









 本文旨在讲解RDMA中最基本的元素及其含义。介绍了WQ、WQE、QP、SQ、RQ、SRQ、CQ、CQE等概念,阐述了它们在RDMA通信中的作用和关系,还说明了WR和WC是WQE和CQE在用户层的映射,最后总结了用户态与硬件间的任务流转过程。
本文旨在讲解RDMA中最基本的元素及其含义。介绍了WQ、WQE、QP、SQ、RQ、SRQ、CQ、CQE等概念,阐述了它们在RDMA通信中的作用和关系,还说明了WR和WC是WQE和CQE在用户层的映射,最后总结了用户态与硬件间的任务流转过程。
RDMA技术中经常使用缩略语,很容易让刚接触的人一头雾水,本篇的目的是讲解RDMA中最基本的元素及其含义。
我将常见的缩略语对照表写在前面,阅读的时候如果忘记了可以翻到前面查阅。
WQ
Work Queue简称WQ,是RDMA技术中最重要的概念之一。WQ是一个储存工作请求的队列,为了讲清楚WQ是什么,我们先介绍这个队列中的元素WQE(Work Queue Element,工作队列元素)。
WQE
WQE可以认为是一种“任务说明”,这个工作请求是软件下发给硬件的,这份说明中包含了软件所希望硬件去做的任务以及有关这个任务的详细信息。比如,某一份任务是这样的:“我想把位于地址0x12345678的长度为10字节的数据发送给对面的节点”,硬件接到任务之后,就会通过DMA去内存中取数据,组装数据包,然后发送。
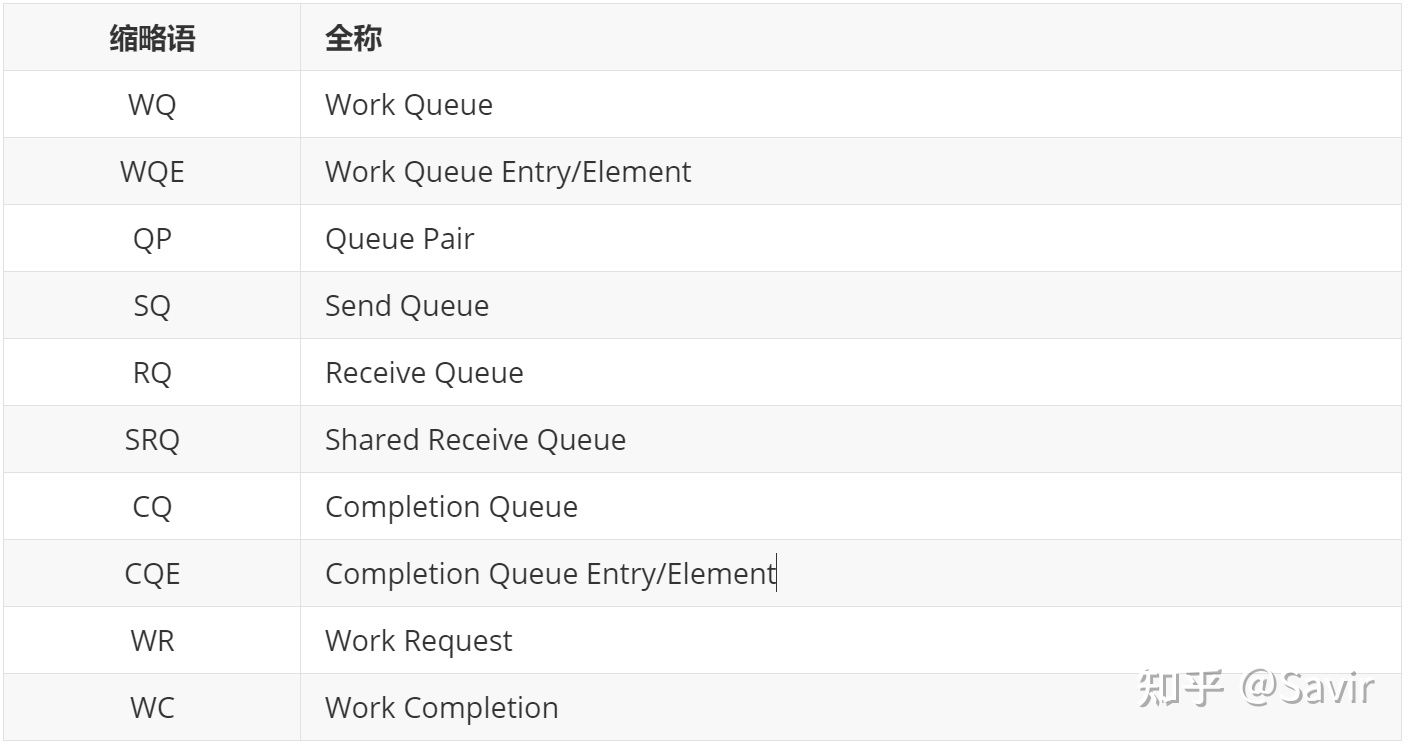
WQE的含义应该比较明确了,那么我们最开始提到的WQ是什么呢?它就是用来存放“任务书”的“文件夹”,WQ里面可以容纳很多WQE。有数据结构基础的读者应该都了解,队列是一种先进先出的数据结构,在计算机系统中非常常见,我们可以用下图表示上文中描述的WQ和WQE的关系:
WQ这个队列总是由软件向其中增加WQE(入队),硬件从中取出WQE,这就是软件给硬件“下发任务”的过程。为什么用队列而不是栈?因为进行“存”和“取“操作的分别是软件和硬件,并且需要保证用户的请求按照顺序被处理,在RDMA技术中,所有的通信请求都要按照上图这种方式告知硬件,这种方式常被称为“Post”。
