









 本文对papi家的大小咪在b站的视频数据进行探索,发现短视频更受欢迎,小咪在标题中提及频率高,粉丝更喜欢小咪的视频,10-14点间投稿播放量较高,且papi较少参加b站活动。
本文对papi家的大小咪在b站的视频数据进行探索,发现短视频更受欢迎,小咪在标题中提及频率高,粉丝更喜欢小咪的视频,10-14点间投稿播放量较高,且papi较少参加b站活动。
对papi家的大小咪视频数据进行探索及可视化
papi酱,一位集美貌与才华于一身的女子,2016年依靠自拍的搞笑视频迅速走红,成为了”2016年第一网红”。 papi酱的走红刷新了互联网自媒体时代的很多纪录,但她似乎又没有改变太多,自拍依旧不修图,时不时黑下老胡,没有工作时就躺在家里撸猫。2017年她开始往b站上传她家两只猫咪的视频。目前“papi家的大小咪”这个账号在b站已经获得了72.2万的订阅,成为“bilibili 知名萌宠UP主”。
这篇文章主要是针对papi家的大小咪在bilibili上的视频数据进行探索,目的是对大小咪的受欢迎程度,papi酱对大小咪的偏爱程度,视频更新频率以及视频长度等进行探索及可视化。
下面先来看看分析对象——papi家的大小咪长什么样
(温馨提示:白色的是大咪,黄色的是小咪)
它们俩性格各异:大咪对papi时刻保持高冷但在对面老胡的时候还是一只粘人小猫咪,喜欢吃东西;而小咪则是一只活泼且话唠的小猫咪,极其喜欢粘着papi。

一、数据集
本次数据来自 papi家的大小咪在bilibili发布的从2017年10月9日至2019年9月21日的共237条视频信息。
二、初探数据
导入数据并查看数据的基本情况,通过对数据的描述我们可以发现,数据共有20个字段,244行,但是存在列名重复录入,subtitle、copyright、description等数据缺失较多的情况,created是时间戳需要转换为日期格式。
import pandas as pd
import numpy as np
import MySQLdb
conn = MySQLdb.connect(host='localhost', user='dbname', passwd='dbpwd',port=3306, db='papi', charset="utf8")
cur = conn.cursor()
papi_df = pd.read_sql('select * from papi', con=conn)
papi_df.info()
papi_df.isnull().sum().sort_values(ascending=False)
papi_df.head()


(由于title没有缺失但是字数太多影响观察先暂时去掉,待会儿再单独进行观察)
papi_df.drop('title',axis=1).sample(5)

单独观察title列,发现“papi酱的大小咪”和“papi家的大小咪”在标题处重复出现,会对后面统计“大咪”、“小咪”等的词频会造成影响。
papi_df['title'].unique()

目前对数据的处理思路是:
1)调整数据类型:由于一开始用到了str来导入,打算后期再更换格式,需要调整数据类型;
2)选择部分子集:因为有部分列在数据分析中不需要用到;
3)格式一致化:title“papi酱的大小咪”和“papi家的大小咪”在标题处重复出现等问题,需要去除;
4)消灭空值:subtitle、copyright和description都出现了NaN值,需要去掉。
数据清洗
选择部分子集,并删除重复行
