






根据腾讯KM编辑
2025大模型时代生存指南:突破认知迷雾的三大关键拷问
(每个追问都指向一个认知升维的突破口)
1、第一层迷雾:能力认知革命
❓当我们谈论大模型时,究竟在谈论什么?
是聊天机器人?是知识引擎?还是正在觉醒的数字生命体?
它的能力疆域究竟有多广?从代码生成到蛋白质设计,从创意写作到战略推演,边界在哪里?
那些被刻意隐藏的缺陷:幻觉输出、逻辑断层、价值观偏差...我们该如何识别与防范?
2、第二层迷雾:信息筛选博弈
❓在技术迭代速度突破摩尔定律的时代:
如何从每天2.3万篇AI论文、500+个开源项目中,捕捉真正有价值的信息?
当GitHub trending榜每小时刷新,怎样建立个性化的技术雷达系统?
在信息洪流中,如何构建"反脆弱"认知体系,避免成为二手信息的搬运工?
3、第三层迷雾:应用效能跃迁
❓当工具选择过剩成为新困境:
在20+个主流基座大模型、300+个垂直领域LLM工具中,如何制定最优组合策略?
从Prompt Engineering到RAG架构,哪些方法论能真正带来10倍效率提升?
如何将大模型转化为"第二大脑",实现工作流重构与生活方式的智能进化?
这不是一份技术说明书,而是一场认知突围战的路线图
(每个问题背后,都藏着从"被动适应"到"主动驾驭"的进化密码)
大模型:人工智能的认知革命
(重新定义语言理解的维度)
核心本质 我们谈论的"大模型",实则是人类迄今为止构建的最复杂认知映射系统:
参数规模:以千亿级神经元连接模拟人脑语言中枢(如GPT-4参数达1.8万亿)
架构革命:基于Transformer的自注意力机制,实现跨文本的深度关联学习
能力跃迁:从机械式规则脚本(传统聊天机器人)进化到真正的语义理解与创造
能力图谱 传统AI → 大模型 的范式转移:
数据驱动:通过预训练消化整个互联网的知识图谱(Reddit、arXiv、GitHub等)
涌现能力:在代码生成、多轮对话、逻辑推理等任务中展现类人智能 泛化边界:从基础对话扩展到蛋白质设计、数学证明、战略推演等跨领域应用
