









转自:https://zhuanlan.zhihu.com/p/565736840
Buffer,即缓冲区,是用来暂存数据、可以重复利用的存储空间;RDMA中的Queue指的是SQ、RQ、CQ或者是SRQ等等这些队列,其中储存着软硬件之间的任务信息,即WR(WQE)或者WC(CQE)。而Queue Buffer,即按照队列结构使用的缓冲区,指的就是上面这些队列在内存中的存在形式。
本文中我们将给大家讲解一下Queue Buffer的实现原理和细节。具体包括它是如何申请和管理的、用户下发WR后,硬件是如何在物理内存中找到对应的WQE等内容。
阅读本文前建议读者重温“内存基础知识”一文,了解RDMA领域涉及的内存相关基础知识。另外请大家注意,下文中主要描述的是SQ Buffer,对于RQ、CQ、SRQ等来讲也都是类似的流程。
背景
RDMA中的Queue作为软件和硬件之间传递任务信息的媒介,由一方填写、另一方读取,这个过程是异步的(也就是两端不一定分别在什么时候读写),并且队列应该可以循环利用,因此我们很容易想到应该以循环队列作为其数据结构。因为其在逻辑上是环形,所以软件开发中也经常称其为Ring Buffer:
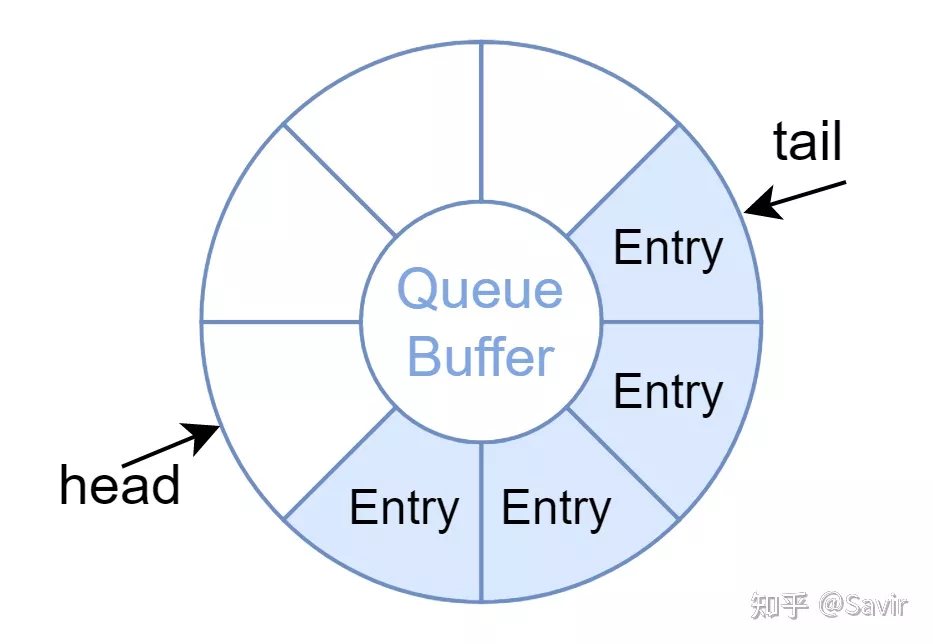
Ring Buffer
上图中的head和tail是软件和硬件维护着的队列的头尾指针,关于它们我们会在以后的文章中详细介绍;Entry指的是队列中有效的元素,比如对于SQ来说是WQE,对于CQ来说是CQE。
然而上文只是一个逻辑上的描述,实际上Queue的物理实体在内存中,内存又是线性的,因此我们不可能实现一个真正的循环结构。循环队列在内存中实际是下图这样排布的,也就是一个连续的Buffer,通过头尾指针的计算,我们可以实现“循环使用”的效果。
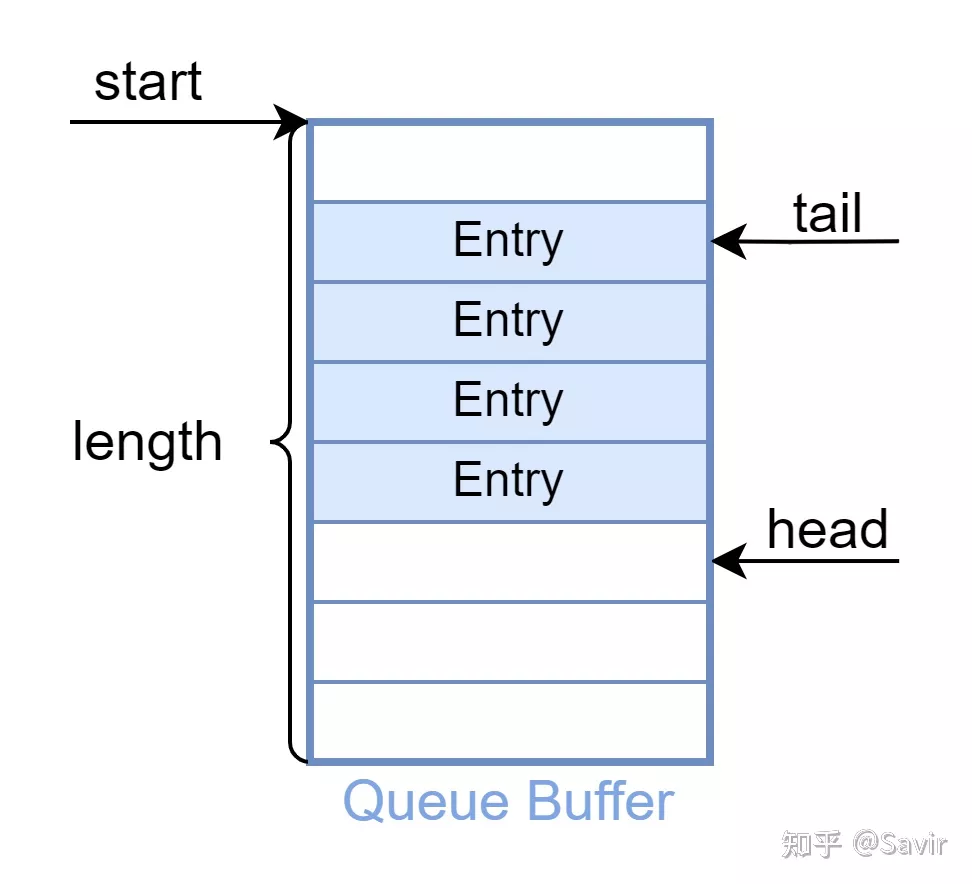
循环队列的实际结构
所以我们应该让软件在内存中申请Buffer给各种Queue使用,然后把这片Buffer的信息(起始地址/长度等)告诉硬件。这里需要注意,Queue Buffer是各个厂商的用户态驱动在Create QP的阶段申请的,而不是用户在自己的应用程序中申请的。Queue Buffer本身对用户不可见,用户在Post Send WR时,用户态驱动程序会把WR转化为WQE,填写到之前申请好的Queue Buffer中。
说到申请Buffer,大家最直观的想法可能就是在用户态RDMA驱动中直接调用malloc/calloc,之后我们会得到指定大小的一片虚拟地址连续的内存空间。最后我们把这个Buffer的起始地址和长度,填写到QP的属性——也就是QPC里面,大功告成!
