






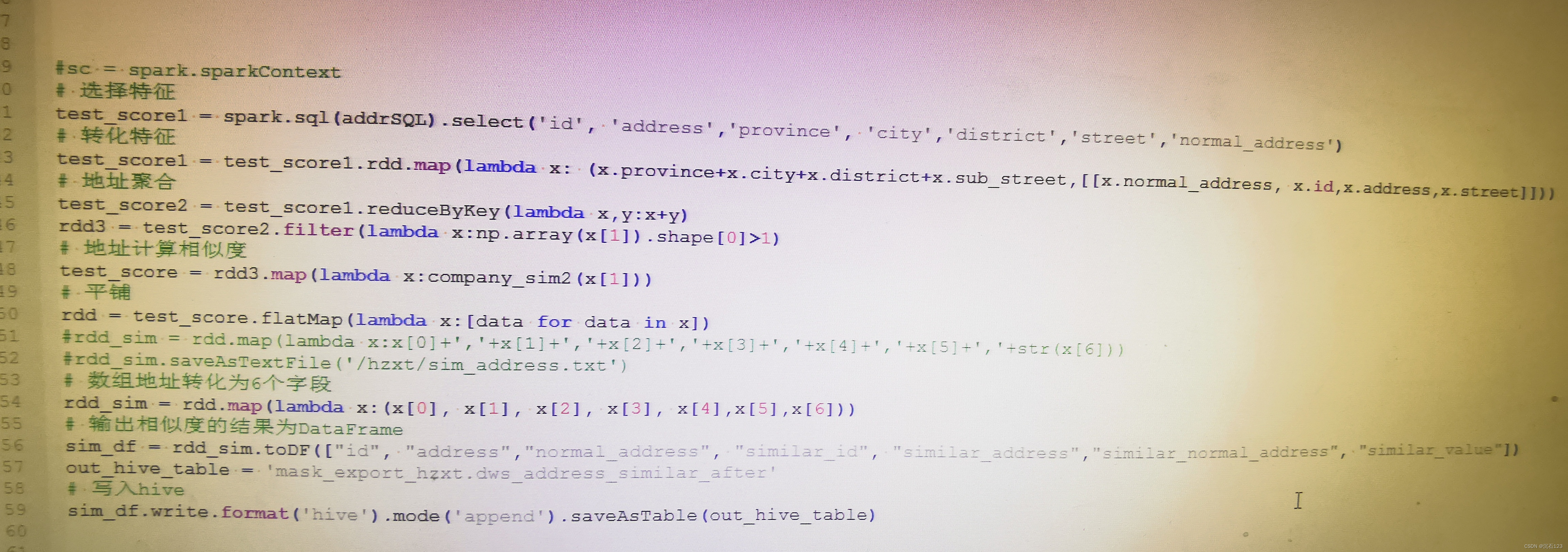
1 把地址分段,省、市、区、县、街道
2 按照省市区县街道reduceBykey
3不同省市区县街道的地址比较计算相似度
4将比较的结果返回值分成多个字段并写入hive
图片部分将 计算相似度的代码没有加进来,读者可自行选取编辑距离、最长公共子串等方式基于业务选取合适的相似度算法。地址分段部分也没有,本文重点在大数据的处理过程,试了多种方式,由于资源不够代码内存溢出,最后调试完最终版如下。















12-13
 1231
1231
1231
02-08
3355
3355
06-04
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









