







DataStream的各类算子
1 Map:DataStream → DataStream
遍历数据流中的每一个元素,产生一个新的元素,可以理解为对集合内数据的清洗操作
@Test
public void mapTest() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//使用lambda,对集合的数值进行乘2操作
DataStream<Integer> dataStream1 = env.fromElements(1,2,4,7);
dataStream1.map((MapFunction<Integer, Integer>) value -> 2 * value).print("lambda");
Tuple2<String, Integer> tuple1 = Tuple2.of("aa", 1);
Tuple2<String, Integer> tuple2 = Tuple2.of("bb", 2);
Tuple2<String, Integer> tuple3 = Tuple2.of("cc", 3);
Tuple2<String, Integer> tuple4 = Tuple2.of("dd", 4);
DataStream<Tuple2<String, Integer>> dataStream2 = env.fromElements(tuple1,tuple2,tuple3,tuple4);
//使用MapFunction,对集合的二元组进行乘2操作
dataStream2.map(new MapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
@Override
public Tuple2 map(Tuple2<String, Integer> value) throws Exception {
return Tuple2.of(value.f0, value.f1*2);
}
}).print("MapFunction");
env.execute("map start");
}

2 flatMap:DataStream → DataStream
遍历数据流中的每一个元素,产生N个元素
@Test
public void flatMapTest() throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//FlatMap
DataStream<String> dataStream1 = env.fromElements("shenzhen,guangzhou,beijing",
"shenzhen,shanghai,beijing","guangzhou,shanghai");
dataStream1.flatMap(new FlatMapFunction<String, Object>() {
@Override
public void flatMap(String value, Collector<Object> collector) throws Exception {
String[] words = value.split(",");
for (String word : words) {
collector.collect(word);
}
}
}).print("FlatMapFunction");
env.execute("start---");
}

3 Filter DataStream → DataStream
过滤算子,根据数据流的元素计算出一个boolean类型的值,true代表保留,false代表过滤掉
@Test
public void filterTest() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//map
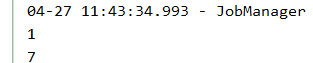
DataStream<Integer> dataStream1 = env.fromElements(1,2,4,7);
dataStream1.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value%2!=0; //去掉偶数
}
}).print();
env.execute("start");
}
4 KeyBy DataStream → KeyedStream
根据数据流中指定的字段来分区,具有相同键的所有记录会分配给同一分区,KeyBy内部是通过hash分区实现的
@Test
public void keybyTest() throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DataStream<String> dataStream = env.fromElements("guangzhou","shenzhen","beijing","shanghai","shenzhen","beijing");
// 通过map方式组成(word,1)行式
SingleOutputStreamOperator<Tuple2<String, Integer>> operator =
dataStream.map(word -> Tuple2.of(word, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
// 通过keyby,进行分组汇总
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = operator.keyBy(0);
keyedStream.sum(1).print();
env.execute("start");
}

5 Reduce KeyedStream:根据key分组 → DataStream
reduce是基于分区后的流对象进行聚合,也就是说,DataStream类型的对象无法调用reduce方法
@Test
public void reduceTest() throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DataStream<String> dataStream = env.fromElements("guangzhou","shenzhen","beijing","shanghai","shenzhen","shenzhen","beijing");
// 通过map方式组成(word,1)行式
SingleOutputStreamOperator<Tuple2<String, Integer>> operator =
dataStream.map(word -> Tuple2.of(word, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
// 通过reduce,进行分组汇总
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = operator.keyBy(0);
DataStream<Tuple2<String, Integer>> reduce = keyedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value, Tuple2<String, Integer> t1) throws Exception {
// f0代表第一个字段,f1代表第二个字段
String key = value.f0;
Integer counts1 = value.f1;
Integer counts2 = t1.f1;
// 将结果合并
return Tuple2.of(key, counts1 + counts2);
}
});
reduce.print();
env.execute("reduce");
}

















 5628
5628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