面临的问题
然而事情并没有这么简单,这里面其实有多个问题:
- 硬件访问内存用的是DMA地址,即IOVA或PA,并不是用户看到的VA,两者不在同一个地址空间。也就是说,硬件不能拿着CPU使用的虚拟地址去访问内存。如下图所示:
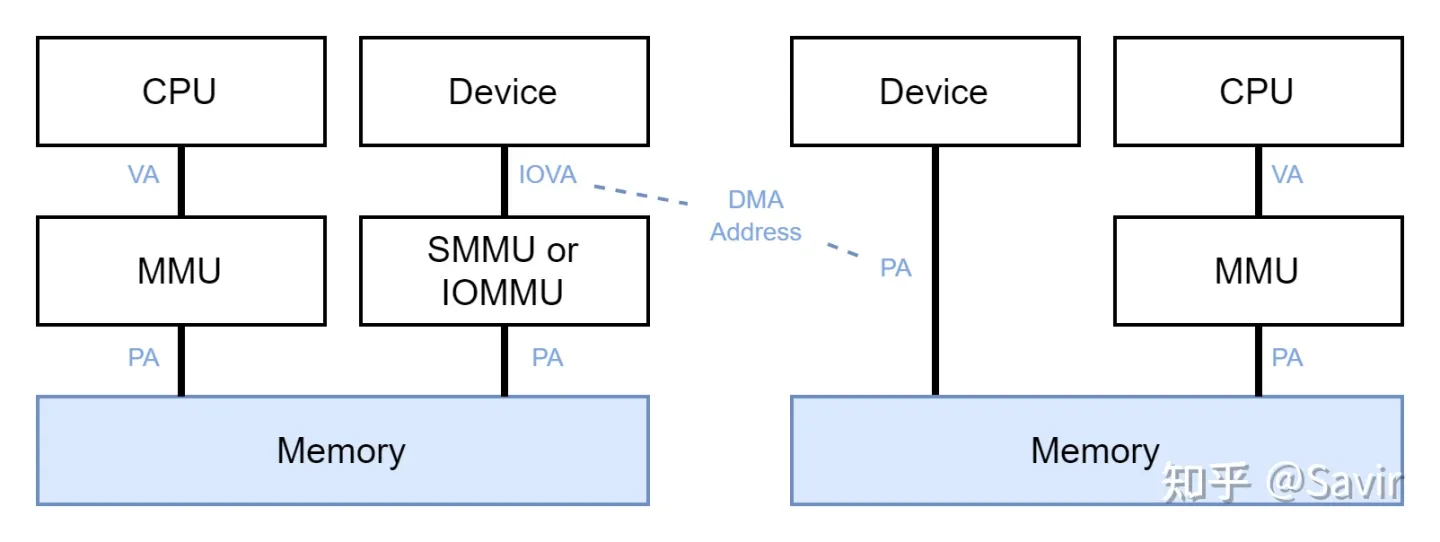
用户(CPU)视角和网卡(硬件)视角的内存
- 操作系统会按照一定的算法定期将暂时不用的物理页的内容拷贝到硬盘中,并将物理页挪作它用。当应用程序再次访问对应的虚拟页时,操作系统将映射新的物理页给它,并从硬盘中拷回内容。 这种机制被称为Swap(换页),一般会在物理内存不够用的时候触发,而触发之后将导致上图的虚拟内存页和物理内存页的关系发生改变。试想一下,网卡中记录的是物理页的地址,但是因为Swap机制的存在,这些物理页随时可能被分给其他应用程序使用,当网卡试图从页面中获取WQE时,里面已经是其他应用程序的用户数据了,这必然会导致问题。
上述过程如下图所示,当App 1的虚拟页从被映射到物理页1变为映射到物理页2时,RDMA网卡中记录的却仍然是物理页1,而网卡根本无从得知操作系统已经进行了换页操作。这个时候当进行DMA操作时,网卡将会访问属于App 2的物理内存。
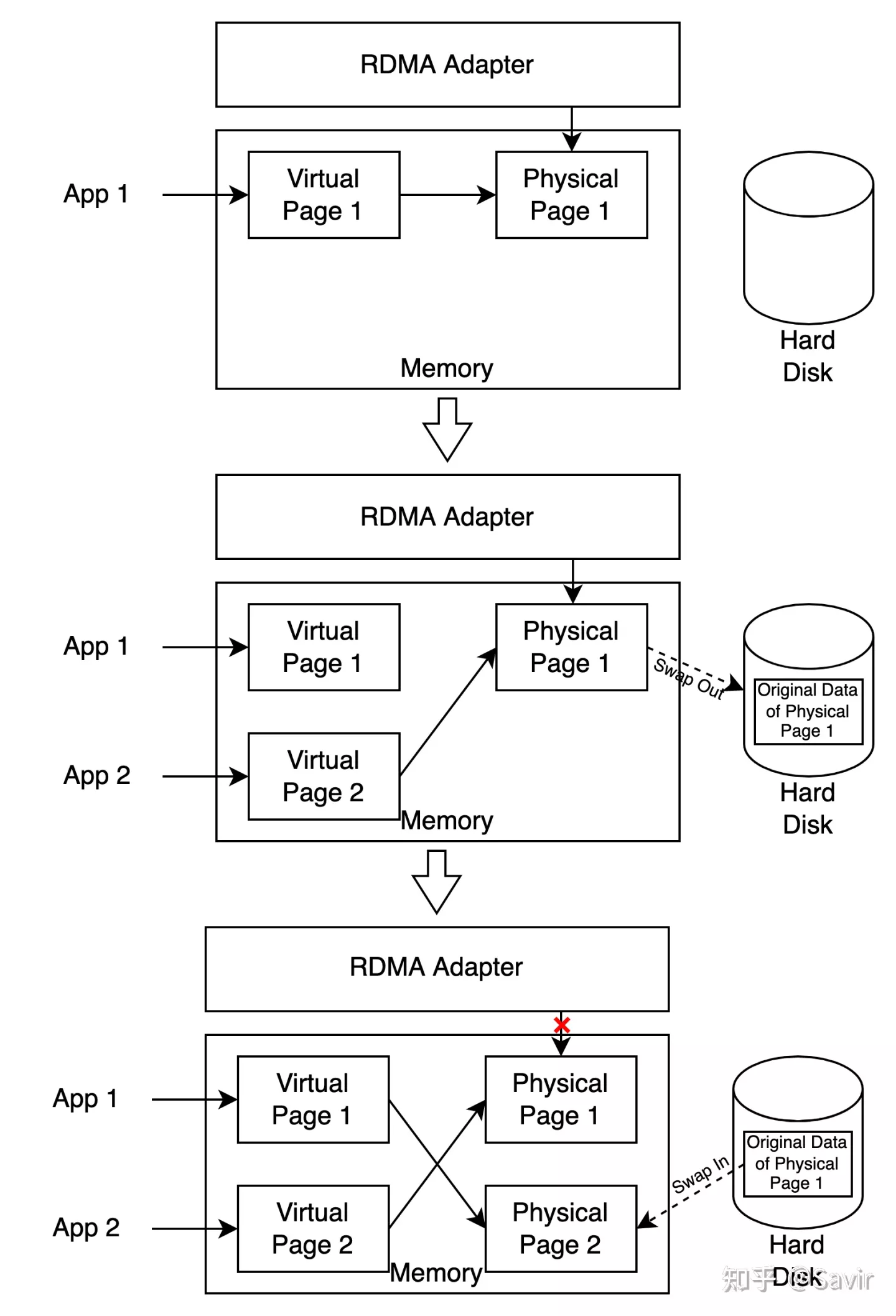
换页机制示意图
- 虚拟地址连续,物理地址不一定连续。这片用户视角看起来连续的Buffer(一般是按照整页申请的),可能对应着很多块离散的物理页。就算我们可以把内存的DMA地址告诉硬件,也要把这些离散的页的地址都告诉硬件。如下图所示:
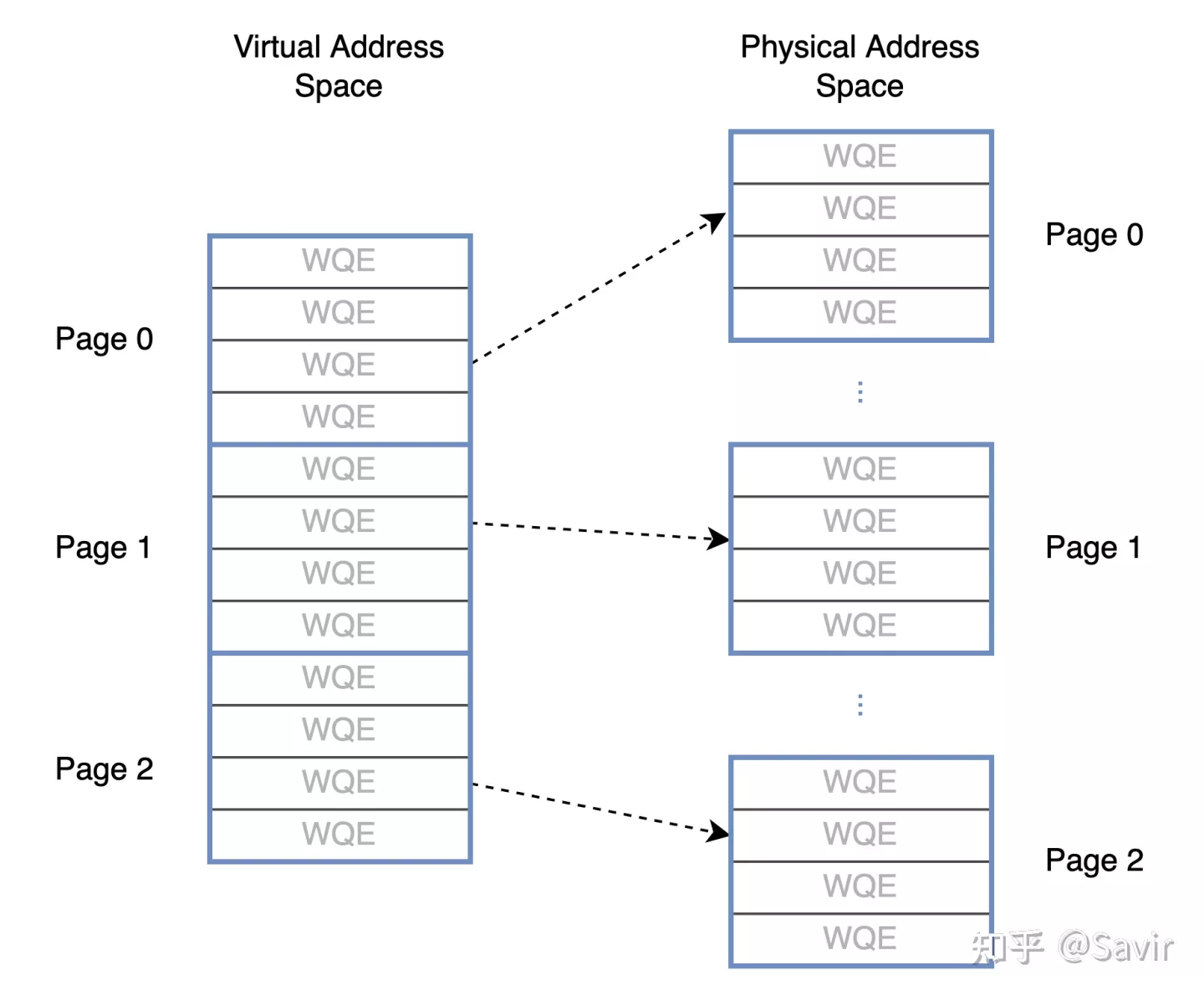
连续的虚拟地址和不连续的物理地址