papi_df=papi_df.drop(['author','copyright','hide_click','is_pay','is_union_video','mid','pic','review','typeid','description','subtitle'],axis=1)
papi_df=papi_df.drop_duplicates(keep=False)
调整数据类型并对部分数据进行清洗
papi_df['datetime']=papi_df['created'].apply(lambda x: pd.to_datetime(x,unit='s'))
papi_df['comment']=papi_df['comment'].astype('int')
papi_df['favorites']=papi_df['favorites'].astype('int')
papi_df['video_review']=papi_df['video_review'].astype('int')
papi_df['play']=papi_df['play'].astype('int')
papi_df['datetime']=papi_df['datetime'].astype('str')
papi_df['date']=papi_df['datetime'].apply(lambda x:x.split(' ')[0])
papi_df['date']=pd.to_datetime(papi_df['date'],format='%Y-%m-%d',errors='coerce')
papi_df['hour']=papi_df['datetime'].apply(lambda x:x.split(' ')[1].split(':')[0])
papi_df['length']=papi_df['length'].apply(lambda x:x.split(':')[0])
由于删除重复行后索引不连续了,重设一下索引
papi_df=papi_df.reset_index(drop = True)
由于”papi酱的大小咪“等标题前缀的出现会影响到后续对视频标签的分类,这里对标题列清理一下
def cut_title(title):
tList=[]
for value in title:
if value.split(' ')[0]=='papi酱的大小咪':
tNew=''.join(value.split(' ')[1:])
tList.append(tNew)
elif value.split(' ')[0]=='papi家的大小咪':
tNew=''.join(value.split(' ')[1:])
tList.append(tNew)
elif value.split(',')[0]=='papi家的大小咪':
tNew=''.join(value.split(',')[1:])
tList.append(tNew)
elif value.split(',')[0]=='papi酱的大小咪':
tNew=''.join(value.split(',')[1:])
tList.append(tNew)
elif value.split(':')[0]=='papi酱的大小咪':
tNew=''.join(value.split(':')[1:])
tList.append(tNew)
elif value.split(':')[0]=='papi家的大小咪':
tNew=''.join(value.split(':')[1:])
tList.append(tNew)
else:
tList.append(value)
