







1 namedtuple
自定义一个可以命名的tuple对象,自定义tuple数量,通过属性引用而非索引。
import collections
mytuple = collections.namedtuple('Test',['x','y'])
print(mytuple)
print(mytuple.x)
new = mytuple(1,2)
print(new)
print(new.x)
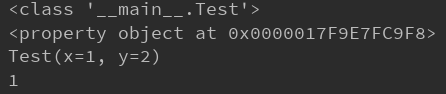
定义了mytuple的对象以后,显示其为main.Test的类。其属性包括x,y存在分配的内存空间。
将其进行实例化,得到我们定义的Test对象,可以通过调用.x .y获取其属性。
**简而言之,生成一个可以实例化的 自定义类,附带自定义的属性。**统一使用str
2 deque
deque可以看做一种类数组,队列,栈的数据结构。均是可以模拟生成的
包含pop() append() popleft() appendleft()等方法用以模拟其他数据结构;同时可以通过索引来获取值。
myqueue = collections.deque()
print(myqueue)
myqueue.append(1)
print(myqueue)
print(myqueue[0])
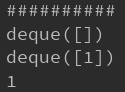
简而言之,可以看做是一个具有更多方法的list。
3 defaultdict
可以看做一个字典,唯一区别在于,可以自定义工厂函数,在没有key的时候返回自定义的数值(dict里面不存在时会返回 keyerror),如果使用get直接返回None
mydefault = collections.defaultdict(set)
print(mydefault)
mydefault['a'] = 1
print(mydefault['a'])
print(mydefault['b'],'##')
print(mydefault.get('b'),'##')#return None
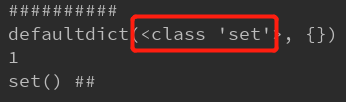
经典题目:
自定义前置树实现单词的搜索(百度)或者词汇和谐等功能(前缀树):
208. Implement Trie (Prefix Tree)
Implement a trie with insert, search, and startsWith methods.
Example:
Trie trie = new Trie();
trie.insert(“apple”);
trie.search(“apple”); // returns true
trie.search(“app”); // returns false
trie.startsWith(“app”); // returns true
trie.insert(“app”);
trie.search(“app”); // returns true
Note:
You may assume that all inputs are consist of lowercase letters a-z.
All inputs are guaranteed to be non-empty strings.
class TrieNode:
# Initialize your data structure here.
def __init__(self):
self.children = collections.defaultdict(TrieNode)
self.is_word = False
print('##########')
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
current = self.root
for letter in word:
current = current.children[letter]
current.is_word = True
def search(self, word):
#print(self.root)
current = self.root
for letter in word:
current = current.children.get(letter)
print(current,'?????')
if current is None:
print('???')
return False
return current.is_word
def startsWith(self, prefix):
current = self.root
for letter in prefix:
current = current.children.get(letter)
if current is None:
return False
return True
su = Trie()
su.insert('leetcode')
su.insert('letsgo')
res = su.search('leetcodea')
print(res)
意思是,内层具备一个字典树,然后一路套娃下去。get 返回None时直接return False。精准搜索时需要判断内置属性Is_word得到这个点是否是单词的结尾。
注意:class TrieNode里面defaultdict(TrieNode)。意思每层生成以后内部的value依然可以作为字典套娃下去。
4 OrderedDict
字典是排序的,按照插入的顺序进行排序。
myorder = collections.OrderedDict()
print(myorder)
myorder['a']=3
myorder['c']=1
myorder['b']=2
print(myorder)
myorder['a']=6
print(myorder)
myorder.move_to_end('a')
print(myorder)
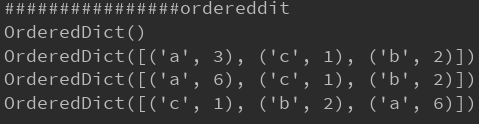
普通dict会出现无序情况,排序字典根据key设置的顺序生成。
使用move_to_end()可以做到key的移位。
LRU的原理
146. LRU Cache
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
The cache is initialized with a positive capacity.
Follow up:
Could you do both operations in O(1) time complexity?
Example:
LRUCache cache = new LRUCache( 2 /* capacity */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // returns 1
cache.put(3, 3); // evicts key 2
cache.get(2); // returns -1 (not found)
cache.put(4, 4); // evicts key 1
cache.get(1); // returns -1 (not found)
cache.get(3); // returns 3
cache.get(4); // returns 4
一旦出现新的数据,就调用move_to_end函数实现更新。
代码:
def __init__(self, capacity):
self.dic = collections.OrderedDict()
self.remain = capacity
def get(self, key):
if key not in self.dic:
return -1
v = self.dic.pop(key)
self.dic[key] = v # set key as the newest one
return v
def set(self, key, value):
if key in self.dic:
self.dic.pop(key)
else:
if self.remain > 0:
self.remain -= 1
else: # self.dic is full
self.dic.popitem(last=False)
self.dic[key] = value
5 ChainMap
ChainMap(a,b,c)将三个字典组合起来
略
6 Counter
将字符串进行一个count的字典分配,key为字符,value为个数。
例题:词汇表与字母表
1160. 拼写单词
给你一份『词汇表』(字符串数组) words 和一张『字母表』(字符串) chars。
假如你可以用 chars 中的『字母』(字符)拼写出 words 中的某个『单词』(字符串),那么我们就认为你掌握了这个单词。
注意:每次拼写时,chars 中的每个字母都只能用一次。
返回词汇表 words 中你掌握的所有单词的 长度之和。
示例 1:
输入:words = [“cat”,“bt”,“hat”,“tree”], chars = “atach”
输出:6
解释:
可以形成字符串 “cat” 和 “hat”,所以答案是 3 + 3 = 6。
示例 2:
输入:words = [“hello”,“world”,“leetcode”], chars = “welldonehoneyr”
输出:10
解释:
可以形成字符串 “hello” 和 “world”,所以答案是 5 + 5 = 10。
提示:
1 <= words.length <= 1000
1 <= words[i].length, chars.length <= 100
所有字符串中都仅包含小写英文字母
import collections
class Solution:
def countCharacters(self, words, chars: str) -> int:
char_dict = collections.Counter(chars)
res = 0
for word in words:
word_dict = collections.Counter(word)
for key in word_dict.keys():
if key not in char_dict:
break
elif word_dict[key]>char_dict[key]:
break
else:
continue
else:
res+=len(word)
return res
tips:
1 for else:执行的条件为for循环执行完以后执行else。如果for中遇到break则不执行!
2 Counter.update(word), Counter(word)都能实现分解一个字符串。















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









