






概述
本项目是使用scrapy框架制作,python版本3.10.9,scrapy版本2.8.0
根据传入的二手房地址(比如聊城:https://lc.58.com/ershoufang/p1/?PGTID=0d200001-0037-2a49-74cc-7e9b4290aaaa&ClickID=1),按照城市对城市进行提取;
调研
列表页地址:
第一页(第一页特殊可以不加p1):
https://zj.58.com/ershoufang/p1/?PGTID=0d100000-0028-5b5c-1e49-3778b79dcf2a&ClickID=4
第二页:
https://zj.58.com/ershoufang/p1/?PGTID=0d100000-0028-5b5c-1e49-3778b79dcf2a&ClickID=4
提取列表页的每个房产信息
每个item存放在div中
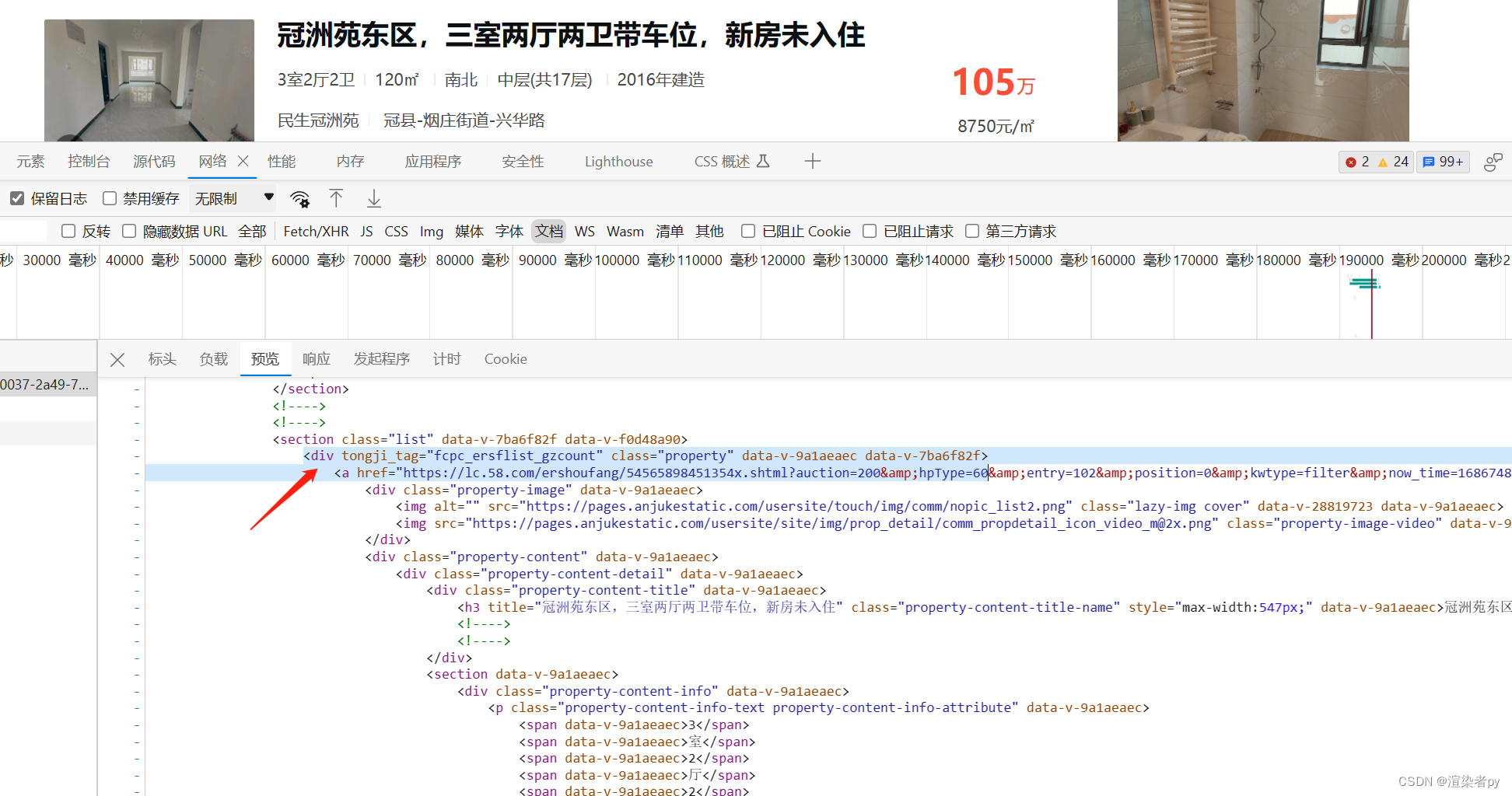
语法:
.//section[@class='list-body']//section[@class='list-main']//section[@class='list']/div
提取详情页地址以及其他数据
遍历上一步得到的div,遍历每个div
语法(需要在div的层级下):
.//a/@href
并以此提取其他信息,如:标题,价格,面积,单价,年份等;
并且a标签内含有此条目信息的额外信息用于提取二维码信息用,存放于a标签的data-ep属性中,以json格式存储,通过json.loads就可以解析
提取下一页的地址
根据列表页的相应html,通过xpath语法获取下一页的地址:
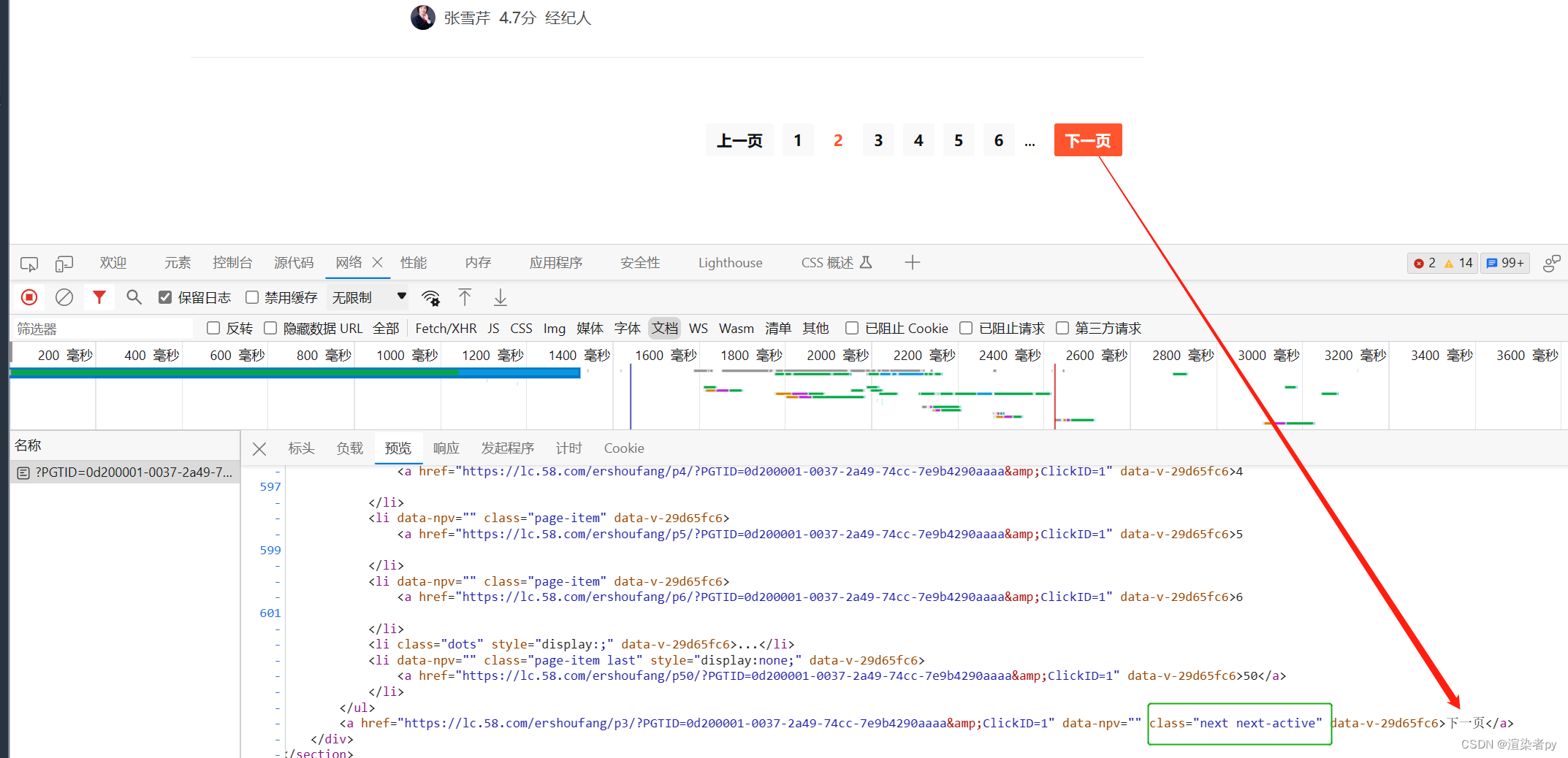
语法:
.//a[@class='next next-active']/@href
在详情页提取额外信息为获取二维码准备
获取发布时间
语法:
.//div[@id='houseInfo']//tbody/tr//span[text()='发布时间']/parent::td/span[@class='houseInfo-main-item-name']/text()
研究详情页发现二维码的获取比较特殊,需要发送post请求,请求体发送的不是form表单,而是发送的raw字符串,格式参考如下:
{"city_id":837,
"twUrl":"",
"redirectTo":"/page/taroPage/esf/pages/detail/detail",
"extParams":{"id":"3018611611085826","broker_id":"202547734","source_type":"19","city_id":"837","is_auction":"201","auto_call":true,"store_id":"912427"}}
经研究发现,
city_id字段在详情页响应头中提取ctid的值
id根据详情页的地址提取id
redirectTo固定值
broker_id为列表页中的data-ep中提取 ["data_ep"]['exposure']['broker_id']
source_type为列表页中的data-ep中提取 ["data_ep"]['exposure']['source_type']
is_auction 为列表页中的data-ep中提取 ["data_ep"]['exposure']['isauction']
auto_call固定True
store_id在本详情页的script标签中提取onsaleProplistAction字段里的数据,进行url解析json数据,拿到store_id
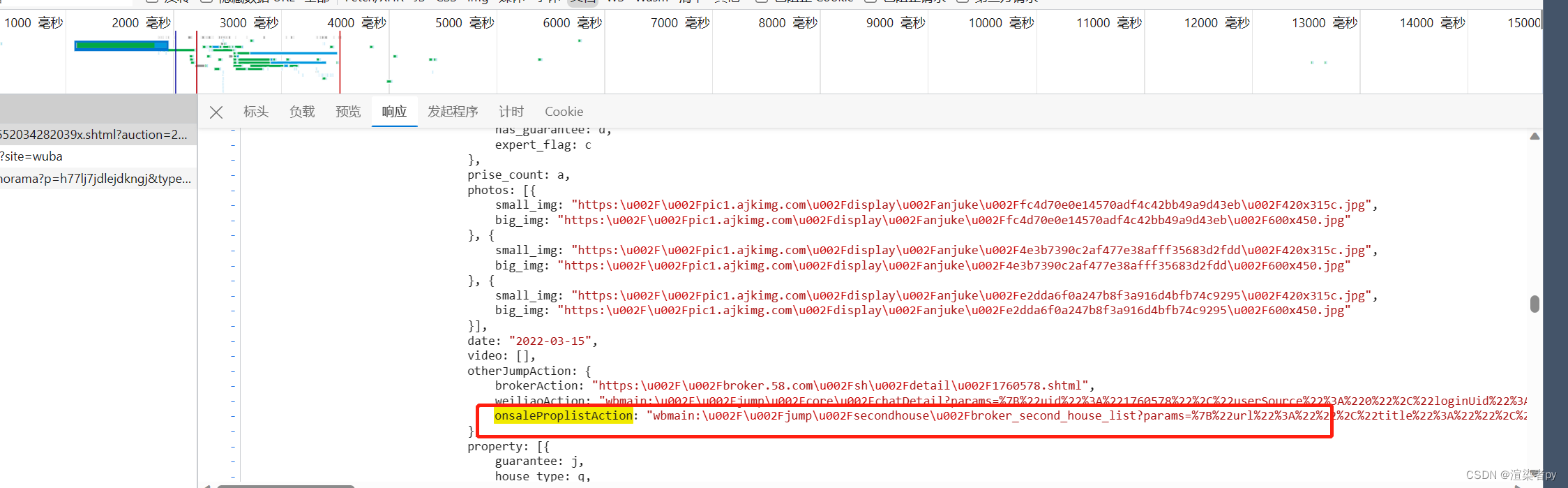
拼装数据提取二维码地址
代码参考
列表页代码
import scrapy
from scrapy.http.response.html import HtmlResponse
from copy import deepcopy
import re,json,time
from urllib.parse import urlparse, parse_qs
def parse(self, response:scrapy.http.response.html.HtmlResponse):