t=pd.Series(tList)
return t
papi_df['title']=cut_title(papi_df['title'])
将视频长度划分为4个区间
lList={'00':'0-1 min','01':'1-2 min','02':'2-3 mins','24':'23-24 mins'}
papi_df['length']=papi_df['length'].map(lList)
给根据标题设置不同标签
def mtype(x):
if '大小咪' in x:
return '大小咪'
elif '大咪' in x:
return '大咪'
elif '小咪' in x:
return '小咪'
else:
return '其他'
papi_df['type']=papi_df['title'].apply(mtype)
清理后的数据如下:
papi_df.head().append(papi_df.tail())
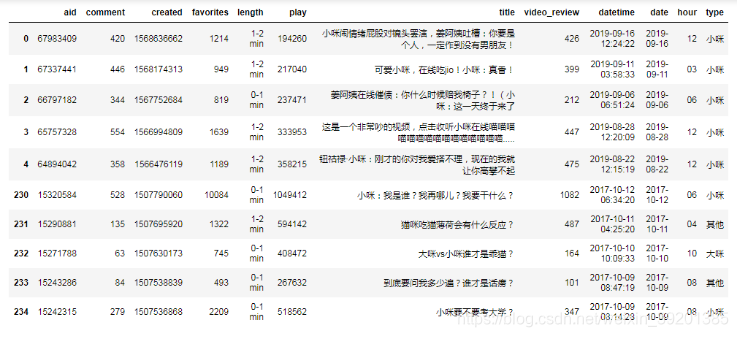
papi_df.info()

数据清理完毕
| 列名 | 含义 |
|---|---|
| aid | 视频编号 |
| comment | 视频评论数 |
| created | 视频发布时间戳 |
| favorites | 视频收藏数 |
| length | 视频时长 |
| play | 视频播放量 |
| title | 视频标题 |
| video_review | 视频弹幕数 |
| datetime | 视频发布日期和时间 |
| date | 视频发布日期 |
| hour | 视频发布时间 |
| type | 视频分类标签 |
三、数据可视化
本次使用的是pyecharts库来进行可视化。pyecharts的 API 设计简洁,使用如丝滑般流畅,支持链式调用,囊括了 30+ 种常见图表,拥有高度灵活的配置项,可轻松搭配出精美的图表。
本次分析的图标类型并不复杂,主要用到的还是饼图,折线图和柱形图。
from pyecharts.charts import Pie,Line,Bar
from pyecharts import options as opts
3.1 视频长度分析
vl=papi_df.groupby('length').size().to_dict()
vl_k=list(vl.keys())
vl_v=list(vl.values())
x_data =vl_k
y_data =vl_v
(
Pie(init_opts=opts.InitOpts(width="800px", height="500px"))
.add(
series_name="视频长度",
data_pair=[list(z) for z in zip(x_data, y_data)],
radius=["40%", "70%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="legft", orient="vertical"))
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(formatter="{b}: {c}")
)
.render_notebook()
)
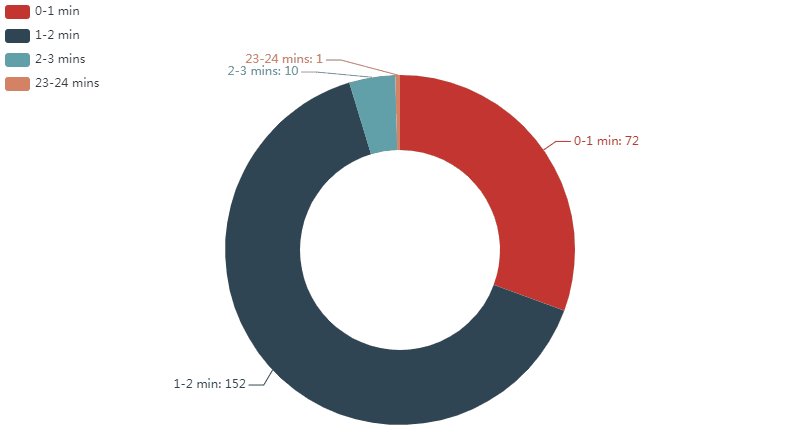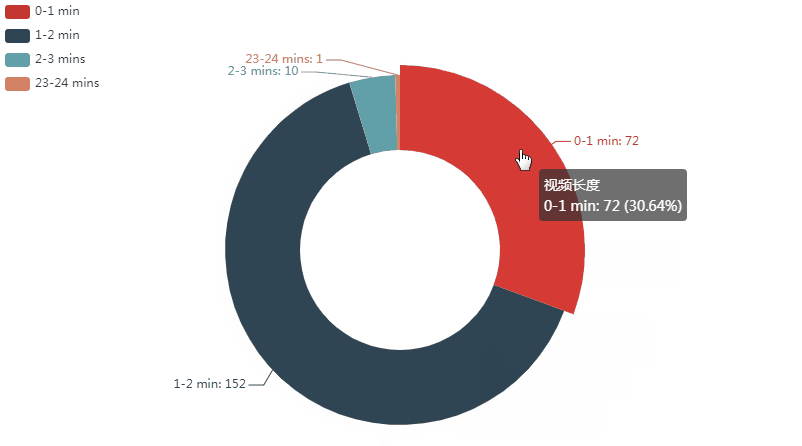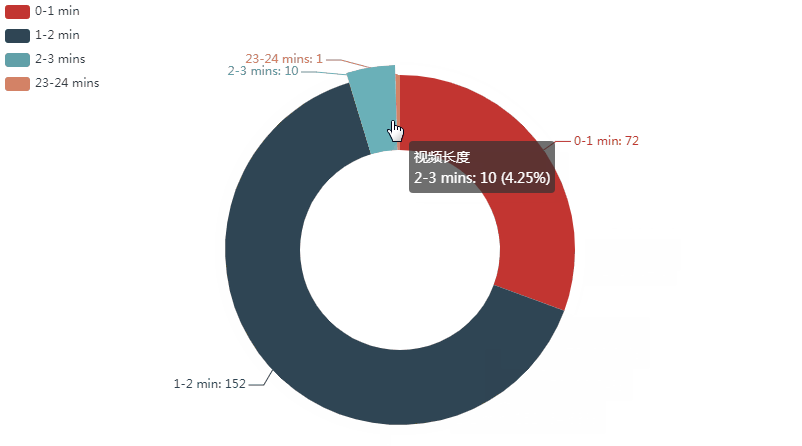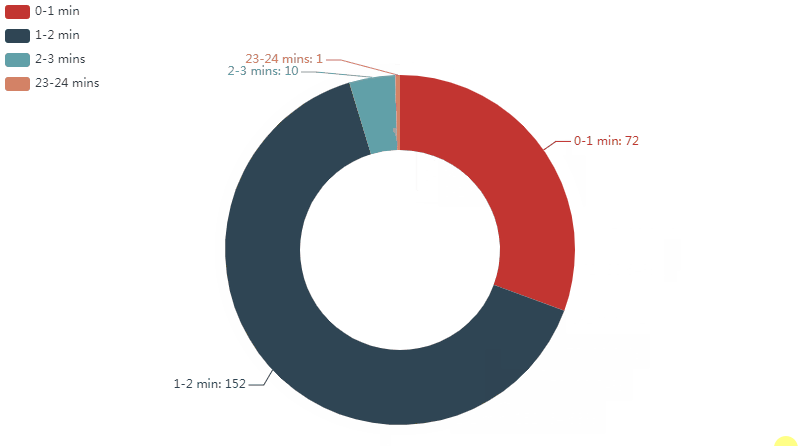