QP
Queue Pair简称QP,就是“一对”WQ的意思。
SQ和RQ
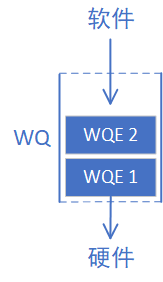
任何通信过程都要有收发两端,QP就是一个发送工作队列和一个接受工作队列的组合,这两个队列分别称为SQ(Send Queue)和RQ(Receive Queue)。我们再把上面的图丰富一下,左边是发送端,右边是接收端:
WQ怎么不见了?SQ和RQ都是WQ,WQ只是表示一种可以存储WQE的单元,SQ和RQ才是实例。
SQ专门用来存放发送任务,RQ专门用来存放接收任务。在一次SEND-RECV流程中,发送端需要把表示一次发送任务的WQE放到SQ里面。同样的,接收端软件需要给硬件下发一个表示接收任务的WQE,这样硬件才知道收到数据之后放到内存中的哪个位置。上文我们提到的Post操作,对于SQ来说称为Post Send,对于RQ来说称为Post Receive。
需要注意的是,在RDMA技术中通信的基本单元是QP,而不是节点。如下图所示,对于每个节点来说,每个进程都可以使用若干个QP,而每个本地QP可以“关联”一个远端的QP。我们用“节点A给节点B发送数据”并不足以完整的描述一次RDMA通信,而应该是类似于“节点A上的QP3给节点C上的QP4发送数据”。

每个节点的每个QP都有一个唯一的编号,称为QPN(Queue Pair Number),通过QPN可以唯一确定一个节点上的QP。
SRQ
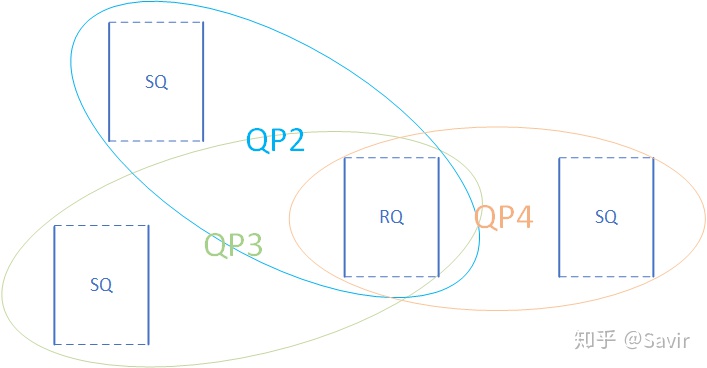
Shared Receive Queue简称SRQ,意为共享接收队列。概念很好理解,就是一种几个QP共享同一个RQ时,我们称其为SRQ。以后我们会了解到,使用RQ的情况要远远小于使用SQ,而每个队列都是要消耗内存资源的。当我们需要使用大量的QP时,可以通过SRQ来节省内存。如下图所示,QP2~QP4一起使用同一个RQ:
