






前言
又在b站上看了看视频看到有大神讲解爬虫,心血来潮就自己研究研究。花了很长时间才弄懂原理。本人比较笨,写这个的话希望能给像我们这些小白玩一玩知道一下原理。顺便自己当着笔记。大神不要笑话。
准备工作
一个python3的环境,一个编译器,requests库。
因为requests库是第三方库,我们需要pip下载来。
pip3 install requests
ps:python3环境搭建包括编译器网上很多大神会分享自行百度一下,还有pip3也是需要安装很简单的百度一下,很多很好的大神作业。
然后查看一下我们是否安装好requests库
pip3 list
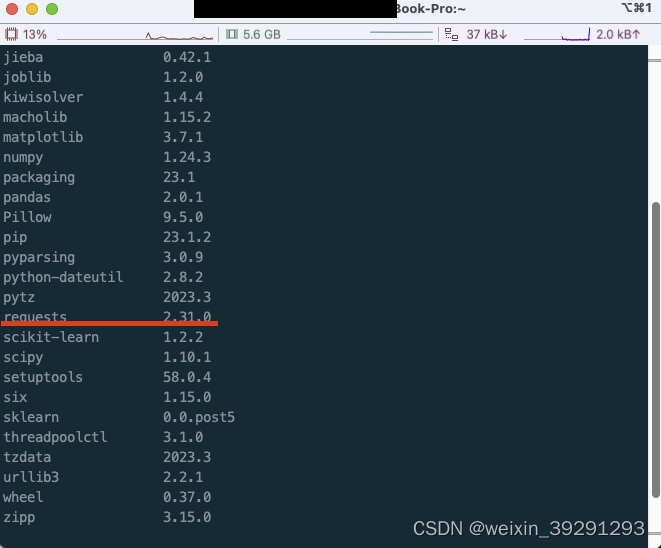
看很简单的
1.开始工作咯
会用到的库
import requests
import re
因为基于一个爬虫网站所以用这么简单的就可以啦分享一下
https://ssr1.scrape.center/
用chrome打开这个网站,并选择第一tab。复制一下头文件信息
记录好这两个数据,一会有用
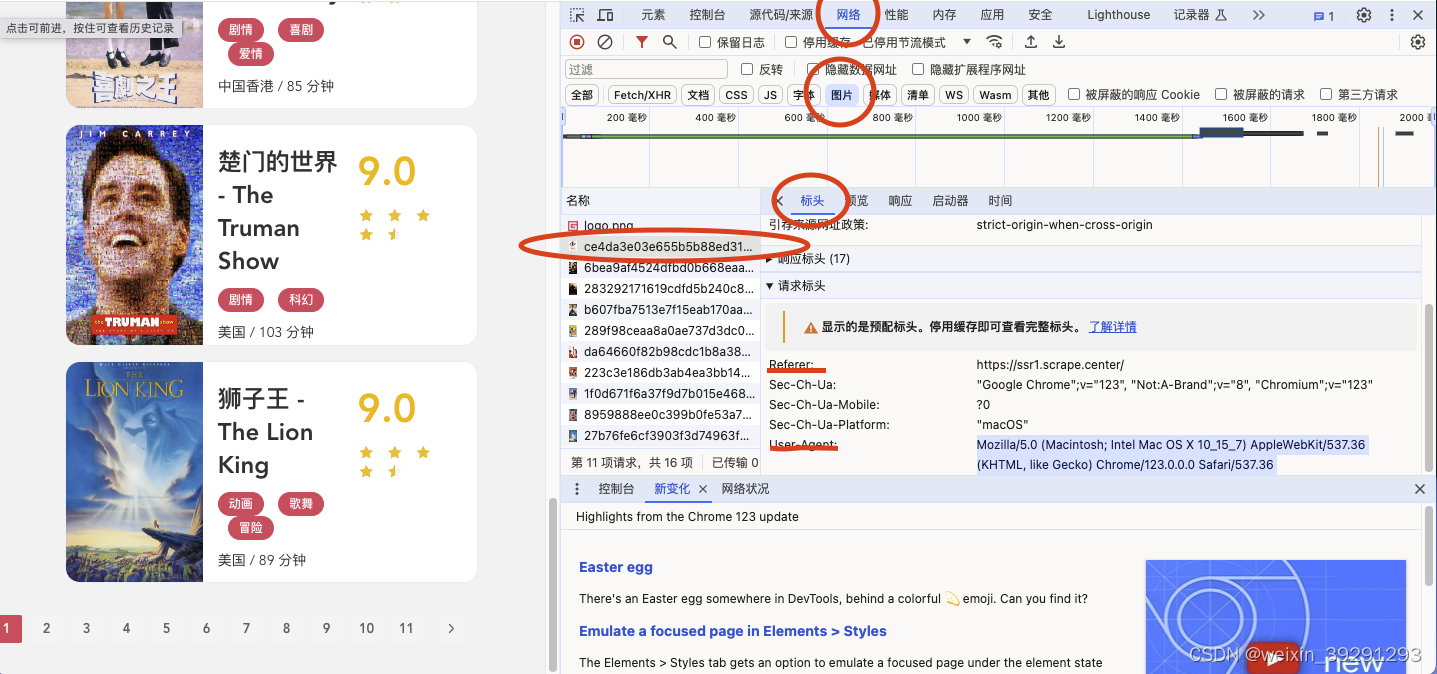
import requests #这个库方便我们下载资源
import re #这个是用来处理html的数据
url = 'https://ssr1.scrape.center/page/1' #这个是要爬的地址
#把刚才复制好的数据填进去
header = {'Referer':'xxxxxx','User-Agent':'xxxxxxx'}
#写个简单的下载组件
def downlaodWeb(url,header): #这个类需要两对象一个是地址,一个是头文件
#用response接受requests.get传回来的数据
