






首先创建过滤器类 实现PathFilter接口
package com.xx.dw.utils;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
/**
* 输入路径的文件过滤
* 过滤掉临时文件和正在复制的文件
* @author dylan.wang
*
*/
public class FileFilter implements PathFilter
{
@Override
public boolean accept(Path path) {
String tmpStr = path.getName();
if(tmpStr.contains(".gz.gz"))
{
return false;
}
else
{
return true;
}
}
}
将过滤器添加到spark Scala的 hadoopConfiguration配置中,注意不是spark 的conf配置中,代码如下
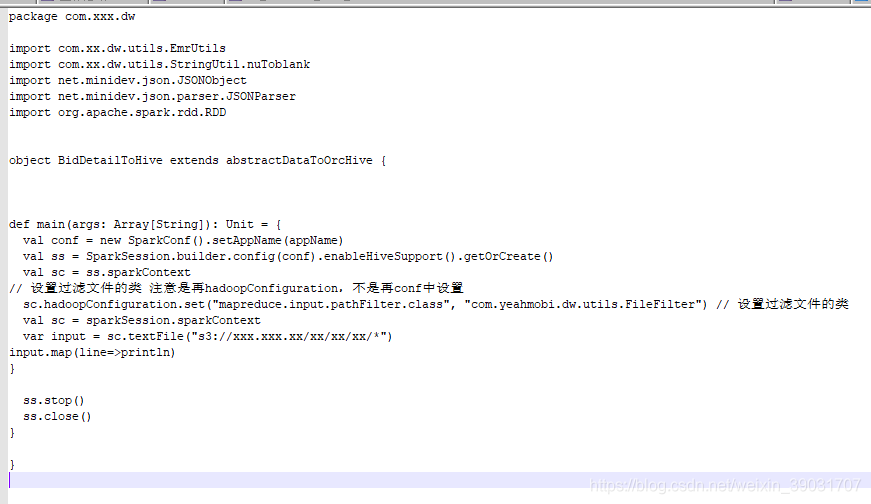
这样就可以把.gz.gz的文件过滤掉不进行处理了














 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









