







 VPP是一个高性能、模块化的开源数据包处理框架,可在商用CPU上运行,提供生产级别的交换机/路由器功能。该平台支持矢量处理,提高了数据包处理效率,并具备丰富的功能集,包括路由查找、多路径转发等。VPP运行在用户空间,便于调试和扩展,支持多种体系结构和操作系统。
VPP是一个高性能、模块化的开源数据包处理框架,可在商用CPU上运行,提供生产级别的交换机/路由器功能。该平台支持矢量处理,提高了数据包处理效率,并具备丰富的功能集,包括路由查找、多路径转发等。VPP运行在用户空间,便于调试和扩展,支持多种体系结构和操作系统。
- 1 Introduction
- 2 Why is it called vector processing?
- 3 Example Use Case: VPP as a vSwitch/vRouter
- 4 Primary Characteristics Of VPP
- 5 Performance Expectations
1 Introduction
VPP平台是一个可扩展的框架,提供现成的生产质量交换机/路由器功能。它是思科矢量数据包处理(VPP)技术的开源版本:一个高性能的数据包处理堆栈,可以在商品CPU上运行。
VPP的这种实现的好处是其高性能、成熟的技术、模块化和灵活性,以及丰富的功能集。
VPP技术基于久经考验的技术,该技术帮助思科推出了超过10亿美元的产品。这是一种模块化设计。该框架允许任何人“插入”新的图形节点,而无需更改核心/内核代码。

1.1 模块化、灵活且可扩展
VPP平台建立在“数据包处理graph”上。这种模块化方法意味着任何人都可以“插入”新的图形节点。这使得可扩展性变得相当简单,这意味着插件可以针对特定目的进行定制。
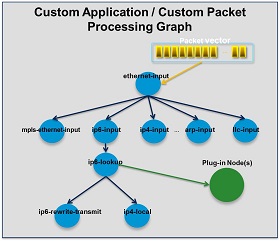
插件是如何发挥作用的?在运行时,VPP平台从RX ring获取所有可用数据包,形成数据包矢量。对整个数据包向量逐节点(包括插件)应用数据包处理graph。图形节点小且模块化。图节点是松散耦合的。这使得引入新的图节点变得容易。它还可以相对容易地重新连接现有的图形节点。
插件可以引入新的graph节点或重新排列数据包处理graph。您还可以独立于VPP源代码树构建插件,这意味着您可以将其视为独立组件。可以通过将插件添加到插件目录来安装插件。
VPP平台可用于构建任何类型的数据包处理应用程序。它可以用作负载平衡器、防火墙、IDS或主机堆栈的基础。您还可以创建应用程序的组合。例如,您可以向vSwitch添加负载平衡。
引擎在纯用户空间中运行。这意味着插件不需要更改核心代码——您可以扩展数据包处理引擎的功能,而无需更改在内核级别运行的代码。通过创建插件,任何人都可以通过以下方式扩展功能:
- 新的自定义图节点
- 图节点的重排
- 新的低级API
1.2 功能丰富
全套graph节点允许构建各种各样的network appliance工作负载。在高层次上,该平台提供:
- 快速查找路由、网桥条目的表项
- 任意n元组分类器
- 现成的生产质量交换机/路由器功能
以下是VPP平台提供的功能摘要:
| IPv4/IPv6 | IPv4 | L2 |
2 为什么叫矢量处理?