因为操作系统的权限限制,上述几个问题都没法在用户态的范围内解决,需要陷入内核态由内核驱动程序来处理。这也是Create QP等控制路径的Verbs不得不陷入内核态的原因之一。
读者们可以在这里暂停思考一下,如何解决上述问题?我们需要RDMA设备的内核驱动程序在Queue Buffer的创建过程中做到以下几点:
- 为虚拟页面映射物理页,并固定虚拟页和物理页间的关系。
- 获取物理内存页的DMA地址。
- 以硬件可以识别的方式组织物理内存页的DMA地址。
明确了要解决的问题之后,下面我们一起看一下Queue Buffer的创建流程,看看软件是如何解决上述问题的。
创建流程(控制路径)
用户态
用户调用创建QP的API
用户首先在自己的应用程序中调用Create QP的Verbs API来启动创建QP的流程,除了指定QP的类型之外,还会指定规格,比如SQ和RQ的深度——即每个Queue最大可以容纳的WQE个数。接下来经过rdma-core框架代码简单处理后,流程就会进入到各个厂商的用户态驱动中。
驱动申请Buffer
这一步里除了校验参数之外,最主要的工作就是申请QP的Buffer。QP Buffer分为SQ和RQ,没有特殊说明的话下文中的Buffer都指SQ Buffer,RQ的流程和它是一样的。
驱动程序会根据用户指定的Queue的深度和硬件WQE大小,申请一片虚拟内存。为了驱动程序和硬件都更好处理,各个厂商在这里申请的Buffer通常是页对齐的——即它的起始虚拟地址和大小,都是系统页面大小(以4K和64K Bytes居多)的整数倍。比如系统页大小是4K,那么申请到的Buffer的首地址可能是0xABCDABCDABCDA000,即后12bit一定是0。
malloc/calloc申请的Buffer无法保证页对齐,因此这里会使用mmap或其他支持页对齐的内存申请接口。