可以看到:
在已发布的视频中,时长1-2分钟的视频是最多的;占64.68%,其次是一分钟以内的,占30.64%;2-3分钟的占4.25%;最后是一个23分钟左右的视频,仅占0.43%
为什么会突然出现一支23分钟左右的视频呢?我把这个视频的信息调出来看了一下,发现这是一支发布于2019年07月23日的互动视频。
papi_df.loc[papi_df['length']=='23-24 mins']

而b站的互动视频功能是在2019年7月8日正式上线的,想必这也是papi对这个功能的一次试水吧。
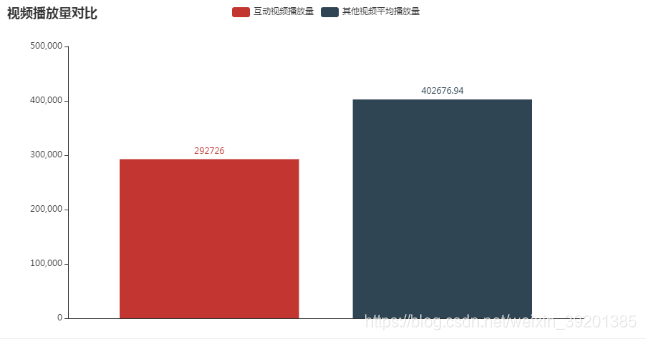
然而,可能是由于这支互动视频的播放量并没有其他视频的平均播放量高,再加上制作互动视频的工作量比较大的原因,互动视频截止到目前也只出过这一期,后续papi还是像之前那样出的是几分钟的短视频。
3.2 昵称提及频率分析
nx=len(papi_df.loc[papi_df['type']=='小咪'])
nd=len(papi_df.loc[papi_df['type']=='大咪'])
ndx=len(papi_df.loc[papi_df['type']=='大小咪'])
nq=len(papi_df.loc[papi_df['type']=='其他'])
num=[nq,nd,ndx,nx]
x_data =['其他','大咪','大小咪','小咪']
y_data =num
(
Pie(init_opts=opts.InitOpts(width="800px", height="500px"))
.add(
series_name="大小咪在标题中的提及频率",
data_pair=[list(z) for z in zip(x_data, y_data)],
radius=["40%", "70%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="right", orient="vertical"),title_opts=opts.TitleOpts(title="大小咪在标题中的提及频率"))
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(formatter="{b}: {c}")
)
.render_notebook()
)
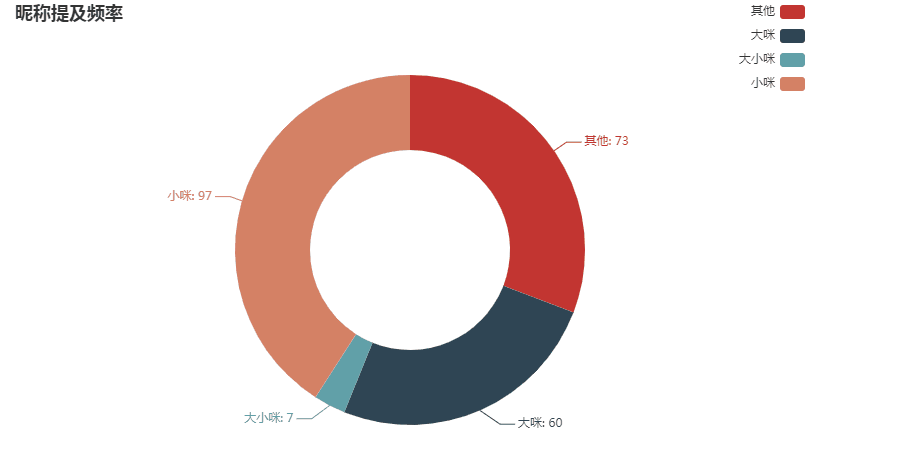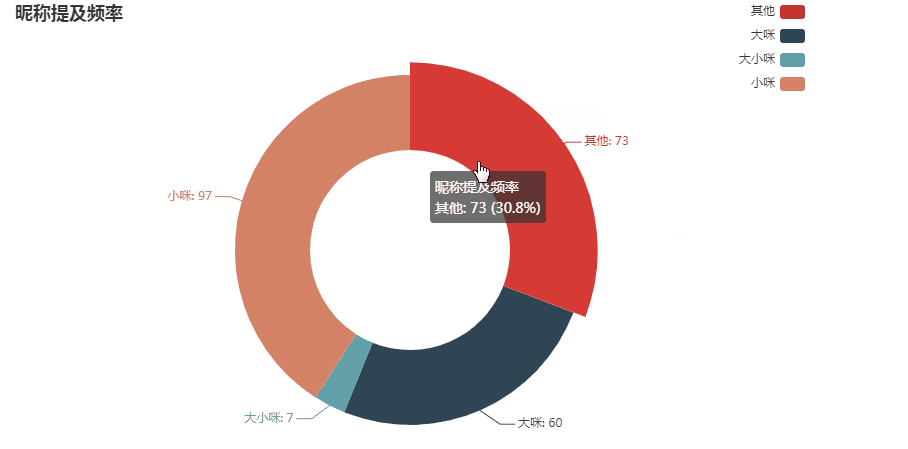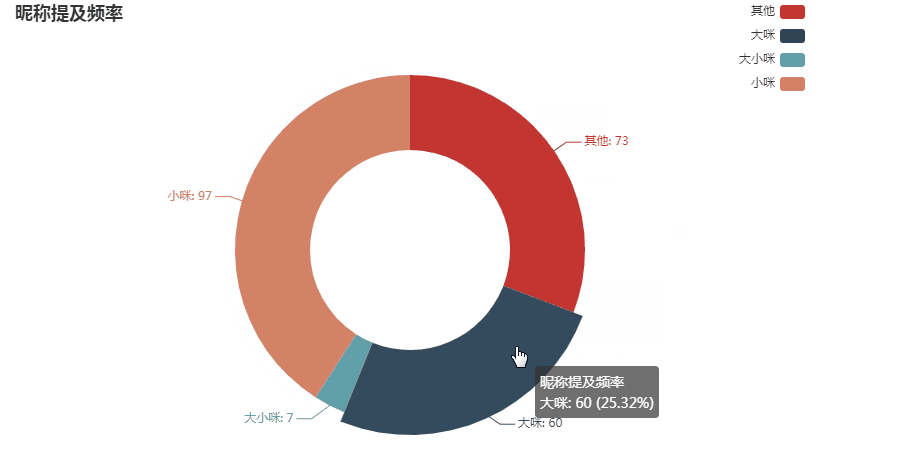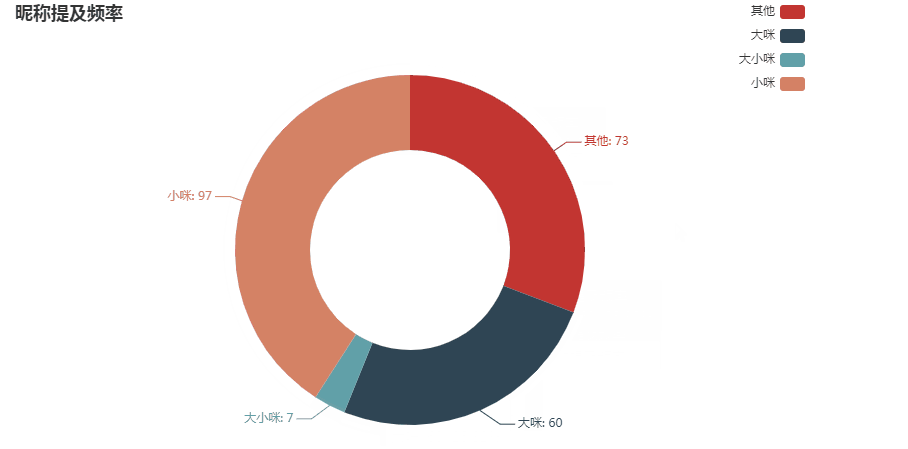
标题中小咪的提及频率最高,为40.93%;其次既没有提及大咪,也没有提及小咪的标题,占30.8%;标题中提及大咪的频率,为25.32%;同时提到大小咪的占2.95%
可见papi其实是更喜欢拍小咪的视频的。
3.3 视频标签播放量分析
play_sum=papi_df.groupby('type')['play'].sum().to_dict()
play_sum_k=list(play_sum.keys())
play_sum_v=list(play_sum.values())
play_sa_v=sum_to_avg(play_sum_v,num)
play_sa_v=[round(i,2) for i in play_sa_v]
x_data =play_sum_k
