







本文为原创文章,转载请注明出处!
在训练数据的过程或者参加数据比赛的时候,常常会遇到数据量不够大的情况,在一次比赛过程我学到一个小技巧—K折交叉验证法(k-fold CrossValidation),下面和大家分享一下。
1 变形前的K折
在遇到K折交叉验证之前,往往使用的是简单交叉验证(hold -out cross validation),也就是从全部的训练数据 D中随机选择 d的样例作为训练集 train,剩余的作为测试集 test(红色方框表示)。相信大家一定都非常熟悉,如果还不是很了解赶紧看看大牛Andrew Ng的课程吧。

在这里,数据都只被所用了一次,没有被充分利用
那么,怎样提高数据的利用率呢?
2 K折就是讲数据集切分成K小块,验证集和测试集相互形成补集,循环交替
纽约大学博士Seymour Geisser提出K折交叉验证法,具体步骤如下:
将数据集D随机分为k个包(这里假定K=6)。
每次将其中一个包作为测试集test,剩下k-1个包作为训练集train进行训练。
此时训练集train由D变成了K*D,
- 最后计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率。


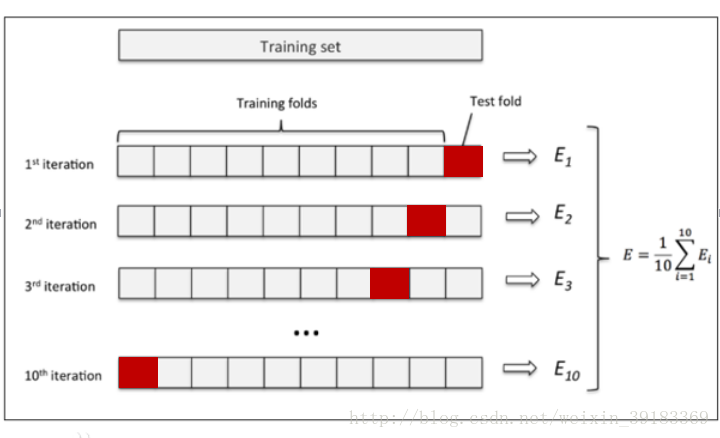
它有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性
你可能会问K选多少合适呢?
根据情况和个人喜好调节,常用的K值有3,6,10等。
3 python实现
在scikit-learn中有CrossValidation的实现代码,地址:scikit-learn官网crossvalidation文档
使用方法:
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]














 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