如果页对齐之后的Buffer大小比用户所需要的大怎么办呢?驱动会返回页对齐之后的QP深度给用户,这一点在IB规范中有提到,即创建资源时Verbs返回的规格可以大于或者等于用户要求的值。
用户态申请完虚拟内存,以及做一些其他软件资源的初始化之后,将通过软件框架封装的系统调用接口陷入内核态。
内核态
- 获取Buffer的信息
在RDMA用户态驱动通过系统调用陷入到内核态时,会传递Buffer大小相关的信息以及起始虚拟地址,内核驱动会暂时记录这两个信息用于稍后使用。
接下来,内核驱动会调用操作系统提供的功能来实现我们前文提到的需要做到的前两点:
- 为虚拟页面映射物理页,并固定虚拟页和物理页间的关系
因为操作系统内核管理着内存,所以通过系统提供的函数我们很容易就可以获取到没有被使用的物理内存页;另外内核提供了Pin机制,Pin有“把…用图钉钉住”的意思,是一个很形象的名字,用来固定虚拟页和物理页之间的关系,即防止换页。
通过一个循环,我们就可以把在用户空间申请的Queue Buffer的每个虚拟内存页都分别Pin到一个物理内存页上。
- 获取物理页的DMA地址
系统提供了DMA地址映射接口,来获取物理内存页的DMA地址。如果系统支持IOMMU/SMMU,那么这里获取到的是IOVA,如果不支持,得到的就是PA。无论如何,这里都得到了可以供RDMA网卡直接访问的、QP Buffer的物理页面的DMA地址。
上述两个流程被内核中RDMA子系统的框架封装成了一个公共函数——ib_umem_get(),所有操作得到的结果也被储存到一个叫做ib_umem(即Infiniband Userspace Memory)的结构体中,该结构体专门用来描述用户Buffer的信息。