self.count+=1
print("状态码:",response.status)
self.time_tag = int(time.time())
# with open(f"./list-{self.time_tag}.html","w",encoding='utf-8') as f:
# f.write(response.body.decode())
# with open(f"./list-headers-{self.time_tag}.json","w",encoding='utf-8') as f:
# f.write(json.dumps(response.headers.to_unicode_dict()))
if False and urlparse(response.url).netloc != urlparse(self.start_urls[0]).netloc:
print("%"*100)
print("被拦截")
self.crawler.engine.close_spider(self, "当调用此方法时打印信息为:无有效信息,关闭spider")
div_list = response.xpath(".//section[@class='list-body']//section[@class='list-main']//section[@class='list']/div")
print("div_len:",len(div_list))
cookies = {}
if response.headers.get("set-cookie"):
tmp = response.headers.get("set-cookie").decode()
tmp_list = tmp.split(';')
for i in tmp_list:
i_split = i.split('=')
cookies[i_split[0]] = i_split[1]
# print(response.body.decode())
for div in div_list:
headers = response.headers.to_unicode_dict()
item = {}
item["title"] = div.xpath('.//h3[@class="property-content-title-name"]/@title').get() # 父级地址
item["publish_time"] = ""
item["publisher_name"] = ""
item["publisher_type"] = ""
item['qrCode'] = ""
item["href"] = div.xpath(".//a/@href").get().strip() # 详情页地址
item["href_parent"] = response.url # 父级地址
tmp = div.xpath(".//a/@data-ep").get().strip()
data_ep = {}
if tmp:
data_ep = json.loads(tmp)
p_list = div.xpath(".//p[contains(@class,'property-content-info-attribute')]/parent::div/p")
layout = div.xpath(".//p[contains(@class,'property-content-info-attribute')]/span/text()").getall()
item["layout"] = ''.join(layout)
item["area"] = p_list[1].xpath("./text()").get().strip() if len(p_list)>1 else ""
item["toward"] = p_list[2].xpath("./text()").get().strip() if len(p_list)>2 else ""
item["building_info"] = p_list[3].xpath("./text()").get().strip() if len(p_list)>3 else ""
item["building_time"] = p_list[4].xpath("./text()").get().strip() if len(p_list)>4 else ""