y_data =play_sum_v
(
Pie(init_opts=opts.InitOpts(width="800px", height="500px"))
.add(
series_name="各标签在播放量上的分布",
data_pair=[list(z) for z in zip(x_data, y_data)],
radius=["40%", "70%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="right", orient="vertical"),title_opts=opts.TitleOpts(title="各标签在播放量上的分布"))
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(formatter="{b}: {c}")
)
.render_notebook()
)
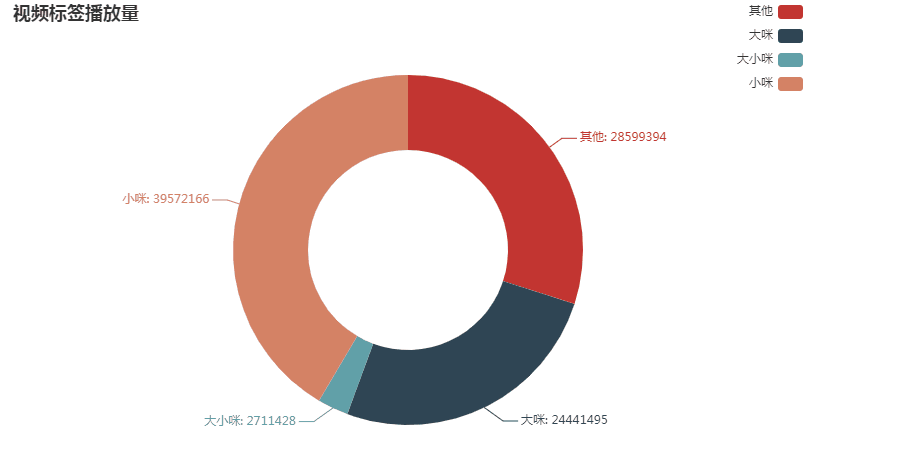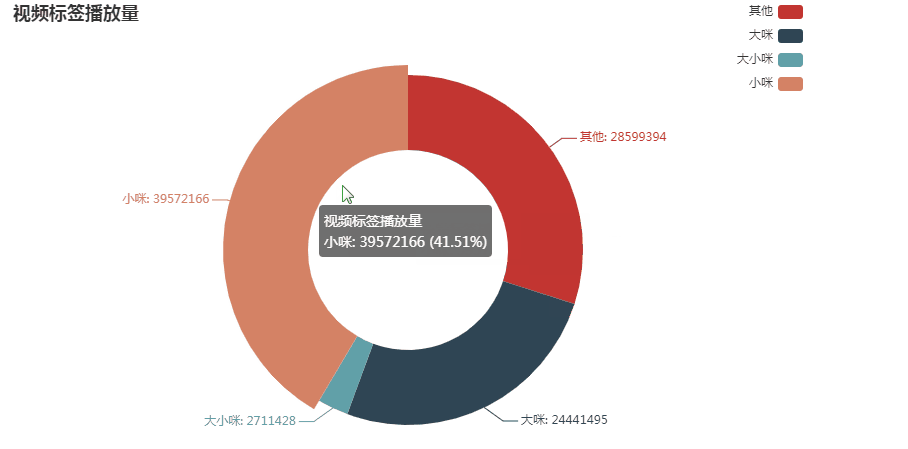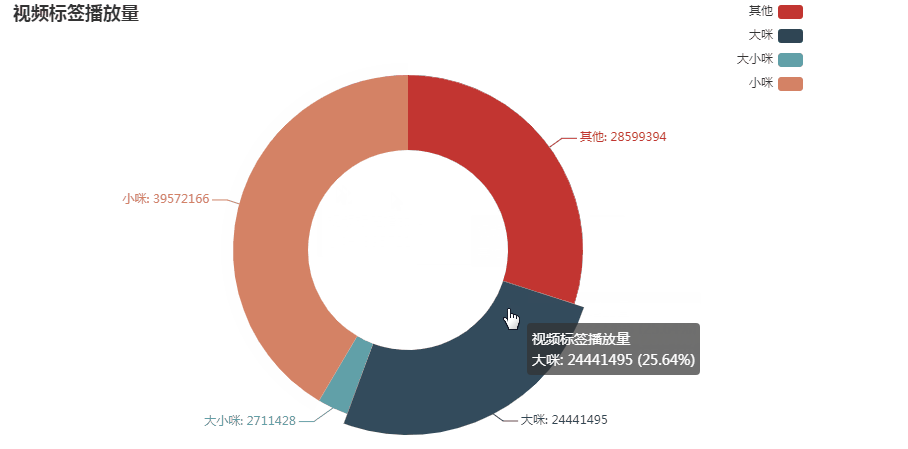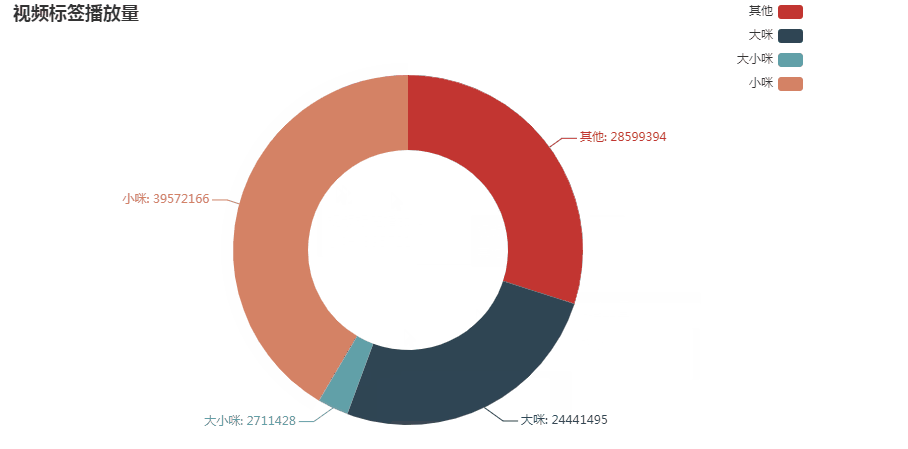
可见从播放量上看,标题中出现小咪的视频播放量占比最高,为41.51%;其次是没明确提及大咪或小咪的标题,占30%;再次是大咪,占比25.64%;最后是标题中出现大小咪的视频,播放量占比最低,为2.85%
这是否就能说明小咪的视频最受欢迎了呢?不一定,因为标题中出现小咪的视频不仅播放量高,视频的数量也是比大咪的多很多的。因此,想知道最受欢迎的是大咪还是小咪,还是得看他们各自的平均播放量:
def sum_to_avg(a,b):
c=[]
for i,j in zip(a,b):
avg=i/j
c.append(avg)
return c
favorites_sum=papi_df.groupby('type')['favorites'].sum().to_dict()
favorites_sum_k=list(favorites_sum.keys())
favorites_sum_v=list(favorites_sum.values())
favorites_sa_v=sum_to_avg(favorites_sum_v,num)
favorites_sa_v=[round(i,2) for i in favorites_sa_v]
comment_sum=papi_df.groupby('type')['comment'].sum().to_dict()
comment_sum_k=list(comment_sum.keys())
comment_sum_v=list(comment_sum.values())
comment_sa_v=sum_to_avg(comment_sum_v,num)
comment_sa_v=[round(i,2) for i in comment_sa_v]
video_review_sum=papi_df.groupby('type')['video_review'].sum().to_dict()
video_review_sum_k=list(video_review_sum.keys())
video_review_sum_v=list(video_review_sum.values())
video_review_sa_v=sum_to_avg(video_review_sum_v,num)