技术分水岭 大模型与传统NLP的本质区别:
上下文感知:可处理长达128k token的连续语境(相当于一本中篇小说)
零样本学习:无需特定训练即可完成陌生任务(如突然要求用莎士比亚风格写代码注释)
多模态融合:正在突破纯文本界限,向视觉、听觉、动作等多维度智能演进 (这不仅是技术的量变,更是机器认知的质变里程碑)
弊端说明
大模型带给我们的惊艳已经无需多言,这里也特别说明下它还存在哪些主要的弊端

名词解读
再补充解释一些热门名词,帮助侧面理解大模型,以及为下文做出铺垫:
Prompt:Prompt是指向大语言模型提供的输入,用于引导模型生成预期的输出。它可以是一个问题、一段文字、或一个命令,目的是设定上下文或指令,让模型完成某个特定任务。如果我们把LLM当成工作上的助手,好的Prompt会让这位助手更加了解我们的诉求,也才能产生更好的效果。
CoT:Chain of Thought,也就是我们经常提到的“思维链”,它是一种让模型在回答问题的过程中,显式地展示其推理过程的方式。简单来说,它就是让模型“把思路写出来”,或者“边想边说”,从而帮助模型进行更复杂、更准确的推理。
RAG:Retrieval-Augmented Generation是一种结合检索(Retrieval)和生成(Generation)的技术,用于增强语言模型的能力。模型在生成答案前,会检索外部知识(如数据库、搜索引擎等),将检索到的信息作为上下文输入模型。值得一提的是,RAG也是实际业务应用大模型最常见的方案之一。
Scaling Law:规模定律。指的是语言模型的性能随着参数规模、数据规模和计算量的增加而提高的规律,但当模型规模和训练资源达到一定程度后,性能提升的速度会逐渐放缓。这甚至有一点像哲学的概念,这或许是不同领域的普遍规律,只是在大语言模型所体现的效果过于突出。