item["community_name"] = div.xpath(".//p[@class='property-content-info-comm-name']/text()").get()
item["addr"] = "-".join(map(self.trimstr, div.xpath(".//p[@class='property-content-info-comm-address']/*/text()").getall())) # 地段
item["tag"] = div.xpath(".//div[@class='property-content-info']/span/text()").getall() # 标签
publisher_span_list = div.xpath(".//div[@class='property-extra-wrap']//span[@class='property-extra-text']")
# print("publisher_span_list::",publisher_span_list.xpath("./text()").getall())
if len(publisher_span_list)>2:
item["publisher_name"] = publisher_span_list[0].xpath("text()").get().strip() if len(publisher_span_list)>0 else "" # 发布者
item["publisher_score"] = publisher_span_list[1].xpath("text()").get().strip() if len(publisher_span_list)>1 else ""# 发布者
item["publisher_type"] = publisher_span_list[2].xpath("text()").get().strip() if len(publisher_span_list)>2 else "" # 发布者 经纪人 房东
elif len(publisher_span_list)==2:
item["publisher_name"] = publisher_span_list[0].xpath("text()").get().strip() if len(
publisher_span_list) > 0 else "" # 发布者
item["publisher_type"] = publisher_span_list[1].xpath("text()").get().strip() if len(
publisher_span_list) > 1 else "" # 发布者 经纪人 房东
item["publisher_score"] = ""
else:
item["publisher_name"] = publisher_span_list[0].xpath("text()").get().strip() if len(
publisher_span_list) > 0 else "" # 发布者
item["publisher_score"] = "" # 发布者
item["publisher_type"] = "" # 发布者 经纪人 房东
if item["publisher_type"]!="房东":
# print("过滤经纪人。。。",item['publisher_name'])
continue
else:
print("爬取房东:",item['publisher_name'])
print(item['href'])
item["price_total"] = ''.join(map(self.trimstr,div.xpath(".//p[@class='property-price-total']/*/text()").getall())) # 总价
item["price_average"] = div.xpath(".//p[@class='property-price-average']/text()").get().strip()# 单价
item['data_ep'] = data_ep
item['pageNum'] = self.count
yield scrapy.Request(
