







首先来介绍下morphline
Morphlines provides a set of frequently-used high-level transformation and I/O commands that can be combined in application specific ways, as described in the Introduction. The following tables provide a short description of each available command and a link to the complete documentation.
更加具体的可以看官网介绍
这次需求跟上次一样只是中间加一层morphline清洗出更多的数据。
测试使用数据请看上一篇的最后部分
- morphline.conf
morphlines: [
{
id: morphline
importCommands : ["org.kitesdk.**"]
commands: [
{
readLine {
charset: UTF-8
}
}
# 解析出字段
{
split {
inputField: message
outputFields: [date, time, soft, version]
separator: " "
isRegex: false
addEmptyStrings: false
trim: true
}
}
{
split {
inputField: soft
outputFields: [mes,plat]
separator: ":"
isRegex: false
addEmptyStrings: false
trim: true
}
}
{
split {
inputField: mes
outputFields: ["",status,name]
separator: ","
isRegex: false
addEmptyStrings: false
trim: true
}
}
# 将时间戳添加到header中,不加会报找不到timestap
{
addValues {
timestamp: "@{date} @{time}"
}
}
# 格式化上面的时间戳
{
convertTimestamp {
field : timestamp
inputFormats : ["yyyy-MM-dd HH:mm:ss"]
outputFormat : unixTimeInMillis
}
}
# 测试使用
{
logInfo {
format : "timestamp: {}, record: {}"
args : ["@{timestamp}", "@{}"]
}
}
# 将数据转成avro格式,自定义schema
{
toAvro {
schemaFile: /home/training/Desktop/flume-kafka/morphline1/softschema.avsc
}
}
# 指定containlessBinary可以去掉schema头,指定编码解码器
{
writeAvroToByteArray {
format : containerlessBinary
codec : snappy
}
}
]
}
]- schema文件
{
"type" : "record",
"name" : "soft",
"fields" : [
{"name":"date","type":"string"},
{"name":"time","type":"string"},
{"name":"status","type":["null","string"]},
{"name":"name","type":"string"},
{"name":"plat","type":["null","string"]},
{"name":"version","type":["string","null"]}
]
}- flume1
agent.sources = r1
agent.channels = c1
agent.sinks = s1
agent.sources.r1.type = spooldir
agent.sources.r1.spoolDir = /home/test12
agent.sources.r1.channels = c1
agent.sources.r1.interceptors=i1 i2
agent.sources.r1.interceptors.i2.type=regex_filter
agent.sources.r1.interceptors.i2.regex=(.*)installed(.*)
agent.sources.r1.interceptors.i1.type=org.apache.flume.sink.solr.morphline.MorphlineInterceptor$Builder
agent.sources.r1.interceptors.i1.morphlineFile=/home/training/Desktop/flume-kafka/morphline1/morphline.conf
agent.sources.r1.interceptors.i1.morphlineId=morphline
# kafka memeory
agent.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
agent.channels.c1.kafka.bootstrap.servers = localhost:9092
agent.channels.c1.kafka.topic = format
agent.channels.c1.kafka.consumer.group.id = format-consumer
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
agent.channels.c1.parseAsFlumeEvent = true- flume2
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# kafka memeory
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = localhost:9092
a1.channels.c1.kafka.topic = format
a1.channels.c1.kafka.consumer.group.id = format-consumer
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.parseAsFlumeEvent = true
# sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /output/format/ds=%Y%m%d
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.fileSuffix = .avro
a1.sinks.k1.hdfs.batchSize = 10
a1.sinks.k1.channel = c1
a1.sinks.k1.serializer = org.apache.flume.sink.hdfs.AvroEventSerializer$Builder
a1.sinks.k1.serializer.compressionCodec = snappy
a1.sinks.k1.serializer.schemaURL = hdfs://localhost:8020/user/schema/softschema.avsc- 成功后hdfs里的文件
*
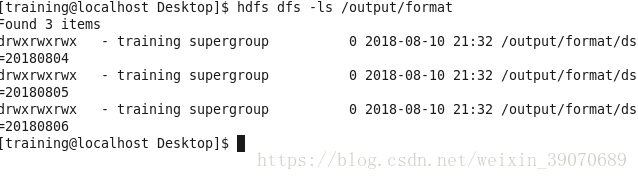
导入到hive表中
- 建立hive外部表,使用hdfs里的schema
CREATE EXTERNAL TABLE format
PARTITIONED BY (ds string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
WITH SERDEPROPERTIES ('avro.schema.url'='hdfs:///user/schema/softschema.avsc')
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/output/format';- 添加数据
alter table format add partition (ds = '20180806')
- 查询结果
select * from format
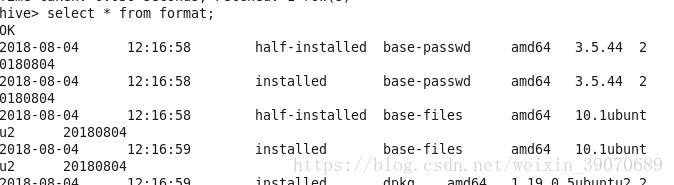
好了教程到这里就结束了,中间可能会碰到一些问题,可以私信我。














 7851
7851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