AGI:Artificial General Intelligence,通用人工智能。指的是能够像人类一样完成广泛任务的人工智能,而不仅仅局限于特定领域或任务,它拥有像人类一样推理、学习和适应新任务的能力。AGI属于是当前人工智能研究的终极目标,还远没有被实现。目前的ChatGPT等还是被称作窄人工智能(ANI,Artificial Narrow Intelligence),代表只是在特定领域表现出色。
AIGC:AI-Generated Content,人工智能生成内容。AIGC指通过人工智能技术生成的内容,包括文本、图片、音频、视频等。用 ChatGPT 编写文案、用 AI制作短视频脚本等,都属于 AIGC 的应用。
Agent:智能体。在大模型语境下的Agent,往往是指利用大模型强大的自然语言理解和生成能力,赋予智能体决策和执行任务的能力。如果比较宽泛的讲,基于大模型能力来解决具体任务的app或者程序,一般都可以被称为Agent。
二、如何获取大模型信息
像前面所提到的,现今除了大模型的进展日新月异,各式各样的信息也在不停轰炸我们。所以这里我们想聊的也不仅仅是获取大模型信息,而是希望关注现今如何高效的对大量信息进行获取、汇总和学习。其实我自己的知识管理方案仍然是很不成熟,主要将一些经验和尝试分享给大家,供参考和指正。
信息源
我目前接收的信息源主要有以下几类:
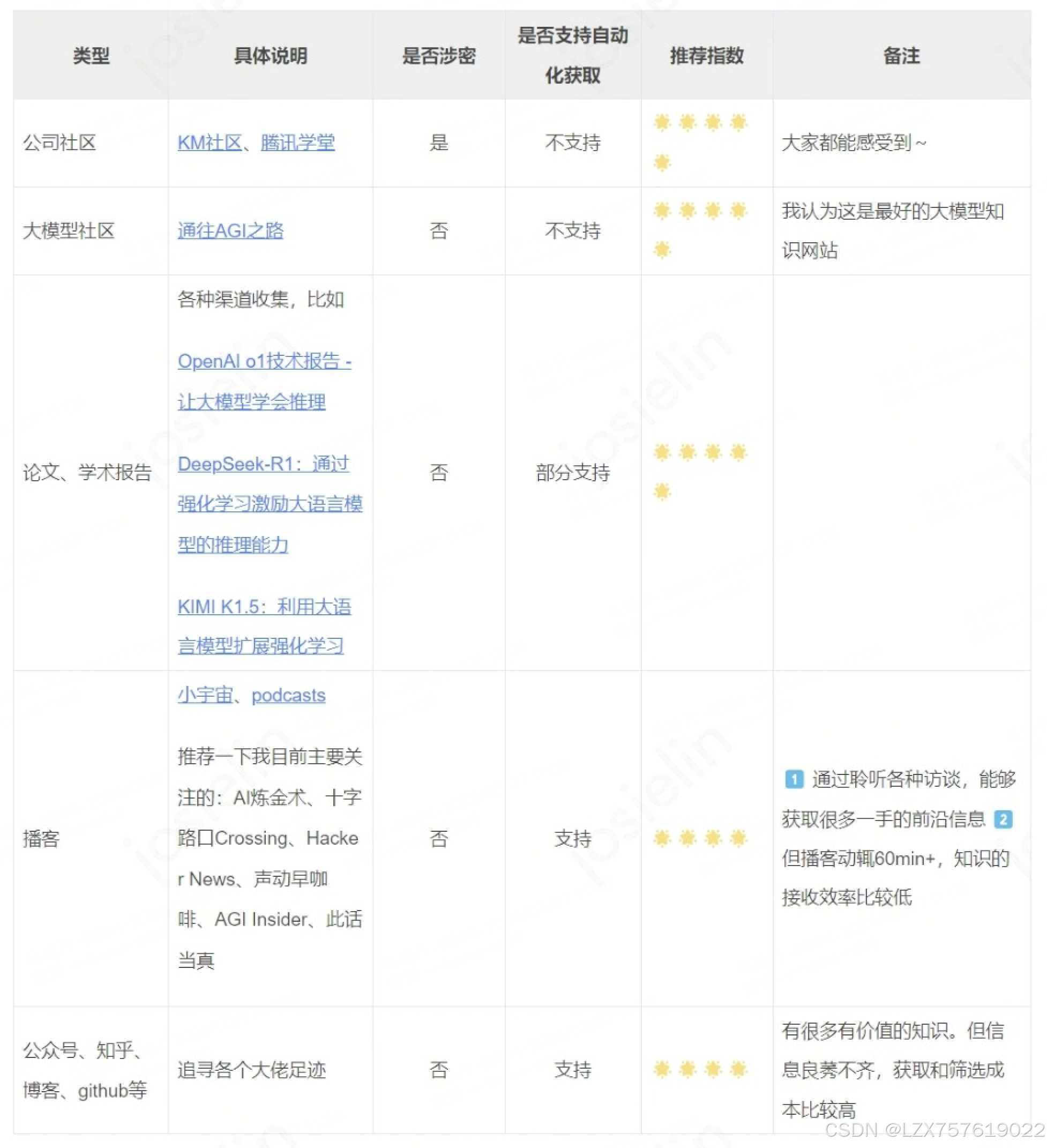
*相关链接:
通往AGI之路
OpenAI o1技术报告 - 让大模型学会推理
DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1 · GitHub
KIMI K1.5:利用大语言模型扩展强化学习
小宇宙
podcasts
信息收集
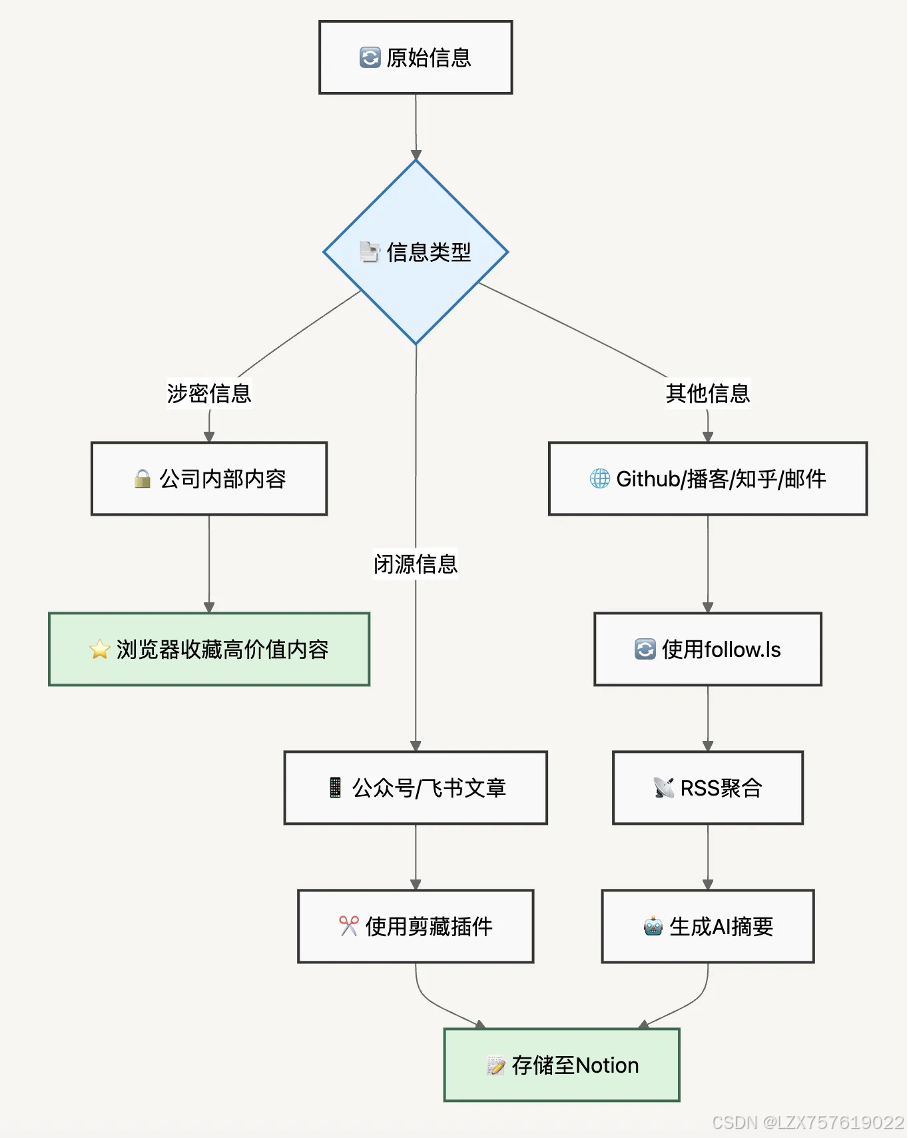
从上面一节已经可以看到很多有价值的信息源,但是每天都需要去看那么多页面吗?特别许多大佬的博客都是独立站点部署,很难每天都得点进那么多网站收集信息。因此我目前的信息收集策略主要拆分为三个方式