顾名思义,VPP使用矢量处理而不是标量处理。标量数据包处理是指一次处理一个数据包。这种较旧的传统方法需要处理一个中断,并遍历调用堆栈(a调用b调用c…从嵌套调用返回…然后从中断返回)。然后,该过程执行以下三项操作之一:punt、丢弃或重写/转发数据包。
传统标量数据包处理的问题是:
- 抖动发生在I-cache中
- 每个数据包都会导致一组相同的I-cache未命中
- 除了提供更大的缓存之外,没有解决上述问题的方法
相比之下,矢量处理一次处理多个数据包。
矢量方法的一个好处是,它修复了I-cache抖动问题。它还缓解了相关读取延迟问题(预取消除了延迟)。
这种方法修复了与堆栈地址上的堆栈深度/D-cache未命中相关的问题。它改善了“circuit 时间”。“circuit”是从设备RX ring循环捕获所有可用数据包,形成一个“帧”(矢量),该帧由按RX顺序的packet索引组成,通过节点的有向graph 运行packets ,然后返回到RX ring。随着持续处理数据包,circuit 时间根据提供的负载达到稳定平衡。
随着矢量大小的增加,每个数据包的处理成本降低,因为您将I-cache未命中分摊到更大的N。
3 示例用例:VPP作为vSwitch/vRouter
VPP平台的一个用例是将其实现为虚拟交换机或路由器。以下部分介绍了可以使用VPP平台创建的可能实现的示例。有关其他可能用例的更深入描述,请参见用例列表。
您可以使用VPP平台创建现成的虚拟交换机(vSwitch)和虚拟路由器(vRouter)。VPP平台允许您通过命令行界面(CLI)管理这些应用程序的某些功能和配置。
交换应用程序可以创建的一些功能包括:
- 桥接域
- 端口(包括隧道端口)
- 将端口连接到网桥域
- 程序ARP termination
路由应用程序可以创建的一些功能包括:
- Virtual Routing and Forwarding (VRF) tables (in the thousands)
- Routes (in the millions)
3.1 本地可编程性
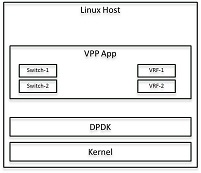
一种方法是实现VPP应用程序,以便在本地环境(Linux主机或容器)中与外部应用程序通信。通信将通过低级API进行。这种方法提供了一个完整的、功能丰富的解决方案,它既简单又高性能。例如,预期性能产出率为每秒500kroutes/second是合理的。
这种方法利用了共享内存/消息队列。该实现是在盒子或容器上的本地计算机上实现的。所有CLI任务都可以通过API调用完成。
VPP平台的当前实现为C客户端和Java客户端生成低级绑定。将来可能会为其他编程语言的绑定提供支持。

3.2 远程编程能力
另一种方法是通过高级API使用数据平面管理代理。如图所示,数据平面管理代理可以通过低级API与VPP应用程序(引擎)对话。这可以在一个盒子(或虚拟机或容器)中本地运行。盒子(或容器)将通过某种形式的绑定公开更高级别的API。
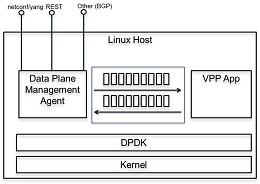
这是一种特别灵活的方法,因为VPP平台不强制特定的数据平面管理代理。此外,VPP平台不限制通信仅限于*一个*高级API。任何人都可以带数据平面管理代理。这允许您将高级API/数据平面管理代理和实现与VPP应用程序的特定需求相匹配。
3.3 数据平面管理代理示例
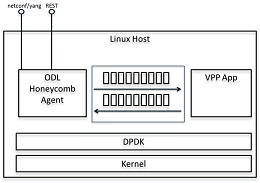
使用high-hevel API的一个例子是将VPP平台作为一个应用程序实现在一个运行本地ODL实例(蜂窝)的盒子上。您可以在生成的Java绑定上使用低级API与VPP应用程序对话,并通过netconf/restconf NB公开模型。
这将是实现桥接域的一种方法。
4 VPP的主要特征
一些主要特征包括:
与在内核中运行类似的数据包处理相比,提高了容错性和ISSU:
- 崩溃通常只需要重启进程
- 软件更新不需要重新启动系统
- 开发环境比类似的内核代码更易于使用和执行调试
- 用户空间调试工具(gdb、valgrind、wireshark)
- 利用广泛可用的内核模块(uio、igb_uio):DMA安全内存
作为Linux用户空间进程运行:
- 相同的映像可以在VM、Linux容器或主机内核上运行
- KVM和ESXi:通过PCI direct map的NIC
