







Hadoop安装方法:单机版、伪分布式、完全分布式
Apache hadoop三种架构的介绍(standAlone,伪分布式,分布式环境介绍以及安装)
一)standAlone 单机版
1、下载安装包
tar -xzvf hadoop-2.7.5.tar.gz -C /export/servers/
2、修改配置文件
hadoop-2.7.5/lib/native:本地库,里面包括C程序和一些压缩的支持
bin/hadoop checknative 检测hadoop的本地库,是否支持
默认的Apache的版本的压缩方式,snappy不支持。snappy是谷歌提供的一种压缩算法。如果压缩的太厉害了,解压的时候小号CPU较大。
cd /etc/hadoop
1)修改core-site.xml:
核心配置文件,主要定义了我们集群是分布式还是本地运行
<configuration>
<property>
<name>fs.default.name</name> //配置NN节点地址和端口号
// hdfs://表示我们使用分布式的文件系统的实现,决定了我们的namenode在哪一台机器上
<value>hdfs://192.168.116.100:8020</value> //注意格式必须是host:port的形式
</property>
<property>
<name>hadoop.tmp.dir</name> //hadoop临时目录用来存放nn临时文件
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempData</value> //该目录必须预先手工创建不能删除
</property>
</configuration>
2)修改hdfs-site.xml
分布式文件系统的核心
<configuration>
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<!--50070这个端口定义的是我们通过浏览器来访问我们的好歹是的端口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<!-- 定义了我们元数据的fsimage的存储路径,fsimage就是我们 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
3) 修改hadoop-env.sh
修改JDK的home路径
export JAVA_HOME=/export/servers/jdk1.8.0_141
4)修改maprd-site.xml
定义了我们关于MapReduce的参数
<configuration>
<!-- 指定我们MapReduce运行的框架是yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MapReduce的小任务模式开启 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 定义了jobhistory的通信地址,jobhistory是我们查看历史完成的信息 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<!-- 浏览器界面查看的地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
修改maprd-site.sh
修改javahome可以不修改
5) 修改yarn-site.xml
定义yarn集群
<configuration>
<!--定义了resourceManager所在的机器 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--开启日志的聚集功能,可以让我们在19888jobhistory的 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
6)修改slaves
定义了我们从节点是哪些机器,datanode,nodemanager
3、启动集群
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
hdfs格式化
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
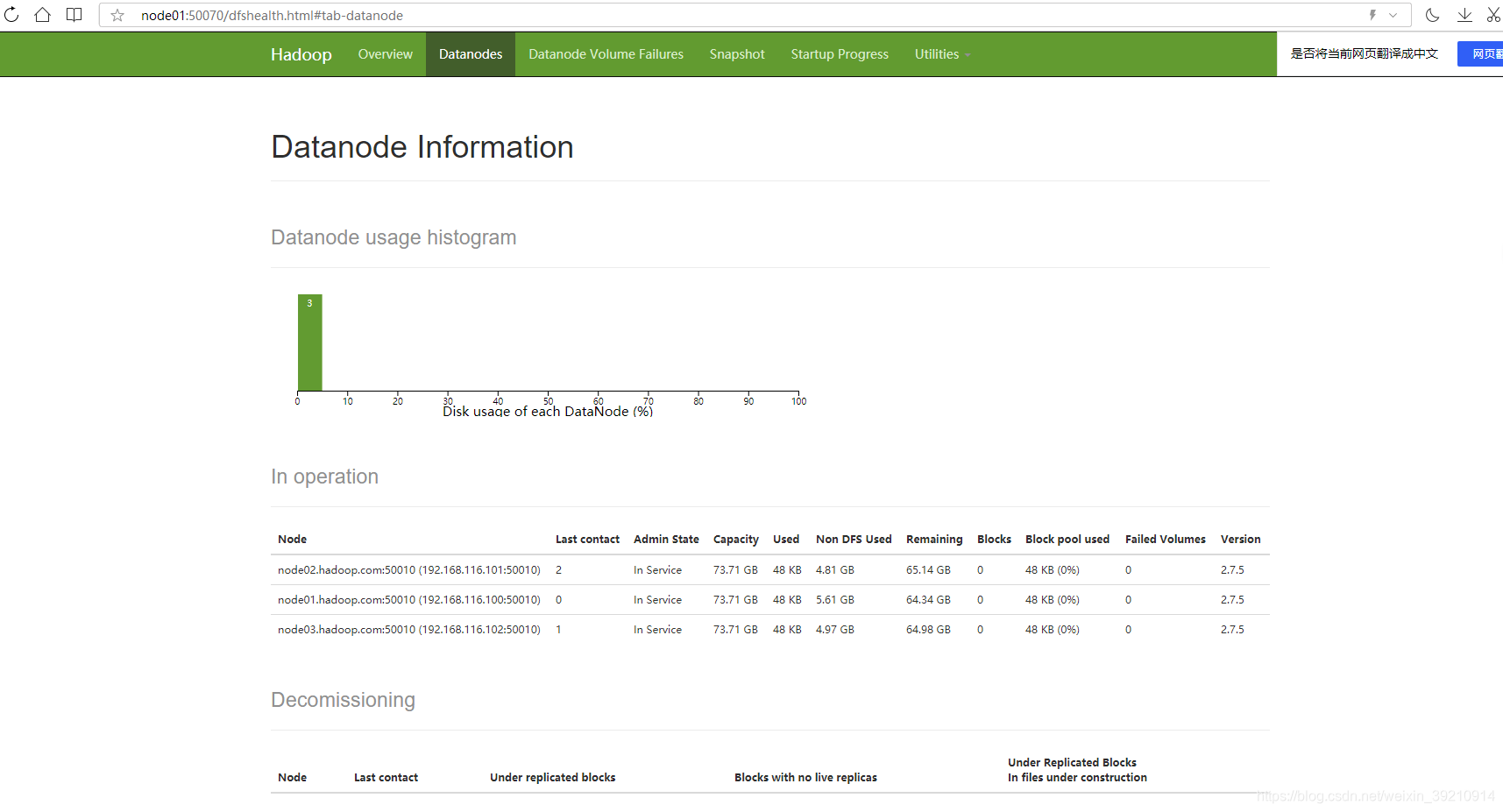
node01:/50070: 查看hsfd集群
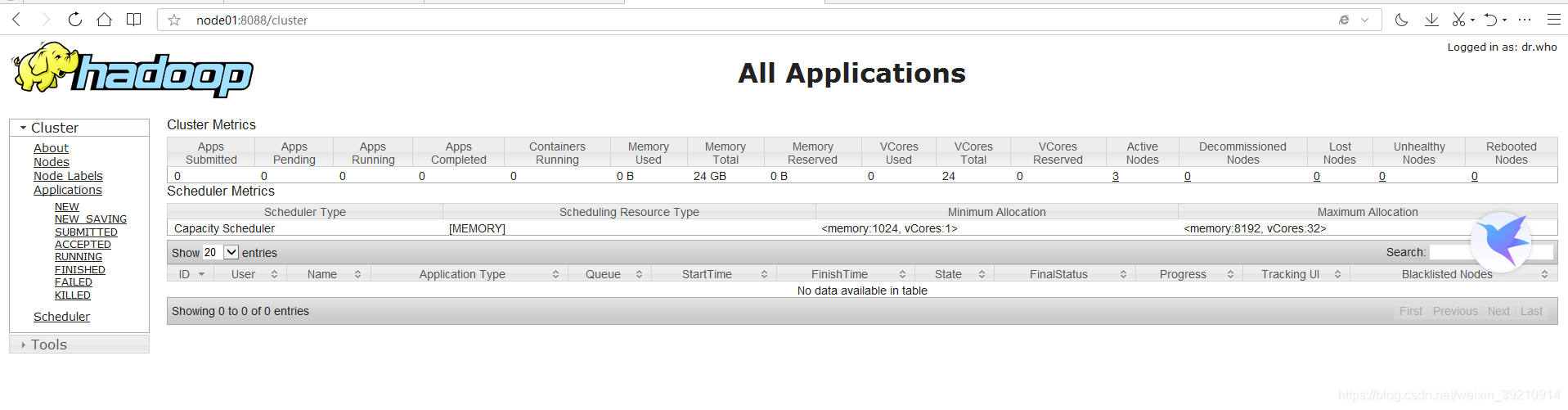
node01:/8088:yarn集群
node01:/19888:历史任务集群