video_review_sa_v=[round(i,2) for i in video_review_sa_v]
bar = (
Bar()
.add_xaxis(play_sum_k)
.add_yaxis("平均播放量", play_sa_v)
.set_global_opts(title_opts=opts.TitleOpts(title="各昵称平均播放量"))
)
bar.render_notebook()
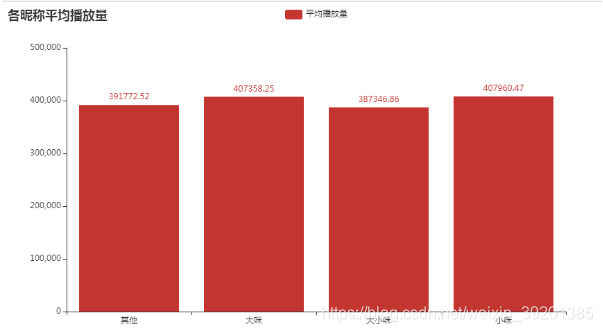
可见就平均播放量来说,标题中出现小咪的视频的平均播放量是比大咪的高的,但差距并不是特别明显。
bar = (
Bar()
.add_xaxis(play_sum_k)
.add_yaxis("收藏量", favorites_sa_v)
.add_yaxis("评论量", comment_sa_v)
.add_yaxis("弹幕量", video_review_sa_v)
.set_global_opts(title_opts=opts.TitleOpts(title="各标签的分布"))
)
bar.render_notebook()
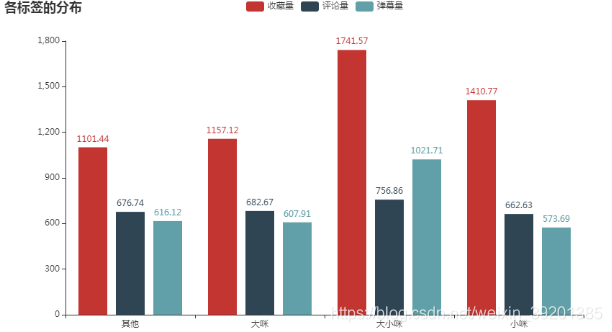
而在这个图中可以看出无论是平均收藏量、平均评论量还是平均弹幕量,都是标题中出现大小咪的时候最高;而标题中出现小咪的视频在平均收藏量上位居第二,在平均评论量和平均弹幕量上都以极小的差距落后于标题中出现大咪的视频。
可见粉丝们比较喜欢大咪和小咪同时出现的视频,而相较大咪的视频,粉丝们更喜欢收藏小咪的视频;相较小咪的视频,粉丝们更喜欢在大咪的视频中表达自己的想法。
bar = (
Bar()
.add_xaxis(play_sum_k)
.add_yaxis("评论量", comment_sum_v)
.add_yaxis("弹幕量", video_review_sum_v)
.set_global_opts(title_opts=opts.TitleOpts(title="评论>弹幕"))
)
bar.render_notebook()
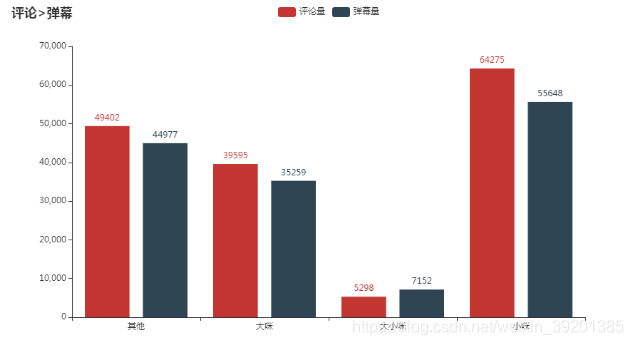
同时我也发现了,这些除了标题中出现大小咪的视频,基本上都是评论数>弹幕数。b站——一个全称“哔哩哔哩弹幕网”的知名弹幕网站,居然出现了视频的评论数>弹幕数的情况。不过弹幕区和评论区各有不同的功能——弹幕区可以针对视频的具体场景实时地表达自己的想法,而评论区则是可以留下自己的问题或想法和其他人进行互动和交流。可见大papi家的大小咪的粉丝还是更喜欢在评论区和其他粉丝一起交流互动的。
t2=papi_df.groupby('hour').size().to_dict()
t2_k=list(t2.keys())
t2_v=list(t2.values())
papi_play=papi_df.groupby('hour')['play'].sum().tolist()
x_data=t2_k
bar = (
Bar(init_opts=opts.InitOpts(width="800px", height="500px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="投稿量",
yaxis_data=t2_v,
label_opts=opts.LabelOpts(is_show=False),
)
.extend_axis(
yaxis=opts.AxisOpts(
name="播放量",
