







日常学习记录——封校期的学习日常
前言
每天都为自己的个人项目做一点工作,而不是集中在每个周末。——《Write Code Every Day》
这篇博客为宿舍区封控后的第一个工作日上午的学习内容总结。
1 继承和组合 ——《笨方法学python3》练习44
1、隐式继承:对子类的行为意味着对父类的行为。
2、显示继承:子类上的操作会覆盖父类上的操作。
3、修改前后:显示继承的特殊形式,在父类版本运行之前或之后更改行为。
1.1 示例代码1
class Parent(object):
def implicit(self):
print("PARENT implicit()")
def override(self):
print("PARENT override()")
def altered(self):
print("PARENT altered()")
class Child(Parent):
def override(self):
print("CHILD override()")
def altered(self):
print("CHILD, BEFORE PARENT altered()")
super(Child, self).altered()
print("CHILD, AFTER PARENT altered()")
dad = Parent()
son = Child()
dad.implicit()
son.implicit()
dad.override()
son.override()
dad.altered()
son.altered()
1.2 示例代码2
class Other(object):
def override(self):
print("OTHER override()")
def implicit(self):
print("OTHER implicit()")
def altered(self):
print("OTHER altered()")
class Child(object):
def __init__(self):
self.other = Other()
def implicit(self):
self.other.implicit()
def override(self):
print("CHILD, override()")
def altered(self):
print("CHILD, BEFORE OTHER altered()")
self.other.altered()
print("CHILD, AFTER OTHER altered()")
son = Child()
son.implicit()
son.override()
son.altered()
2 XGBoost分类算法
2.1 参考文献
1、基本原理和实现代码:机器学习集成学习之XGBoost(基于python实现)。
2、XGBoost库安装命令pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xgboost:python安装xgboost的方法。
2.2 实例代码
基于XGBoost算法的鸢尾花三分类模型实例:
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123456) # 数据集分割