ib_umem中包括了用户Buffer的长度、起始虚拟地址、访问权限、关联的IB设备、内存信息、以及刚刚获取到的一组地址离散的Buffer组成的列表等等。
我们最关心的便是最后这个列表,这个列表中每个元素的数据结构在内核中被称为scatterlist,一般翻译为散列表。这个名字有的读者可能会觉得比较陌生,其实它就是一个用来描述内存块的数据结构。如下图所示:
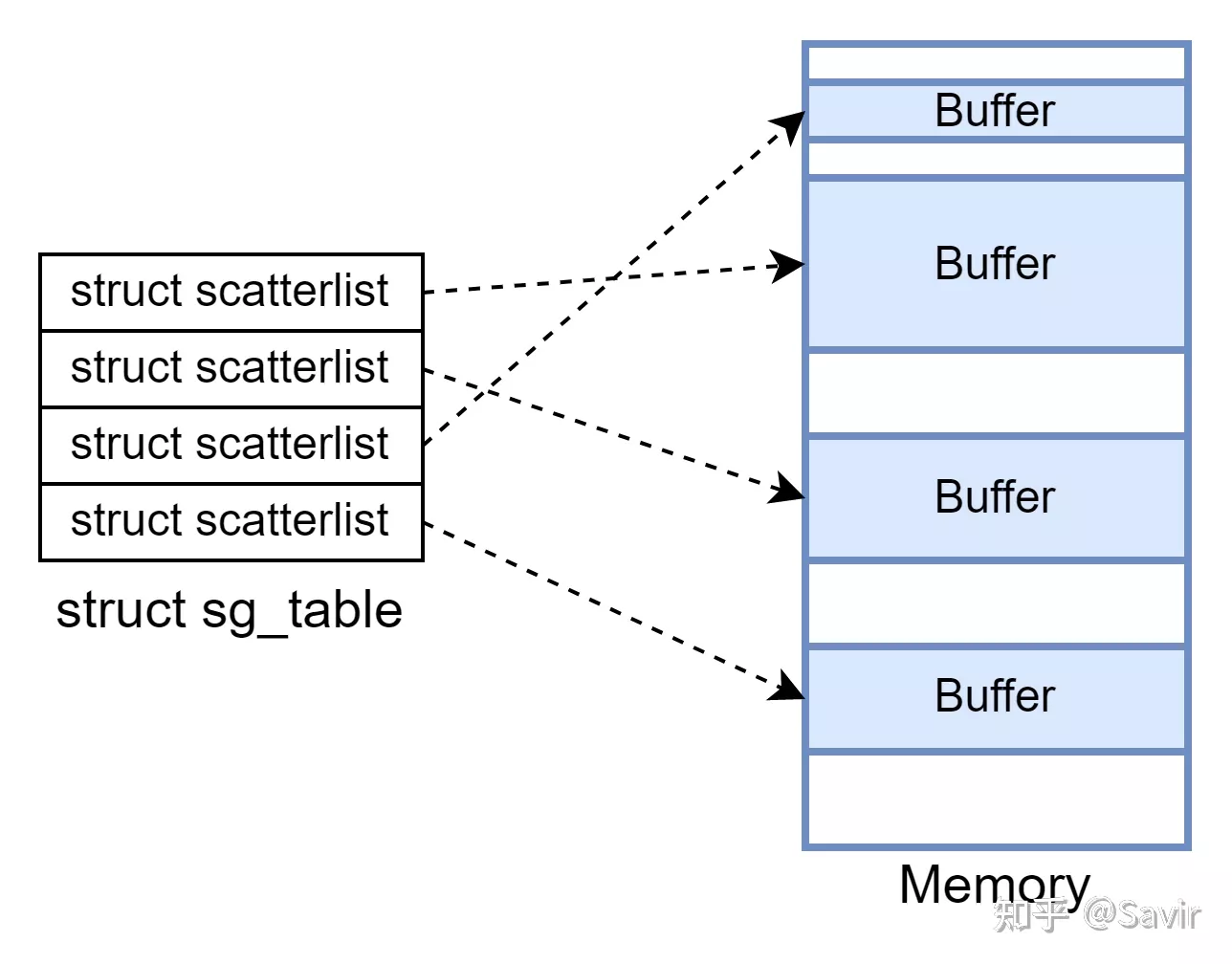
scatterlist和物理Buffer的关系
每个scatterlist结构中,都存放了其指向的Buffer的虚拟地址、长度、DMA地址、所在的物理页以及页内偏移等信息。多个scatterlist放在一起,就可以描述一组离散的Buffer了,内核里也有专门的数据结构——Scatter Gather Table,实在不知道怎么翻译成中文才好,所以我们还是用SG Table来称呼它吧。
这里需要注意一点,ib_umem_get()产生SG Table的过程中,会对相邻的物理页面做合并操作:比如相邻三个4K的物理页,会被视为一个12K的scatterlist元素。所以这里产生的SG Table,不是物理“Page”的集合,而是物理“Buffer”的集合。
ib_umem使用SG Table来描述虚拟地址连续、物理地址离散的Buffer,稍后各个厂商的驱动程序将把ib_umem转换为RDMA网卡可以访问的形式。
- 以硬件可以识别的方式组织物理内存页的DMA地址
现在我们拥有了一个离散物理Buffer的集合,剩下工作就是把这些Buffer传递给RDMA网卡了。
大家首先可能会想到,直接把SG Table的DMA首地址告诉硬件不就可以了吗?这是不行的。因为SG Table是一个CPU视角的数据结构,操作系统内核也是通过VA来访问和管理这个数组的,其本身的物理地址未必连续,因此没法直接给RDMA网卡使用。