url=item["href"],
callback=self.parse_detail,
meta={"item": deepcopy(item),"cookies":deepcopy(cookies)},
cookies = cookies
)
# break
next_url = response.xpath(".//a[@class='next next-active']/@href").get()
print("---next list---")
print(next_url)
if self.count < 50 and next_url:
self.pageNum += 1
yield scrapy.Request(
url=next_url,
callback=self.parse,
cookies=cookies
)
详情页代码:
def parse_detail(self,response:scrapy.http.response.html.HtmlResponse):
# with open(f"./detail-{self.time_tag}.html","w",encoding='utf-8') as f:
# f.write(response.body.decode())
# with open(f"./detail-headers-{self.time_tag}.json","w", encoding='utf-8') as f:
# f.write(json.dumps(response.headers.to_unicode_dict()))
# print("-"*100)
# print(response.url)
# print("#"*100)
body = response.body.decode()
id_match = re.match(r".*/(\d+)?\w?\.shtml", response.url)
script_text = response.xpath(".//script[contains(text(),'window.__NUXT__=')][1]/text()").get()
script_match =re.match(r".*config:{}}}\(([^;]+)\);",script_text)
onsaleProplistActionMatch = re.match(r'.*onsaleProplistAction:"([^"]+).*', script_text, re.S)
onsaleProplistActionUrlParams = {}
if onsaleProplistActionMatch:
onsaleProplistActionUrl = onsaleProplistActionMatch.group(1)
parsed = urlparse(onsaleProplistActionUrl)
urlParams = parse_qs(parsed.query)
onsaleProplistActionUrlParams = json.loads(urlParams['params'][0]) if urlParams['params'][0] else {}
cookies = response.meta['cookies']
if response.headers.get('set-cookie'):
tmp = response.headers.get("set-cookie").decode()
tmp_list = tmp.split(';')
for i in tmp_list:
i_split = i.split('=')
cookies[i_split[0]] = i_split[1]
item = response.meta['item']
match_ret = re.match(r".*ctid=(\d+).*",response.headers.to_string().decode(), re.S)
if match_ret:
city_id = match_ret.group(1)
else:
city_id = 110
# print("city_id=",city_id)
twUrl = ''
redirectTo = '/page/taroPage/esf/pages/detail/detail'
extParams = {