1、涉密信息(主要指公司内部内容)不采取额外处理,高价值文章浏览器收藏即可;
2、闭源信息(比如公众号、飞书等)在观察到高价值文章后,通过剪藏插件向notion进行记录和整合;
3、其它信息(github、播客、知乎、邮件推送等)占比量级是最大的,也是最良莠不齐的。这方面推荐follow.ls,支持汇总rss订阅,并且在一个界面观看所有内容,以及支持自动化策略生成AI摘要并向notion进行信息记录。
顺带提下老生常谈的笔记工具选择,我目前是使用notion,主要因为它的API支持比较好,并且功能全面不用怎么折腾。
完整流程
整体流程如下(PS:这张图就是基于上面的文案用notion AI生成的)
**
三、怎么用好大模型
**
Prompt、Context、RAG
每提到大模型的使用,Prompt(提示语)永远是需要关注的第一步。一般来说,就是需要用清晰、完整并且易于理解的话术向大模型说明我们的需求,我们才可以得到更好的反馈。这里我就不过多展开了,推荐阅读吴恩达老师的ChatGPT Prompt Engineering for Developers。
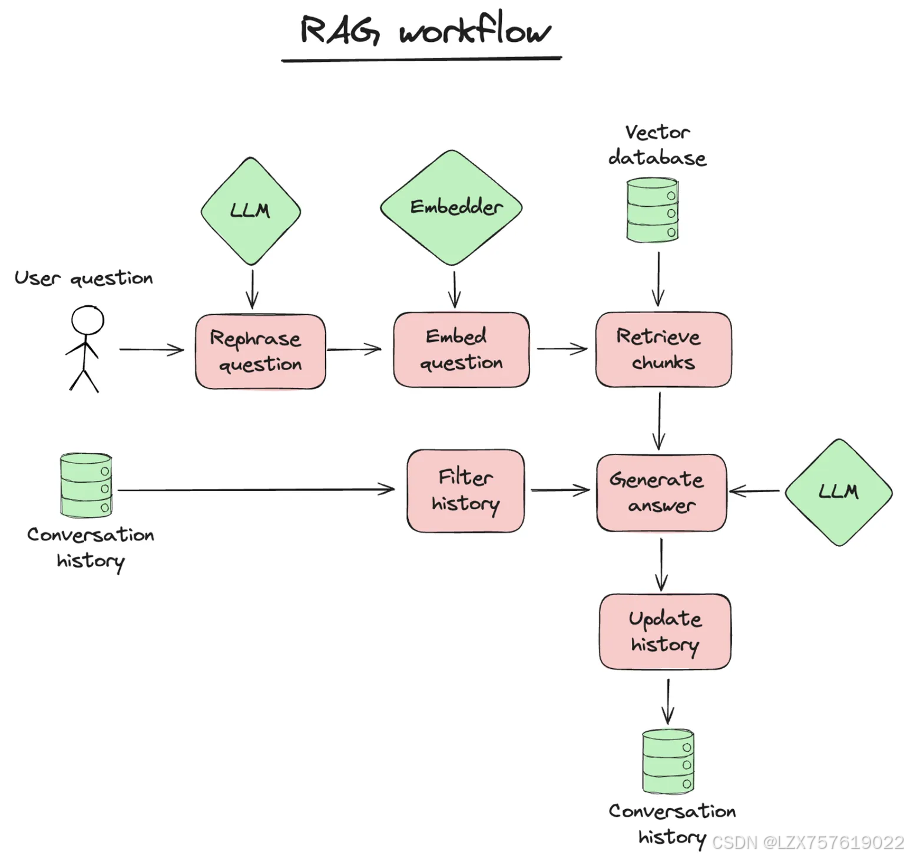
但是除了Prompt以外呢,还有一个会起到关键作用的就是Context(上下文信息)。虽然一个优质的Prompt应该尽量完整带上所需的上下文信息,但是Prompt的长度总是有限的。因此在很多场景,如果需要获得更加精确的信息或者更加优质的答案,我们往往需要引入知识库的RAG(检索增强生成)。简单来说,就是通过搜索知识库得到关联的信息,再合并到Prompt里面去询问大模型。
目前无论是个人还是业务使用,RAG工作流程都是落地最广泛的实践之一,值得作为学用大模型的第一站。具体实现细节可以参考quivr。
本图引用自quivr
皇冠上的明珠:编程助手