CQ
Completion Queue简称CQ,意为完成队列。跟WQ一样,我们先介绍CQ这个队列当中的元素——CQE(Completion Queue Element)。可以认为CQE跟WQE是相反的概念,如果WQE是软件下发给硬件的“任务书”的话,那么CQE就是硬件完成任务之后返回给软件的“任务报告”。CQE中描述了某个任务是被正确无误的执行,还是遇到了错误,如果遇到了错误,那么错误的原因是什么。
而CQ就是承载CQE的容器——一个先进先出的队列。我们把表示WQ和WQE关系的图倒过来画,就得到了CQ和CQE的关系:

每个CQE都包含某个WQE的完成信息,他们的关系如下图所示:
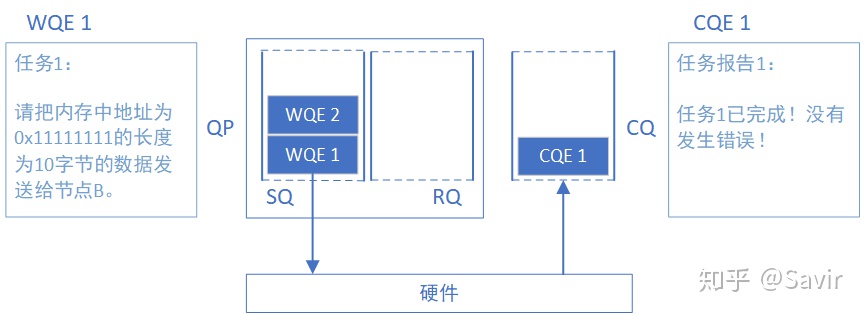
下面我们把CQ和WQ(QP)放在一起,看一下一次SEND-RECV操作中,软硬件的互动(图中序号顺序不表示实际时序):
2022/5/23:下图及后面的列表顺序有修改,将原来第2条的“接收端硬件从RQ中拿到任务书,准备接收数据”移动到“接收端收到数据,进行校验后回复ACK报文给发送端”之后,并且修改了描述,现在为第6条。
这里我犯了错误的点是RQ和SQ不同,是一个“被动接收”的过程,只有收到Send报文(或者带立即数的Write报文)时硬件才会消耗RQ WQE。感谢 的指正。

- 接收端APP以WQE的形式下发一次RECV任务到RQ。
- 发送端APP以WQE的形式下发一次SEND任务到SQ。
- 发送端硬件从SQ中拿到任务书,从内存中拿到待发送数据,组装数据包。
- 发送端网卡将数据包通过物理链路发送给接收端网卡。
- 接收端收到数据,进行校验后回复ACK报文给发送端。
- 接收端硬件从RQ中取出一个任务书(WQE)。
- 接收端硬件将数据放到WQE中指定的位置,然后生成“任务报告”CQE,放置到CQ中。
- 接收端APP取得任务完成信息。