"id":id_match.group(1), # str
"broker_id":item["data_ep"]['exposure']['broker_id'],
"source_type":str(item["data_ep"]['exposure']['source_type']),
"city_id":city_id,
"is_auction":str(item["data_ep"]['exposure']["isauction"]),
"auto_call":True,
"store_id":str(onsaleProplistActionUrlParams['store_id']) if 'store_id' in onsaleProplistActionUrlParams else '',
}
raw_data = {
"city_id":int(city_id), # number
"twUrl":twUrl,
"redirectTo":redirectTo,
"extParams":extParams
}
# print("%"*100)
# print(json.dumps(raw_data))
# print("%"*100)
headers = response.headers.to_unicode_dict()
headers['content-type'] = 'application/json;charset=UTF-8'
# for k, v in headers.items():
# print("%s:%s"%(k, v))
del(headers['Content-Length'])
# print("=headers=")
# print(json.dumps(raw_data, separators=(',', ':')))
# print("===raw_data===")
image_data = response.xpath("//div[@class='props-body']//section//div[@class='gallery-indicator']//img/@src").getall()
# 发布时间
item['publish_time'] = response.xpath(
".//div[@id='houseInfo']//tbody/tr//span[text()='发布时间']/parent::td/span[@class='houseInfo-main-item-name']/text()").get()
item['image_list'] = image_data
yield scrapy.Request(
url=response.urljoin("/esf-ajax/qrcode/get/"),
callback=self.pase_qrcode,
meta={"item": deepcopy(item),"cookies":deepcopy(cookies),'raw_data':deepcopy(raw_data)},
method = 'POST',
body = json.dumps(raw_data,separators=(',',':')),
headers=headers,
cookies = cookies,
)
'''
{"city_id":837,
"twUrl":"",
"redirectTo":"/page/taroPage/esf/pages/detail/detail",
"extParams":{"id":"3018611611085826","broker_id":"202547734","source_type":"19","city_id":"837","is_auction":"201","auto_call":true,"store_id":"912427"}}
'''
# print(response.body.decode())
二维码页面代码:
def pase_qrcode(self,response:scrapy.http.response.html.HtmlResponse):
item = response.meta['item']