type_="value",
min_=0,
max_=24000000,
interval=4000000,
)
)
.set_global_opts(
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
yaxis_opts=opts.AxisOpts(
name="投稿",
type_="value",
min_=0,
max_=100,
interval=50,
axistick_opts=opts.AxisTickOpts(is_show=True,is_inside= True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
line = (
Line()
.add_xaxis(x_data)
.add_yaxis(
series_name="播放量",
yaxis_index=1,
y_axis=papi_play,
label_opts=opts.LabelOpts(is_show=False),
)
)
bar.overlap(line).render_notebook()
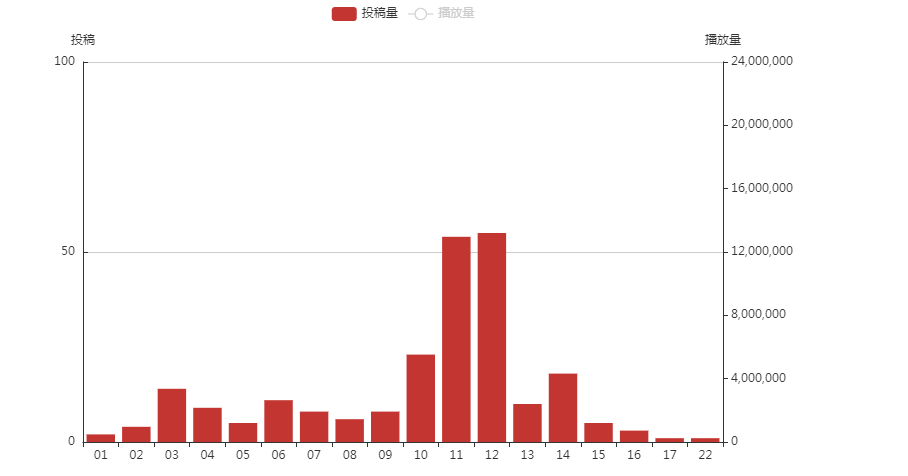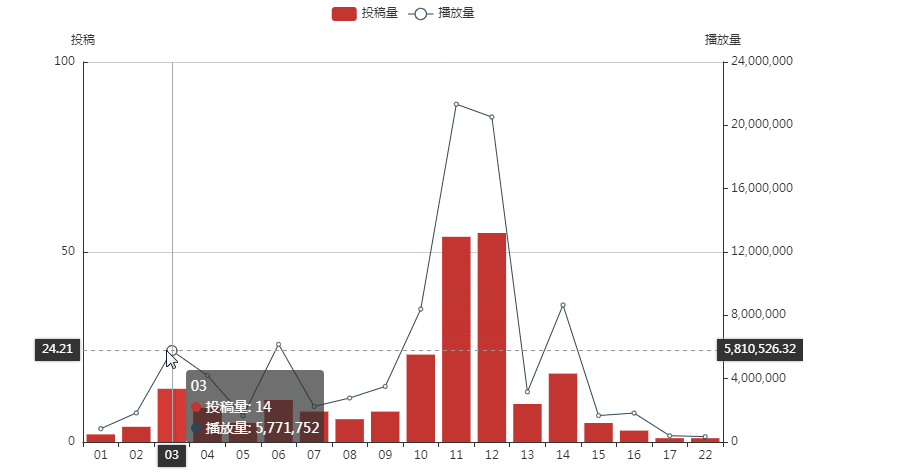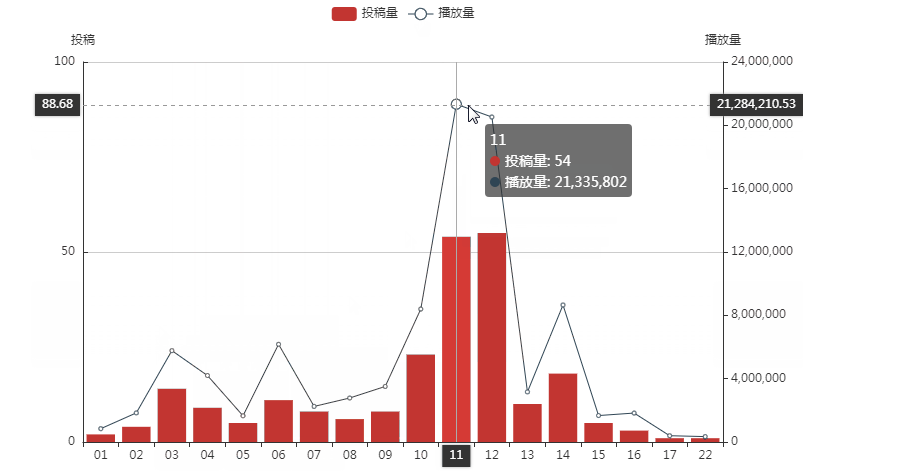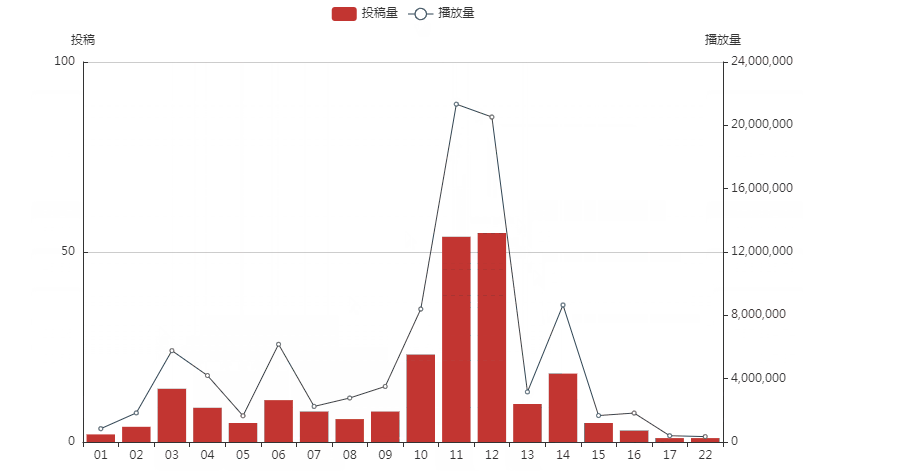
可以看出papi比较喜欢在一天的10点至12点和下午14点发布视频,视频的播放量似乎和视频的发布时间有关。有那么几个时间点值得我们关注:
(1)第一个是凌晨3点-4点的时候,papi在这个时间点发布了视频,但还是有人能在这个时间点刷到视频更新,且播放量不低,说明熬夜到凌晨三四点都还没睡的粉丝大有人在,papi本人在这个时间的投稿量也不低,也是个熬夜小能手;
(2)第二个是早上六点的时候,papi的投稿量比凌晨三点时的稍微少一点,然而播放量更高并且在凌晨4点的时候播放量极低,说明早上早起并且看b站的人还是比熬夜看b站的人要多的;
(3)第三个是中午11-12点左右的时候,投稿量和播放量都很高,但是11点时尽管投稿量比12点时低,播放量还是比12点左右的要高不少,所以11点左右比较适合发布视频。
(4)第四个是14点左右时,播放量第三高,也可以考虑多在这个时间点投稿。
总的来说,发布视频的最好的时间点应该是在上午11,中午12点和下午14点左右。
3.4 视频更新频率分析
papi_df['ynm']=papi_df['datetime'].apply(lambda x:''.join(x.split('-')[:2]))
papi_df['ynm']
ynm=papi_df.groupby('ynm').size().to_dict()
x_data =ynm.keys()
y_data =ynm.values()
(
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
title_opts=opts.TitleOpts(title="每月更新视频数量"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="视频更新频率曲线",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
)
.render_notebook()
)

由上图可见:
papi在2018年5月的投稿数量为17个,是这三年里一个月内投稿数量最多的一次了。之后投稿数量虽然偶尔会有上升,但总体上来说还是呈下降趋势,基本上每月投稿数量都在10个以下,近几个月投稿数量基本是在5-8这个区间。
四、papi家的大小咪是否喜欢参加b站的活动?
b站会经常组织一些活动来鼓励up主投稿,并且会对参与的up主提供提供一些奖品。我在b站的活动中心翻找了一下,在今年的活动中找到了4个有关宠物或者猫咪的活动,还有一个有关互动视频的活动。
分别是:《bilibli年度猫片》、《中华气死猫》、《动物圈最靓的仔》、《猫咪迷惑行为大赏》和《互动视频大赏》。
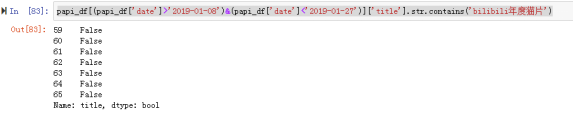
首先来看下《bilibli年度猫片》

papi_df[(papi_df['date']>'2019-01-08')&(papi_df['date']<'2019-01-27')]['title'].str.contains('bilibili年度猫片')
《中华气死猫》
《动物圈最靓的仔》

《猫咪迷惑行为大赏》

可以看到这几个关于猫咪或宠物的活动papi都没有参加。
《互动视频大赏》


可以看到papi的互动视频投稿日期为7月23日,,而活动投稿时间为8月15日至9月16日,因此不符合参加条件。
那么papi家的大小咪真的没有参加过b站的活动吗?其实是有的
papi_df[papi_df['title'].str.contains('#')]
 可以看到papi家的大小咪在2018年8月和9月份都有参加b站一个叫《喵战2018》的活动,并且在活动中进了10强,但遗憾的是并没有获得冠军。不过这个比赛里进前十的up中有半数并非是专业播猫用户,而是靠人气上位了,引起了一些b站用户的不满和质疑。看来b站还是要吸取教训,以后在其他比赛里更加注重比赛规则的制定,或者在统计票数时根据up主类型来调整排名权重。
可以看到papi家的大小咪在2018年8月和9月份都有参加b站一个叫《喵战2018》的活动,并且在活动中进了10强,但遗憾的是并没有获得冠军。不过这个比赛里进前十的up中有半数并非是专业播猫用户,而是靠人气上位了,引起了一些b站用户的不满和质疑。看来b站还是要吸取教训,以后在其他比赛里更加注重比赛规则的制定,或者在统计票数时根据up主类型来调整排名权重。
综上所述,可以看出papi确实不太喜欢参加b站的活动而是喜欢照自己的喜好或心情来投稿视频,并且当b站出现新的活动玩法时她也喜欢率先去尝试。
结论
通过从视频长度、投稿数量、昵称提及频率、视频上传时间等角度,我对该数据集进行了一个初步的探索,可以得到一些有趣的结论。
(1)从视频时间长短的角度来说,短视频还是比长时间的互动视频更受欢迎,且就papi而言,她也还是比较喜欢发短视频;
(2)papi在标题中提及小咪的频率特别高,虽然在视频中papi总是对大咪穷追不舍,但从数据上看papi还是更喜欢拍摄小咪的视频的;
(3)粉丝更喜欢点击观看并收藏有关小咪的视频,因此可以多发布一些小咪的视频;
(4)粉丝们相比发弹幕,更喜欢在评论区表达自己的想法并与其他粉丝一起互动和交流;
(5)在10点-14点之间投稿播放量会比较可观,建议在上午11点左右投稿;
(6)papi不太会刻意去参加b站的视频投稿活动,而是随心所欲地发布大小咪的日常生活,当有新的视频玩法时也会主动参与;
(7)该账号的更新频率有下降的趋势,近几个月的更新频率基本都是月更10个视频以下,很可能在5-8个视频这个范围。

















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