很多说法都表示【编程助手】是大模型Agent领域厮杀最激烈的应用,主要有三个原因:
1、【编程助手】可以帮助程序员成比例的提效,因此几乎可以量化经济价值,商业模式上更容易落地。
2、基于开源社区和各公司内部积累了大量优质源码,因此数据层面不容易成为瓶颈,大模型在算法层面的效果可以更加彻底的体现。
3、如果【编程助手】效果足够好,这种程序化能力也可以直接作为其它业务领域的基石,想象空间非常大。
其间经历了很多迭代,存在非常多的应用场景(编程助手、编程教育、低代码、虚拟员工、…),本文拣选两个和我们普通开发者比较相关的场景进行分享
虚拟员工
去年devin一经发布,虚拟员工这个概念立刻就名噪一时。devin预期是编程助手的终极形态 ➡️ AI程序员,直接对它说明需求就可以自动化生成完备的架构和代码。虽然**高昂的价格(500美元/月)、异步的使用体验(需要等待一段时间才会执行完毕)、不那么完美的结果(过于依赖基座模型的能力和项目文档的规范性,导致复杂项目效果不理想)**让devin已经缓慢退去热度,但是这个概念已经深入人心。
相信虚拟员工在不久以后的将来一定会来。因此也推荐了解OpenHands这个项目,它是Devin的开源版本,顺便也感慨一下手上的饭碗岌岌可危。
怎么用好编程助手
不管怎么说,devin目前看起来还不是能够直接帮助我们革命的应用,那现在真正能直接有效帮助程序员的编程助手是什么呢?是业界大名鼎鼎的Cursor、Windsurf,是字节刚才推出的trae,是我司越来越好的工蜂copilot。这些工具已经有非常丰富的文档,并且开箱即用的体验也都很好。这里以cursor为例,主要聊一下容易被忽视的.cursorrules功能。
因为要使大模型的作用更好的激发出来,除了需要依赖基座大模型能力、Agent本身策略、良好的Prompt以外,还有一个关键就是Context(上下文信息)。因为我们不能过分去依赖大模型的主观创造,而.cursorrules功能本身就是为了引导和约束大模型,比如我们可以在.cursorrules配置:
