







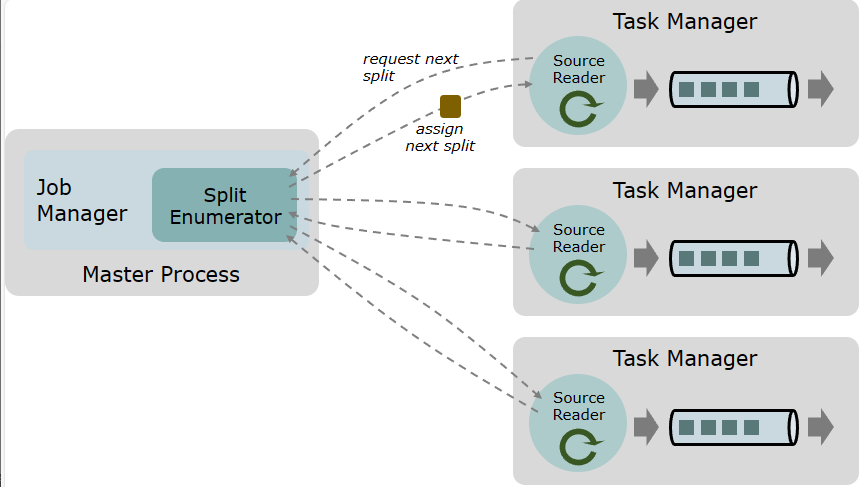
核心组件
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
分片(Split)
是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
源阅读器(SourceReader)
会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的 SourceOperators 并行运行,并产生并行的事件流/记录流。
分片枚举器(SplitEnumerator)
会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
Source 类作为API入口,将上述三个组件结合在了一起。
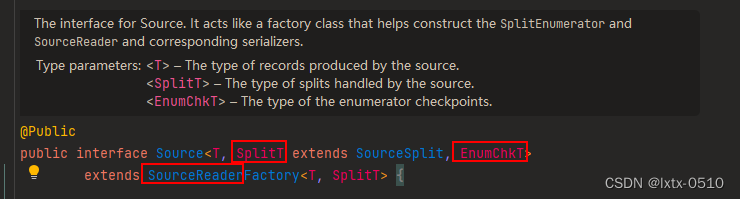
public interface Source<T, SplitT extends SourceSplit, EnumChkT>
extends SourceReaderFactory<T, SplitT> {}
举例:无界 Streaming Kafka Source
- 分片是一个 Kafka Topic Partition。
- SplitEnumerator 会连接到 broker 从而列举出已订阅的 Topics 中的所有 Topic Partitions。枚举器可以重复此操作以检查是否有新的 Topics/Partitions。
- SourceReader 使用 KafkaConsumer 读取所分配的分片(Topic Partition),并使用提供的 解析器 反序列化记录。由于流处理中分片(Topic Partition)大小是无限的,因此 reader 永远无法读取到数据的尾部。
组件详解
SplitEnumerator
SplitEnumerator 被认为是整个 Source 的“大脑”。SplitEnumerator 的典型实现如下:
- SourceReader 的注册处理
- SourceReader 的失败处理
SourceReader 失败时会调用 addSplitsBack() 方法。SplitEnumerator应当收回已经被分配,但尚未被该 SourceReader 确认(acknowledged)的分片。 - SourceEvent 的处理
SourceEvents 是 SplitEnumerator 和 SourceReader 之间来回传递的自定义事件。可以利用此机制来执行复杂的协调任务。 - 分片的发现以及分配
SplitEnumerator 可以将分片分配到 SourceReader 从而响应各种事件,包括发现新的分片,新 SourceReader 的注册,SourceReader 的失败处理等
class MySplitEnumerator implements SplitEnumerator<MySplit, MyCheckpoint> {
private final long DISCOVER_INTERVAL = 60_000L;
/**
* 一种发现分片的方法
*/
private List<MySplit> discoverSplits() {...}
@Override
public void start() {
...
//SplitEnumerator 定期寻找分片并分配给 SourceReader。 使用 SplitEnumeratorContext 类中的 callAsync() 方法。
enumContext.callAsync(this::discoverSplits, splits -> {
Map<Integer, List<MySplit>> assignments = new HashMap<>();
int parallelism = enumContext.currentParallelism();
for (MySplit split : splits) {
int owner = split.splitId().hashCode() % parallelism;
assignments.computeIfAbsent(owner, new ArrayList<>()).add(split);
}
enumContext.assignSplits(new SplitsAssignment<>(assignments));
}, 0L, DISCOVER_INTERVAL);
...
}
...
}
SourceReader
SourceReader 提供了一个拉动式(pull-based)处理接口。Flink 任务会在循环中不断调用 pollNext(ReaderOutput) 轮询来自 SourceReader 的记录。pollNext(ReaderOutput) 方法的返回值指示 SourceReader 的状态。
- MORE_AVAILABLE - SourceReader 有可用的记录。
- NOTHING_AVAILABLE - SourceReader 现在没有可用的记录,但是将来可能会有记录可用。
- END_OF_INPUT - SourceReader 已经处理完所有记录,到达数据的尾部。这意味着 SourceReader 可以终止任务了。
pollNext(ReaderOutput) 会使用 ReaderOutput 作为参数,为了提高性能且在必要情况下,SourceReader 可以在一次 pollNext() 调用中返回多条记录。然而,除非有必要,SourceReader 的实现应该避免在一次 pollNext(ReaderOutput) 的调用中发送多个记录。
SplitReader API
核心的 SourceReader API 是完全异步的, 但实际上,大多数 Sources 都会使用阻塞的操作。为了使其与异步 Source API 兼容,这些阻塞(同步)操作需要在单独的线程中进行,并在之后将数据提交给 reader 的异步线程。
SplitReader 是基于同步读取/轮询的 Source 的高级(high-level)API,例如 file source 和 Kafka source 的实现等。
SplitReader API 只有以下三个方法:
- 阻塞式的提取 fetch() 方法,返回值为 RecordsWithSplitIds 。
- 非阻塞式处理分片变动 handleSplitsChanges() 方法。
- 非阻塞式的唤醒 wakeUp() 方法,用于唤醒阻塞中的提取操作。
SourceReaderBase
SourceReader 处理需求如下:
- 有一个线程池以阻塞的方式从外部系统提取分片。
- 解决内部提取线程与其他方法调用(如 pollNext(ReaderOutput))之间的同步。
- 维护每个分片的水印(watermark)以保证水印对齐。
- 维护每个分片的状态以进行 Checkpoint。
为了减少开发新的 SourceReader 所需的工作,Flink 提供了 SourceReaderBase 类作为 SourceReader 的基本实现。 SourceReaderBase 已经实现了上述需求。要重新编写新的 SourceReader,只需要让 SourceReader 继承 SourceReaderBase,而后完善一些方法并实现 SplitReader 。
public class FixedFetcherSizeSourceReader<E, T, SplitT extends SourceSplit, SplitStateT>
extends SourceReaderBase<E, T, SplitT, SplitStateT> {}
















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