二)伪分布式
主节点在一台机器上,从节点分开到其他机器上。借助三台机器实现
停止单节点集群,删除/export/servers/hadoop-2.7.5/hadoopDatas文件夹
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/
sbin/stop-dfs.sh
sbin/stop-yarn.sh
sbin/mr-jobhistory-daemon.sh stop historyserver
删除hadoopDatas文件夹然后重新建
rm -rf hadoopDatas/
重新创建文件夹
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
修改slave文件,然后将安装包发送到其他机器,重新启动集群即可
第一台机器执行:
cd etc/hadoop/
vim slaves
#添加多个node节点
#node01
#node02
#node03
scp -r hadoop-2.7.5/ node02:/export/servers/
scp -r hadoop-2.7.5/ node03:/export/servers/
启动:第一台机器执行
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
成功!!!
三)完全分布式
主节点全部分散到不同的机器,一个namenode active占用一台机器, namenodestandby 占用一台机器,resource manager active占用一台,resource standby占用一台机器
停止之前的hadoop集群的所有服务 kill,并删除所有机器的hadoop安装包,然后重新解压hadoop压缩包。
第一台机器
tar -xzvf hadoop-2.7.5.tar.gz -C /export/servers/
修改6个配置文件
把第一台机器改好的发往node02和node03
三台机器新建文件夹和文件
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/name
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/name
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/edits
修改第二台机器的yarn-site.xml
vim yarn-site.xml
启动集群
bin/hdfs namenode -formatZK
sbin/hadoop-daemons.sh start journalnode
bin/hdfs namenode -format
bin/hdfs namenode -initializeSharedEdits -force
sbin/start-dfs.sh
第二台
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemons.sh start namenode
sbin/start-yarn.sh
第三台
sbin/start-yarn.sh
有















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