1、可以主动调取的工具API(比如搜索、截图、api请求等),使cursor具有更强大的能力
2、统一的代码规范,以及将具体项目中的“潜规则”也可以告知cursor
3、个性化使用体验,比如尝试让cursor自动化生成单元测试
基于以上,可以参考awesome-cursorrules和devin.cursorrules,帮助我们将cursor做到接近devin,甚至某些方面超越devin的作用。
不可不提的Agent
在大模型时代,Agent(智能体)应该是最炙手可热的一个词。这并不是一个新鲜的概念,只是大模型到来以后,Agent的想象力开始被无限打开。比如上文提到的“编程助手”就是编码领域的Agent,比如百亿美金估值的perplexity只是专注实现大模型搜索功能的Agent。迄今Agent应用和平台已经呈现了百花齐放的生态。

本图引用自awesome-ai-agents
由上图可见Agent方案已经多到迷人眼,其间涉及的技术发展可能够咱们行业未来再研究好几年。下文主要就比较典型的几种Agent开发策略简单介绍,一起来掀开Agent开发的一角

争奇斗艳的大模型工具
终于来到了介绍大玩具环节。我基本陆续尝试过业界主流的大模型工具,以下罗列的全部都是我认为其中比较常用或比较好用的一部分,供大家参考。
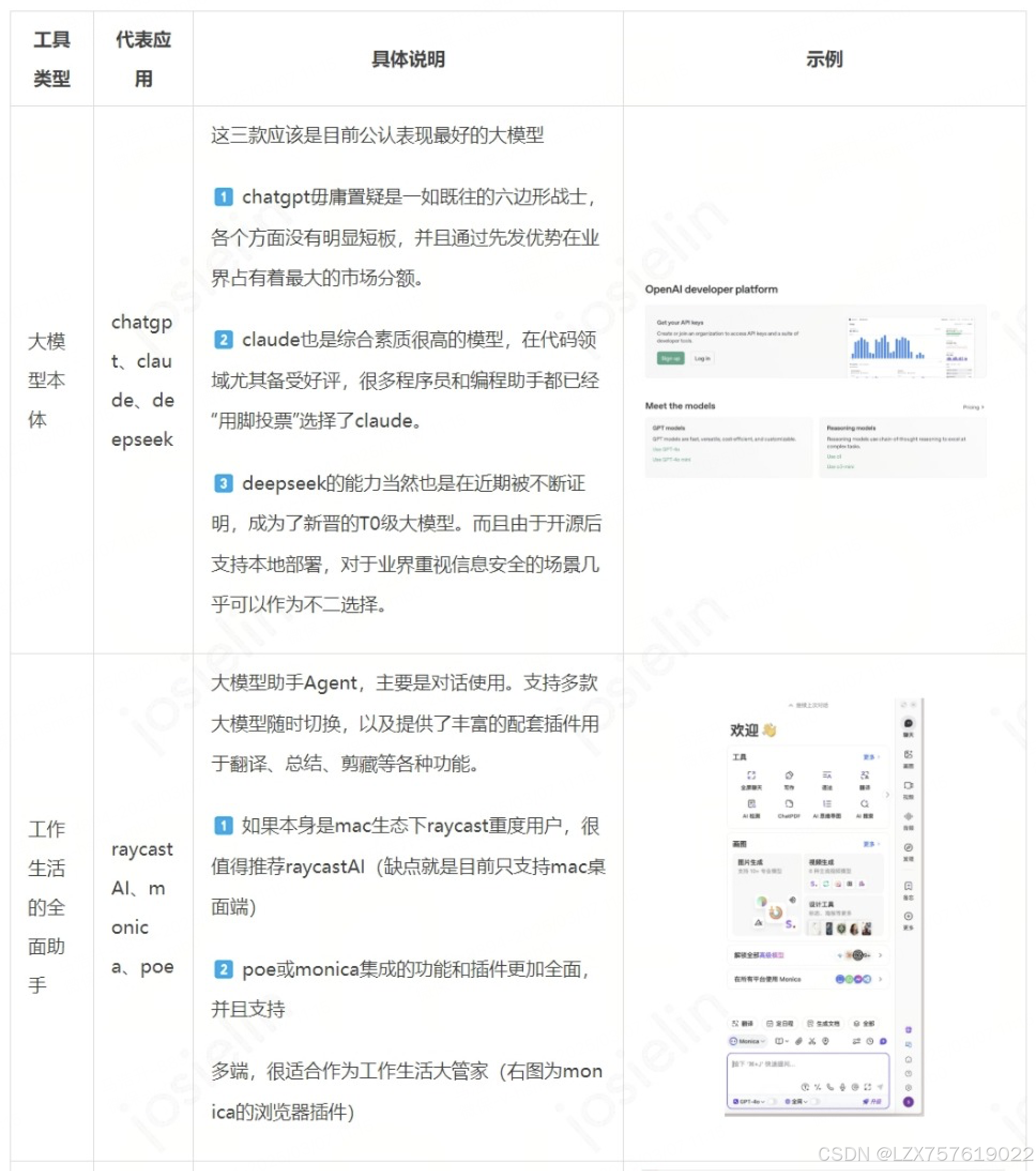
本文到这里差不多就结束啦。虽然大模型肯定还有太多太多值得讲的,比如Fine-tuning(微调),比如提到的各种大模型技术都值得再进行深入的拓展,比如公司内外还有着各式各样的最佳实践,就留待将来再逐步探讨。本文主要是抛砖引玉,将现今更加贴近我们工作生活的一些内容进行分享,希望能对各位有所启发并欢迎指正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