# with open(f"./qrcode-{response.meta['raw_data']['extParams']['id']}.html","w",encoding='utf-8') as f:
# f.write(response.body.decode())
# with open(f"./qrcode-headers-{item['raw_data']['extParams']['id']}.json","w", encoding='utf-8') as f:
# f.write(json.dumps(response.headers.to_unicode_dict()))
# print("====qrcode====")
# print(response.body.decode())
print("count:",self.count)
try:
data = json.loads(response.body.decode())
except Exception as e:
print(e)
print("二维码被拦截")
self.crawler.engine.close_spider(self, "二维码拦截:无有效信息,关闭spider")
if 'data' in data and 'qrCode' in data['data']:
item['qrCode'] = data['data']['qrCode']
yield item
默认请求头参考:
DEFAULT_REQUEST_HEADERS = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "max-age=0",
"sec-ch-ua": "\"Not.A/Brand\";v=\"8\", \"Chromium\";v=\"114\", \"Microsoft Edge\";v=\"114\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"cookie": "userid360_xml=8ACD42AF2FDE1B626591B6A18D366099; time_create=1688553915242; f=n; commontopbar_new_city_info=882%7C%E8%81%8A%E5%9F%8E%7Clc; commontopbar_ipcity=sh%7C%E4%B8%8A%E6%B5%B7%7C0; SECKEY_ABVK=VplOGrV1j6vqZyPESQk0pK7TIzgxLZJ8AW8f4hqvzbk%3D; BMAP_SECKEY=nMYEEaEn1SDxUgXRx0HKm8Rcii2-6nxOR-D2QmCZdiPuH2laf1tIO_C70Hbi5tpNiToD0-vweV_mOV60OQPblX5aBphHKPtRvfXHFskNc61hyfpFa16jF7UjOkeDBFX89FzrNwy_SLbFkRhHtRQexnBi8CEFZdl0q11bJ_zLNMfEkb3jVg51pgkjwsFC9lYA; id58=n6Oz32RwfFAxOTpE71p+7g==; 58tj_uuid=71ac63b4-9b7a-4090-be5a-73a39f63abc8; als=0; wmda_uuid=109325b47bf15cbc4cc039161e7ba0dc; wmda_new_uuid=1; aQQ_ajkguid=41B69512-2F45-4D09-BC94-D8F6D94190A7; sessid=4B4872E1-6E19-4427-A7D0-606A6A5068FB; ajk-appVersion=; xxzl_smartid=34524abde54d66f73534213254085da7; __bid_n=1886a57e1c58661ccd4207; wmda_visited_projects=%3B11187958619315%3B2385390625025%3B10104579731767%3B2427509687170; cookieuid1=CrIBUGR1VlE0C3mpClP6Ag==; 