- Vhost用户、netmap、virtio paravirtualized NICs
- Tun/tap驱动程序
- DPDK轮询模式设备驱动程序
VPP与DPDK集成,支持现有的NIC设备,包括:
- 英特尔i40e、英特尔ixgbe物理和虚拟功能、英特尔e1000、virtio、vhost用户、Linux TAP
- 惠普更名为英特尔Niantic MAC/PHY
- 思科 VIC
考虑的安全问题:
- 思科安全团队进行了广泛的白盒测试
- 图像段基址随机化
- 共享内存段基址随机化
- 堆栈边界检查
- 调试CLI“chroot”
数据包处理的矢量方法已被证明是主要架构上的主要punt/inject路径。
4.1 支持的体系结构
VPP平台支持:
x86/64
4.2 支持的打包模型
VPP平台支持在以下操作系统上安装软件包:
- Debian
- Ubuntu 16.04
- Centos 7.3
5 性能预期
VPP的这种实现的好处之一是它在相对低功耗计算上的高性能。这种高水平的性能基于以下亮点:
- 用于商用硬件的高性能用户空间网络栈
- 主机、虚拟机和Linux容器的代码相同
- 集成的vhost用户virtio后端可实现高速虚拟机到虚拟机的连接
- L2和L3功能,多重封装
- 利用同类最佳的开源驱动程序技术:DPDK
- 通过使用插件进行扩展
- 通过基于标准的API控制平面/编排平面
5.1 性能指标
VPP平台已被证明提供了以下近似性能指标:
- Multiple MPPS from a single x86_64 core
- >100Gbps full-duplex on a single physical host
- Example of multi-core scaling benchmarks (on UCS-C240 M3, 3.5 gHz, all memory channels forwarded, simple ipv4 forwarding):
- 1 core: 9 MPPS in+out
- 2 cores: 13.4 MPPS in+out
- 4 cores: 20.0 MPPS in+out
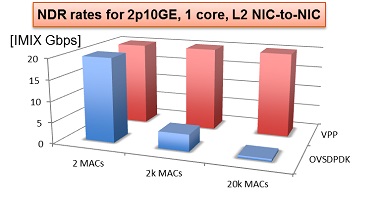
NDR rates for 2p10GE, 1 core, L2 NIC-to_NIC
The following chart shows the NDR rates on: 2p10GE, 1 core, L2 NIC-to_NIC.
NDR rates for 2p10GE, 1 core, L2 NIC-to-VM/VM-to-VM
The following chart shows the NDR rates on: 2p10GE, 1 core, L2 NIC-to-VM/VM-to-VM .
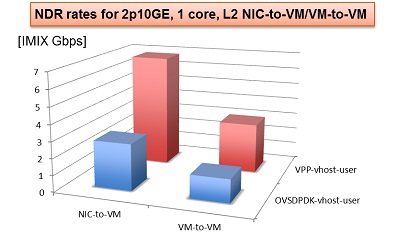
NOTE:
- Virtual network infra benchmark of efficiency
- All tests per connection only, single core
- Potential higher performance with more connections, more cores
- Latest SW: OVSDPDK 2.4.0, VPP 09/2015
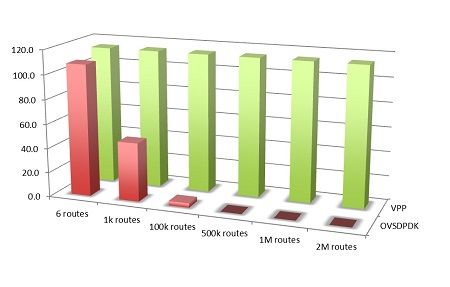
NDR rates VPP versus OVSDPDK
The following chart show VPP performance compared to open-source and commercial reports.
The rates reflect VPP and OVSDPDK performance tested on Haswell x86 platform with E5-2698v3 2x16C 2.3GHz. The graphs shows NDR rates for 12 port 10GE, 16 core, IPv4.

















 2509
2509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









