是一样的,命中率是0.5,执行更新操作之后,命中率变成了0.33,而且有发送了一条sql语句,说明三次查询中命中了1次,结果看清了,但是背后到底是怎么一回事儿,我们还的好好掰扯掰扯
源码探秘
接下来就是源码环节
在mybatis开始解析映射文件的时候,会解析我们配置的<cache/>标签,并把标签中的 相关属性保存到Configuration对象中,创建的执行器的时候会判断全局缓存开关,创建本地缓存开关
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 批处理
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
// 重用执行器
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
// 简单执行器
executor = new SimpleExecutor(this, transaction);
}
// 判断是否开启全局配置缓存默认开启,
if (cacheEnabled) {
// CachingExecutor是对SimpleExecutor类的装饰器类,给其加上二级缓存的功能
executor = new CachingExecutor(executor);
}
// 拦截器链
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
第一次查询我们就不再说了,前面已经说了很多次了,咱么直接进入第二次查询,跟着断点走,在查询方法前会有创建缓存key的方法
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 创建缓存CacheKey对象,
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
// 返回创建的cacheKey
return cacheKey;
}
最终经过以上多个参数的设置拼接成一个很长的cacheKey

后需在查询的时候直接先去二级缓存查
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取缓存对象
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从缓存中取
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 如果二级缓存没有的话,回去进到这个查询方法中去一级缓存中找
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 同时放到tcm事务缓存对象中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
这次就直接从存储到的存储到二级缓存中直接查找,找到之后返回
这里是从事务对象tcm中查找,而这里的事务缓存也是经过层层委托的对象
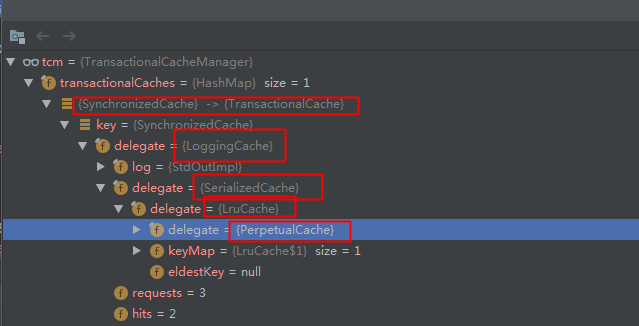
执行更新操作
跟着断点走,进到updata方法
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
// 必要的时候刷新缓存
flushCacheIfRequired(ms);
// 执行更新操作
return delegate.update(ms, parameterObject);
}
进到上面刷新的方法,会看到
public void clear() {
// 将这个commit时清空设置成了true
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
继续跟着断点走的话,会发现在update()方法中只有清空一级缓存的缓存的方法,而真正清空缓存的方法是在commit方法中,所以二级缓存的使用一定注意提交事务,上面咱么说了他是委托了tcm对象管理管理缓存的
到这里基本二级缓存的内容就介绍完了,第三次查询和已经是清空缓存之后的查询,所以查询过程和第一次是一样的,这里就不再赘述
还有一点就是在解析完成<cache/>标签之后,紧接着会解析<cache-ref=“namespace2”/>标签,这个标签就是引用其他的mapper的缓存的,也就是可以多个mapper共用一个mapper内的缓存;但是这里有一问题就是,通常情况下,我们的查询都是涉及多张表的,所以这里就很可能出现脏数据的情况,所以这里通常不引用其他mapper,如果要集成其他第三方缓存或者自定义缓存的时候,可以使用。
这里给大家提示一下的是MyBatis的缓存是和整个应用运行在同一个JVM中的,共享同一块堆内存,所以如果要缓存的数据量很大的话,建议是用其他的缓存框架,如:Reids、Memcache
本文来自慕课网 java架构师 课程 笔记















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