58uname=%E4%BE%9D%E7%84%B6%E6%B2%89%E9%BB%98%E4%B9%85%E4%BA%86; passportAccount=\"atype=0&bstate=0\"; ppStore_fingerprint=1CF279E49620451D42E8C4FB32E37C397C7B6E93BF75F34B%EF%BC%BF1685411629689; myLat=\"\"; myLon=\"\"; mcity=sh; fzq_h=33515b2e010a585ea0d1af3f614afa69_1686210824106_d123b2cb73c44ccbac7ca2100eeaf718_3662675699; new_uv=13; utm_source=; spm=; init_refer=; new_session=0; 58_ctid=882; is_58_pc=1; commontopbar_new_city_info=125%7C%E8%81%8A%E5%9F%8E%7Clc; f=n; ctid=882; xxzl_cid=e741761c5cd44299883940f102cee898; xxzl_deviceid=MmL8lF9ZwcoQBnYgdSC5PPeC4616/A092IK/igRR2VHrTFBXej2egmEPF6DagNBD; commontopbar_new_city_info=882%7C%E8%81%8A%E5%9F%8E%7Clc; commontopbar_ipcity=sh%7C%E4%B8%8A%E6%B5%B7%7C0; city=lc; 58home=lc; wmda_session_id_11187958619315=1686211371341-b7c22c88-7207-f006; wmda_session_id_2385390625025=1686211542933-9e9f3404-a5a6-9826; dfxafjs=js/dfxaf3-2cbeaf6b.js; FPTOKEN=c28NrLGAzDO+9GvPAJARdNwZS+Ys3U51AVqDXsW2DS/KT5UWjwguo+py6f/8U5C514yCQx+XvvL08mPPB256oFf63ZAGS0TTIbi45iAjes2ipEYB9MlJ7Dp12OlLNv6KKnQYiCFPvf3LVlVs4Gb+PoLZR+q1R9l7LYAiHFJOp3wXglUnRn34kmQAWix+BQJDGs4lGbvuVyPbltgeVeVH+v0EvU/q1pNQSkrK6v9Du8x4jpVzZMhVhFGdO0zlLxzWgy8iNH5vGOMkIB37gXwQdq0bPncTGjSLYbC+f/jCOAccFwCFWrfXV2UtUkEmRkCyUBsKKcBMZWJ60m6ZcN83j0/YStftUhVar/wDjl/AE0PnhhvrCxiOgW2bfeNWPIYjK9V7Nvm8Usj97kYZ9XAchw==|W/1VBe/R3LowFlErt7xEdWylkU9Wx+MioLRKe813kGg=|10|f898d67bc7b7648804b41556456b8bf2; PPU=\"UID=13890608744199&UN=%E4%BE%9D%E7%84%B6%E6%B2%89%E9%BB%98%E4%B9%85%E4%BA%86&TT=5548018f9827f45334e4294bfb364c41&PBODY=EuL2NMnfS4kE_p1-paGAZ5T3SyNThjRhBQ6AksZGIicXZpBpKY1WbRCug5YZ3DM1TePjyjCTALfQ2Z4jW99pQABwnaJJvSNtYDkTQm08ILummGpunAPCvy1Y-thY_YkLijgowt7kJcyym7AVxaXE1n8PqSHW89quxxsgmTdc_xE&VER=1&CUID=cKjK4HP258RtXKDOfPQG5Q\"; xxzl_cid=e741761c5cd44299883940f102cee898; xxzl_deviceid=MmL8lF9ZwcoQBnYgdSC5PPeC4616/A092IK/igRR2VHrTFBXej2egmEPF6DagNBD",
"Referer": "https://zj.58.com/",
"Referrer-Policy": "strict-origin-when-cross-origin",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.37',
}
















 1278
1278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