- 发送端网卡收到ACK后,生成CQE,放置到CQ中。
- 发送端APP取得任务完成信息。
NOTE: 需要注意的一点是,上图中的例子是可靠服务类型的交互流程,如果是不可靠服务,那么不会有步骤6的ACK回复,而且步骤9以及之后的步骤会在步骤5之后立即触发。关于服务类型以及可靠与不可靠,我们将在《RDMA基本服务类型》一文中讲解。
至此,通过WQ和CQ这两种媒介,两端软硬件共同完成了一次收发过程。
WR和WC
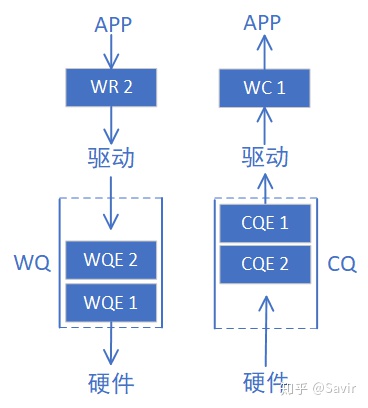
说完了几个Queue之后,其实还有两个文章开头提到的概念没有解释,那就是WR和WC(不是Water Closet的缩写)。
WR全称为Work Request,意为工作请求;WC全称Work Completion,意为工作完成。这两者其实是WQE和CQE在用户层的“映射”。因为APP是通过调用协议栈接口来完成RDMA通信的,WQE和CQE本身并不对用户可见,是驱动中的概念。用户真正通过API下发的是WR,收到的是WC。
WR/WC和WQE/CQE是相同的概念在不同层次的实体,他们都是“任务书”和“任务报告”。于是我们把前文的两个图又加了点内容:
总结
好了,我们用IB协议[1]3.2.1中的Figure 11这张图总结一下本篇文章的内容:
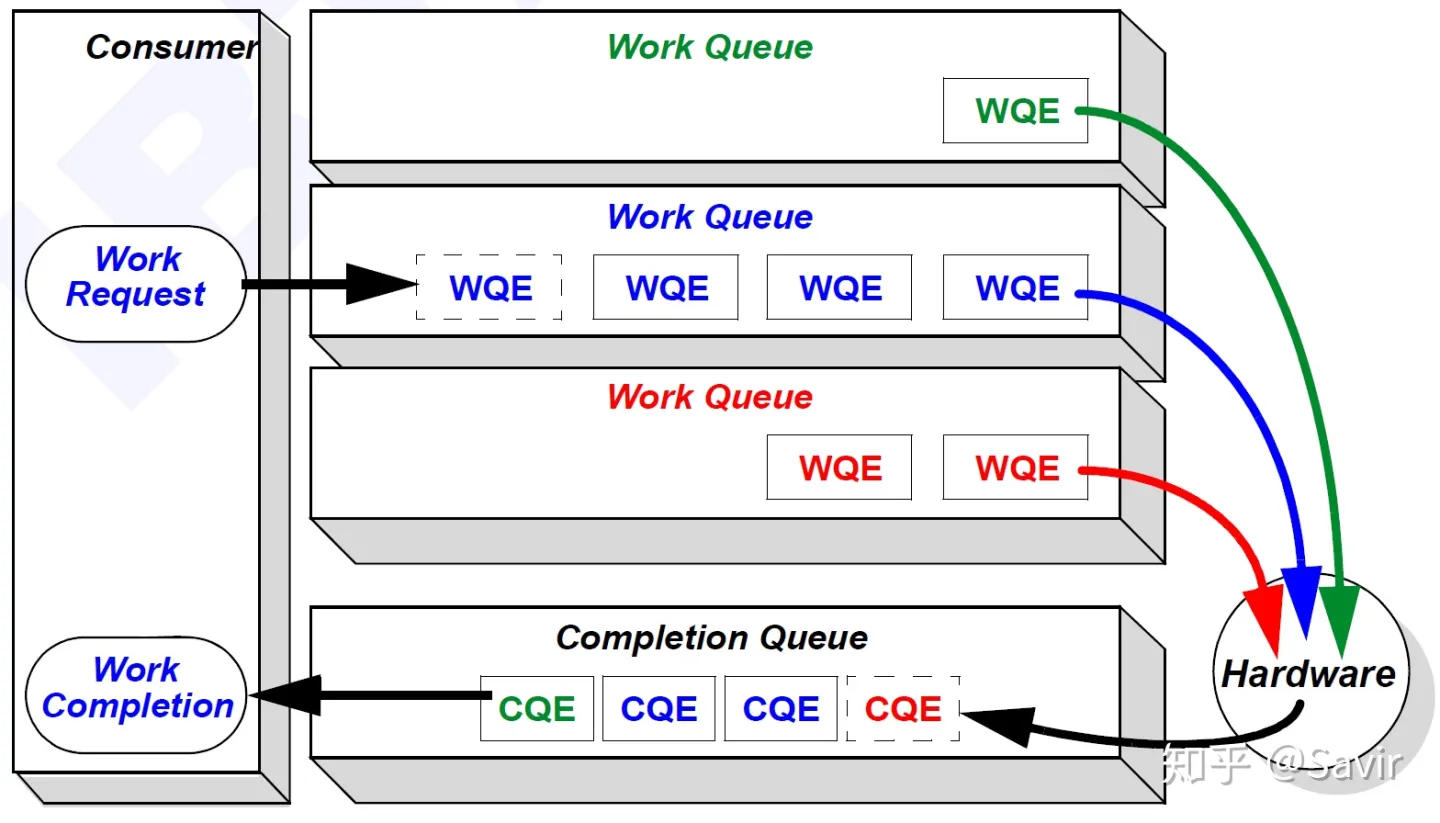
用户态的WR,由驱动转化成了WQE填写到了WQ中,WQ可以是负责发送的SQ,也可以是负责接收的RQ。硬件会从各个WQ中取出WQE,并根据WQE中的要求完成发送或者接收任务。任务完成后,会给这个任务生成一个CQE填写到CQ中。驱动会从CQ中取出CQE,并转换成WC返回给用户。
基础概念就介绍到这里,下一篇将介绍RDMA的几种常见操作类型。

















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