# 算法参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax',
'num_class': 3,
'gamma': 0.1,
'max_depth': 6,
'lamda': 2,
'subsample': 0.7,
'colsample_bytree': 0.75,
'min_child_weight': 3,
'slient': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items()) # 由于版本更新这个是需要注意的
dtrain = xgb.DMatrix(X_train, y_train, feature_names=iris.feature_names) # 生成数据格式,不加feature_names图表显示就是f0-f3
num_rounds = 500
model = xgb.train(plst, dtrain, num_rounds) # sgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test, feature_names=iris.feature_names)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("accuarcy:%.2f%%" % (accuracy * 100.0))
# 显示重要特征
plot_importance(model)
plt.show()
2.3 运行结果
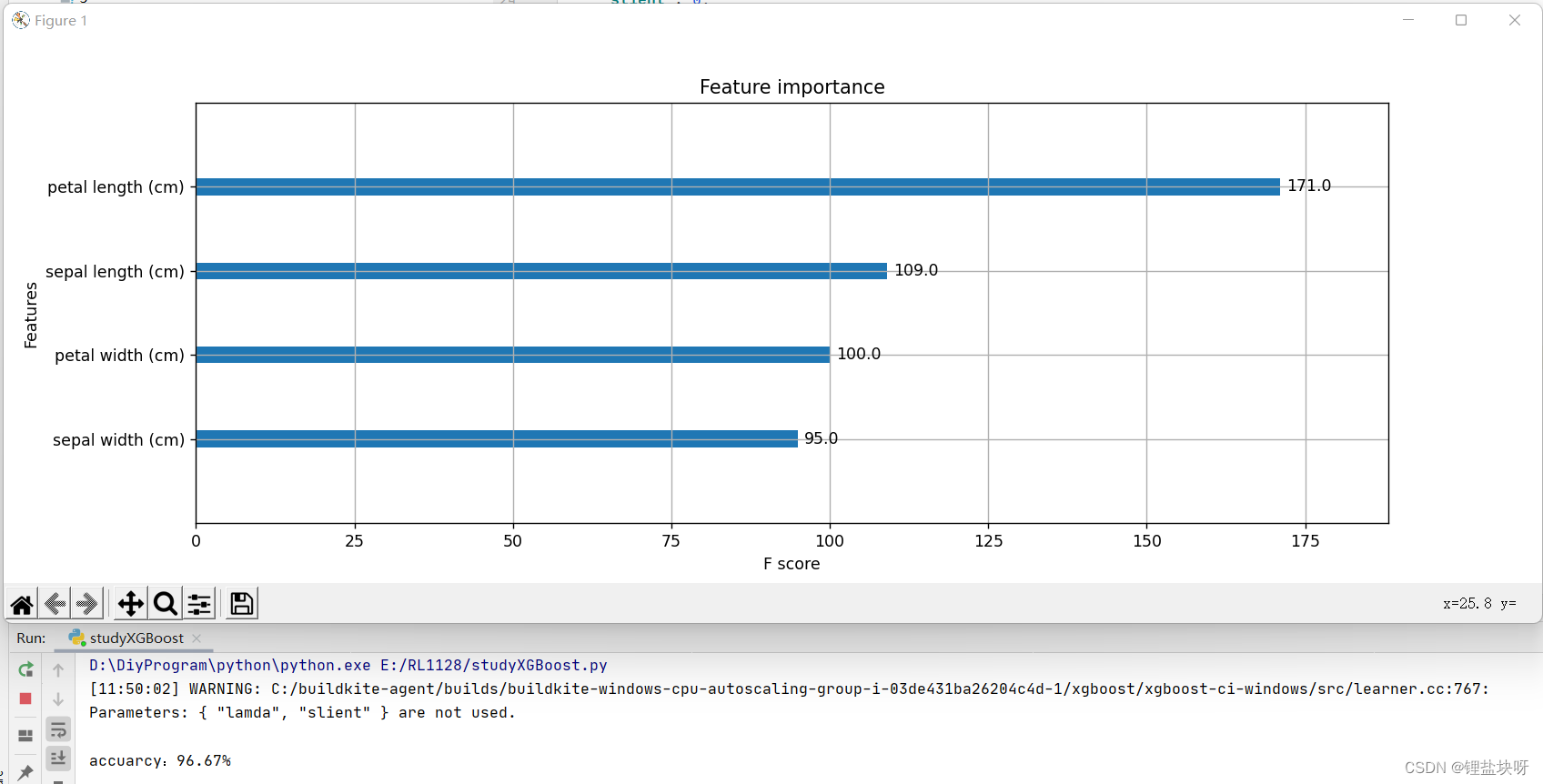
分类准确率为96.67%,重要分类特征如下所示,也就只有4个特征属性。
3 Use Brain Every Day
参考文献:编程每一天(Write Code Every Day)。
3.1 John Resig的规则 —— Write Code Every Day
- 每天编写代码。可以撰写文档、博客或者做其他任何事情,但必须在写完代码以后;
- 代码必须可用。无需调整缩进,无需重新格式化,尽可能无需重构;
- 所有代码必须在午夜写完。
- 代码必须开源在GitHub上。
3.2 锂盐块的规则 —— Use Brain Every Day
-
每天活动一下脑子。
可以是看别人的代码然后绘制自己理解版本的流程图;
可以是写自己那还不成熟程序的文档;
可以是敲一遍别人成熟的代码;
只要在思考,在动脑筋就行。 -
尽可能写读书笔记,要留痕。包括但不局限于:
读书笔记,摘抄别人论文或者博客里面的内容;
思路文档:问题记录;
录制视频:过程记录;
情绪抽离去观察自己的学习状态。 -
思路系统化。
组会汇报;
文档汇报;
随便抓个人当我的思路梳理者;
博客分享。
总结
平凡的脚步,也可以走完伟大的行程。
1、今天把不感兴趣、一直完成不了的练习43给跳过去了,直接跳到练习44,还可以,能有输出,至于理解的对不对,那就再慢慢学了,反正要继续深入的话总有一天还会绕回到这个问题上去理解他。
2、搞了一点新东西,尝试了一下XGBoost,不过原理啥的还没有仔细看过,秉承一贯的作风跑起来再说;
3、模仿是我的强项,但必须得了解自己的需求再去对标合适的人和流程,不能什么都要,而且有的东西必须要突破自己的心理障碍,去干碎它,一点点地去瓦解它。给时间一点时间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