所以这里需要驱动程序另外申请一片物理地址连续的Buffer,用来拷贝SG Table中物理Buffer的首地址和长度等信息,最后将这个新申请的用于存放Buffer信息的DMA首地址填入到QPC中。如此一来就形成了一个类似于操作系统页表的结构——硬件就可以访问所有离散的物理Buffer了。
这里可能有点绕,附个示意图,图中左侧是上文提到的几种结构的逻辑关系,右侧是可能的物理内存排布(注意图里所有的地址都是DMA地址——也就是硬件直接访问内存使用的地址)。
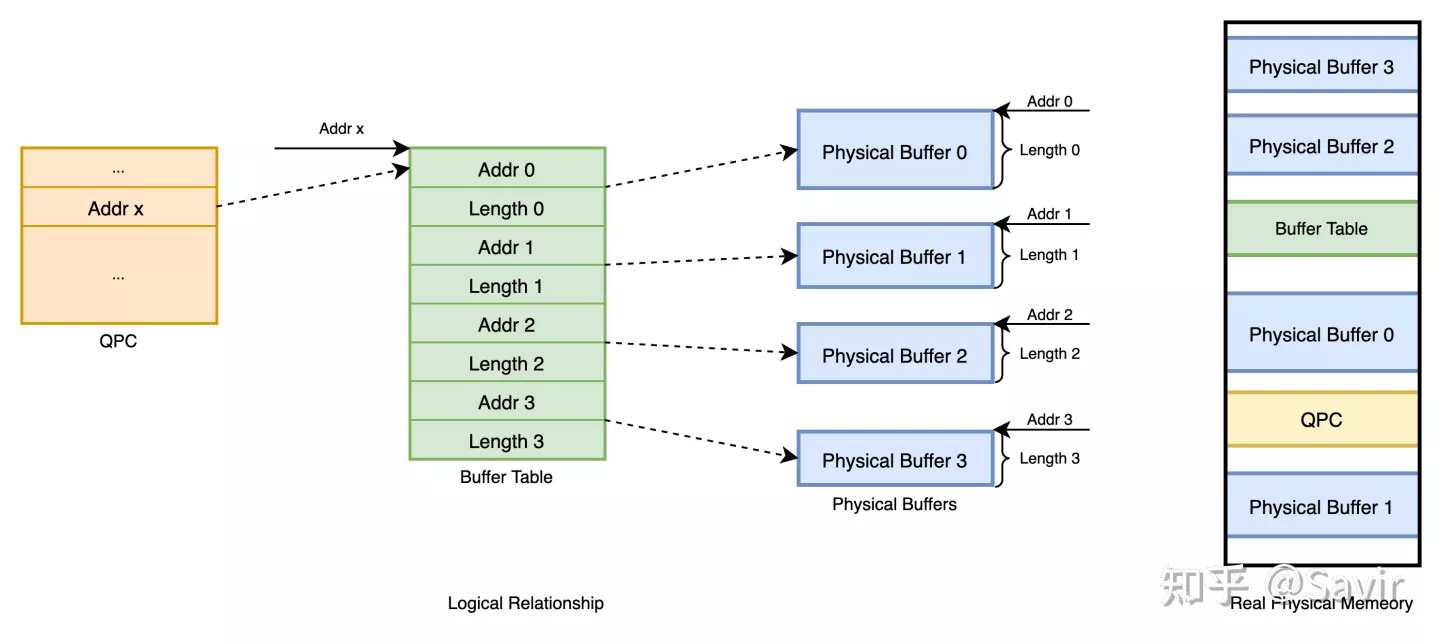
Queue Buffer“页表”的逻辑和物理结构
该过程中各个厂商的实现可能还略微有些差别,比如大多数厂商的硬件只支持同一大小的物理Buffer,那么此时驱动程序就要对ib_umem_get()的得到的SG Table中的元素再进行拆分,拆成同样大小的物理Buffer,比如4K、8K、64K等等。因为所有的物理Buffer大小都一样了,所以Buffer Table里也没必要记录长度了,直接在QPC里面记录一份就可以了。所以上图左侧就变成了这样:
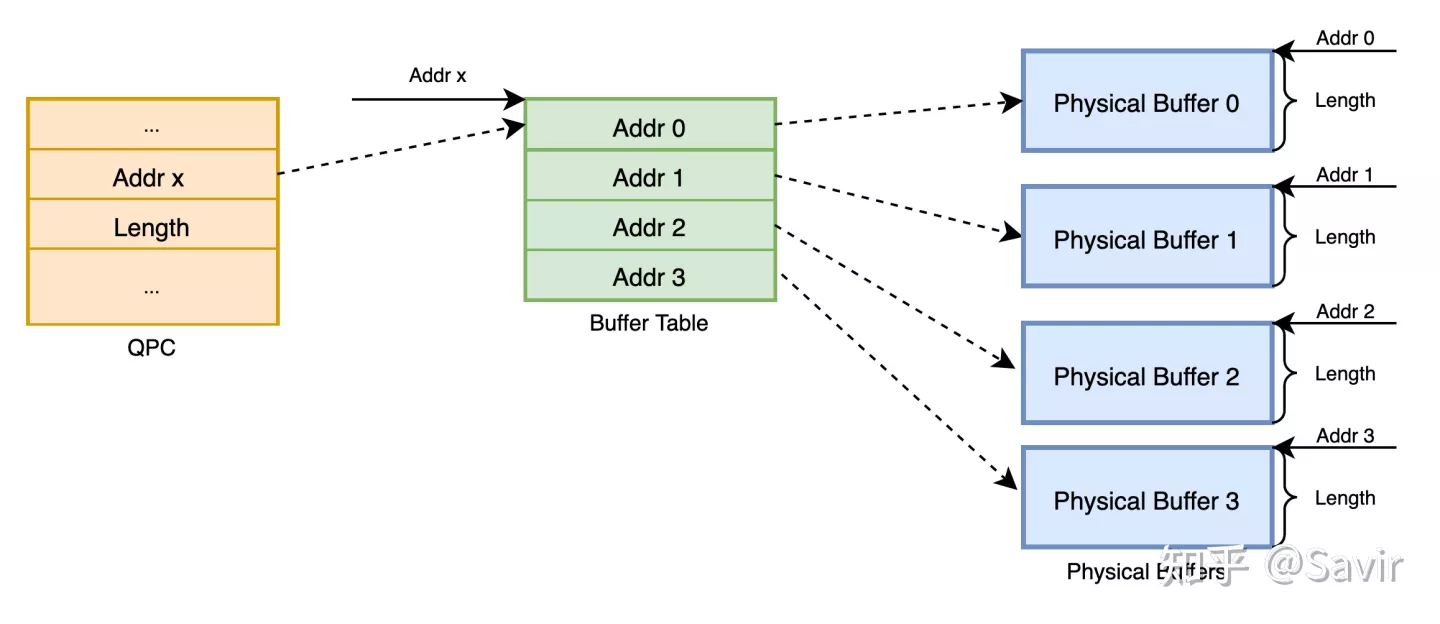
每个物理Buffer大小相同的Queue Buffer
再比如有的RDMA网卡为了支持更大的总大小和更离散的物理Buffer,支持类似于CPU多级页表的结构,也需要驱动程序去配合构建这个结构。上图又可能变成这样:
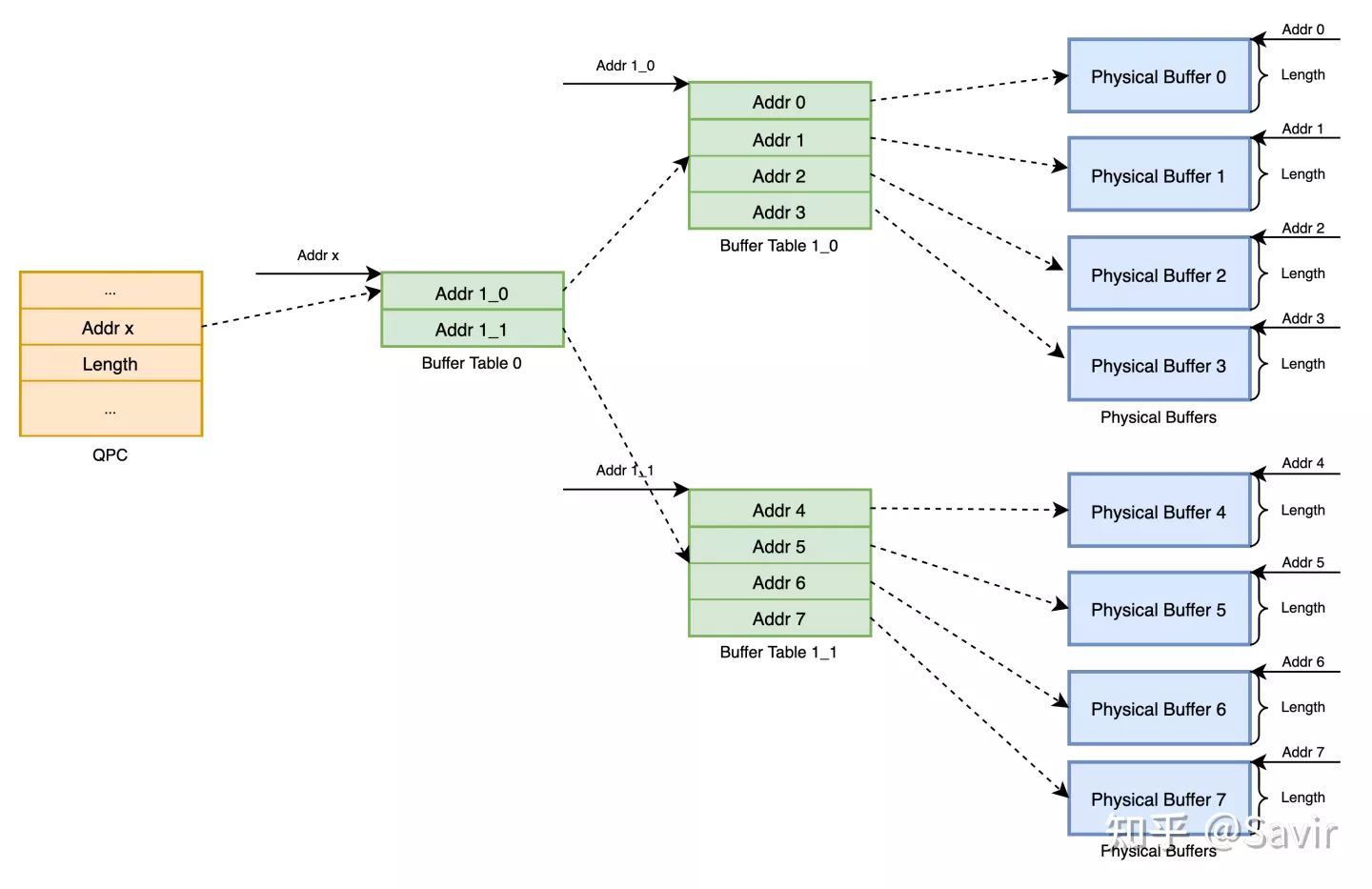
采用多级结构的Queue Buffer
总之,驱动程序只要按照跟硬件约定好的格式组织好物理页就可以了,最后会将这个组织好的数据结构的信息填写到QPC里。