response =requests.get(url=url, headers = header)
#最后把获取到的数据原封不动返回出来
return response
#我们需要下载网页代码看看我们的图片地址包括名字信息在哪里
#这里的url对应一开始设置的变量,html接受返回的数据,(.text)是requests一个方法
html = downlaodWeb(url, None).text
#获取图片的地址,获取src=这个图片的地址
picUrl = re.findall(r'src="(.*?)"', html)
#发现里面有一个logo的图片,这个不需要我们去取它
picUrl.pop(0)
#获取图片对应的名字,方便我们命名
picName = re.findall(r'<h2 data-v-7f856186="" class="m-b-sm">(.*?)</h2>', html)
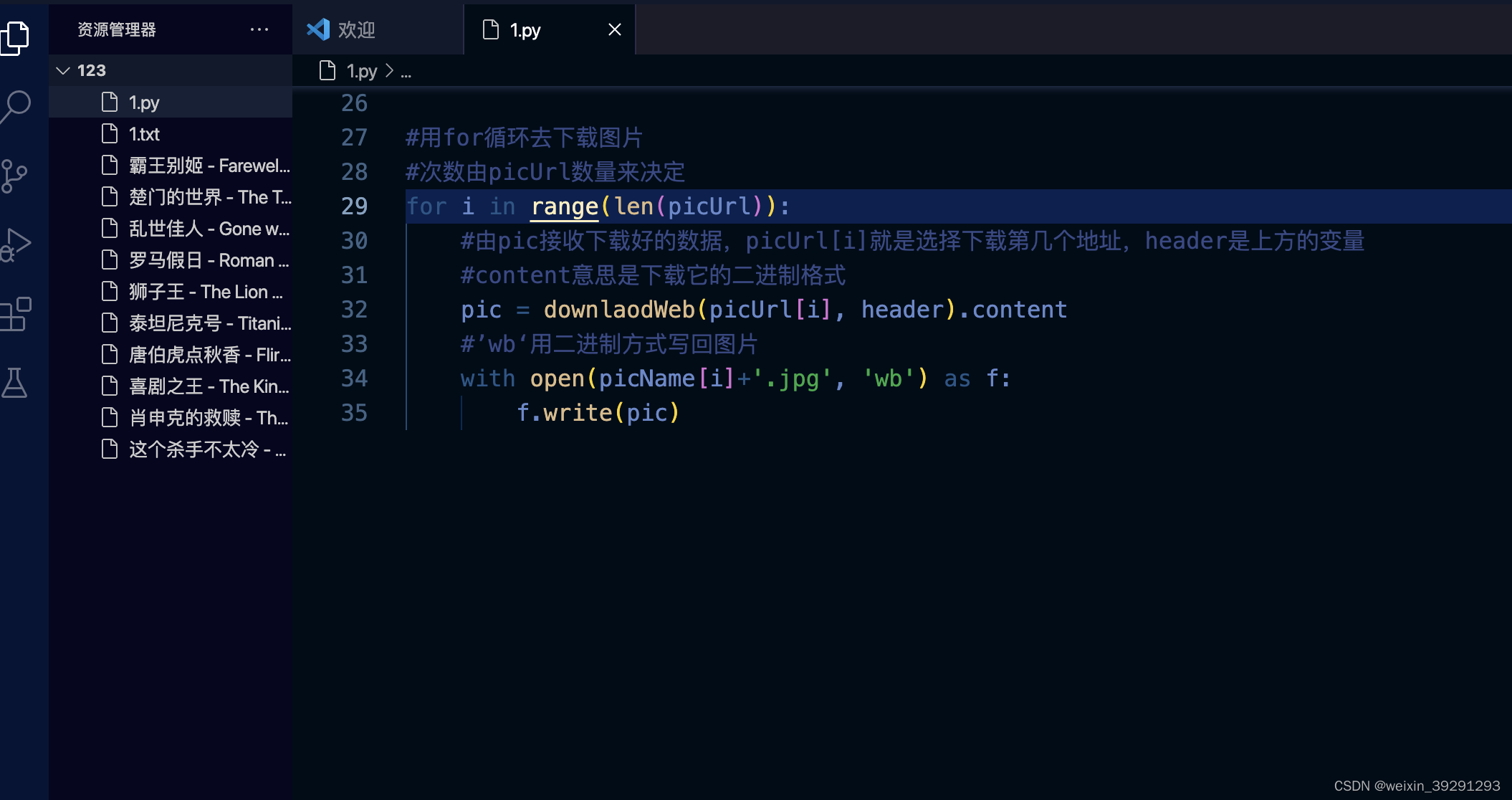
#用for循环去下载图片
#次数由picUrl数量来决定
for i in range(len(picUrl)):
#由pic接收下载好的数据,picUrl[i]就是选择下载第几个地址,header是上方的变量
#content意思是下载它的二进制格式
pic = downlaodWeb(picUrl[i], header).content
#’wb‘用二进制方式写回图片
with open(picName[i]+'.jpg', 'wb') as f:
f.write(pic)
如果顺利你会得到十张图片















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