控制路径上的准备工作介绍完了,下面我们以SQ为例讲一下在Queue Buffer的使用流程,即数据路径上用户是如何直接下发WQE,而RDMA网卡又是如何从QP Buffer中获取到WQE的。
使用流程(数据路径)
用户态
- 用户通过API下发WR
用户的应用程序通过rdma-core提供的Verbs接口来Post Send一个WR,WR中包含了要发送给对端的请求的信息,比如操作类型(Send/RDMA Write等)、Payload的虚拟地址、和一些控制信息等等。
用户本身不关心QP Buffer,因为它是由RDMA网卡的用户态驱动管理的。
- 驱动将WR转化为WQE并填入QP Buffer
各厂商的用户态驱动收到用户的WR后,首先要从之前申请好的QP Buffer中找到下一个WQE应该存放的位置,该用哪一个WQE是通过软硬件共同维护的队列的头尾指针得到的。
比如SQ当前头指针是10,表示该讲内容填写到SQ Buffer中第10个WQE所在的位置,这个WQE的地址为:SQ Buffer的起始va + 每个WQE的大小 * 10。
然后驱动程序会按照硬件无关的WR的内容,按照格式配置硬件相关的WQE的内容。
- 驱动敲Doorbell
填写完WQE之后,驱动要想办法通知硬件,而这个通知机制就是Doorbell,我们之前的文章中也有提到过。可以简单理解成一个门铃一样的中断,其中携带了QPN,以及头指针的位置。这样硬件就知道哪个QP下发了一些WQE了。
头尾指针的维护以及Doorbell的细节我们暂且按下不表,以后有专门的文章介绍。
硬件
- 解析Doorbell
硬件收到Doorbell之后,会解析其内容,拿到前文说的QPN和头指针。
- 从QPC中获取QP Buffer信息
为什么Doorbell中要携带QPN呢,硬件需要通过QPN找到对应的QPC。之所以要找QPC,有两个主要原因:首先硬件需要知道新下发的WQE存放在哪里,这需要QP Buffer的信息,而信息储存在QPC里面;另外WQE中并不包含所有发送数据包所需的信息,比如对RC服务类型来说,对端信息(QPN、GID)等是储存在QPC中的。
- 获取并解析WQE
硬件通过上一步从QPC中获取到的QP Buffer的信息(Buffer Table的基地址,每一个物理Buffer的长度等),加上Doorbell中的头指针,就可以算出新下发的WQE的DMA地址。
如此一来,就可以从内存中取出WQE,然后按照跟软件约定好的格式解析其内容了。最后配合QPC中的其他控制信息,就可以组装出一个个完整的数据包并发送出去了。
总结
本文中我们一起学习了QP Buffer的作用、创建和使用流程。最后我们用一张“不太标准”的泳道图来总结全文的流程,梳理下涉及的各个角色和步骤的关系:
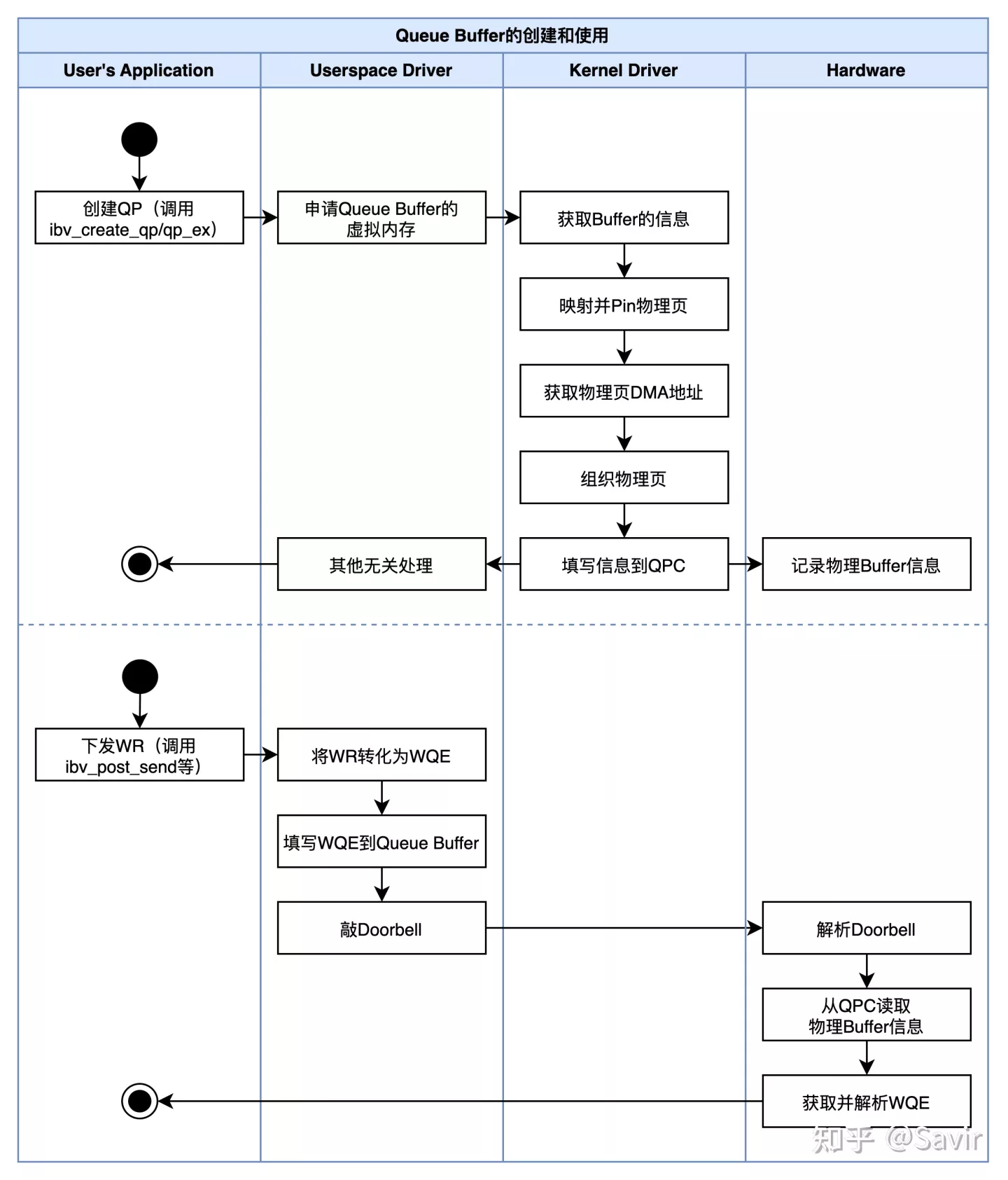
Queue Buffer的创建和使用
好了,就到这里,感谢大家的阅读。文章有遗漏或者读者有疑惑,请在评论区一起讨论。
下期打算给大家讲解MR Buffer的实现原理和细节,它和QP Buffer在申请和使用流程上有诸多相似点,但是有一个明显的差异——QP Buffer是驱动申请而用户不可见的,而MR Buffer却是用户自己申请的。
参考文档
[1] Wowtech Linux kernel scatterlist API介绍 (wowotech.net)

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









