







文章目录
urllib
在 Python 2 中,有 urllib 和 urllib2 两个库来实现请求的发送。而在 Python 3 中,已经不存在 urllib2 这个库了,统一为 urllib,其官方文档链接为: https://docs.python.org/3/library/urllib.html
python的标准库–内部集成了模块
- request:它是最基本的 HTTP 请求模块,可以用来模拟发送请求。就像在浏览器里输入网址然后 回车一样,只需要给库方法传入 URL 以及额外的参数,就可以模拟实现这个过程
- error:异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后进行重试或其他操作以 保证程序不会意外终止。
- parse:一个工具模块,提供了许多 URL 处理方法,比如拆分、解析、合并等。 robotparser:主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可 以爬,它其实用得比较少。
urlopen
官方文档 https://docs.python.org/3/library/urllib.request.html
爬取http请求
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get')
print(response.read().decode('utf-8'))
print(response.readline().decode('utf-8'))
print(response.info())
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))
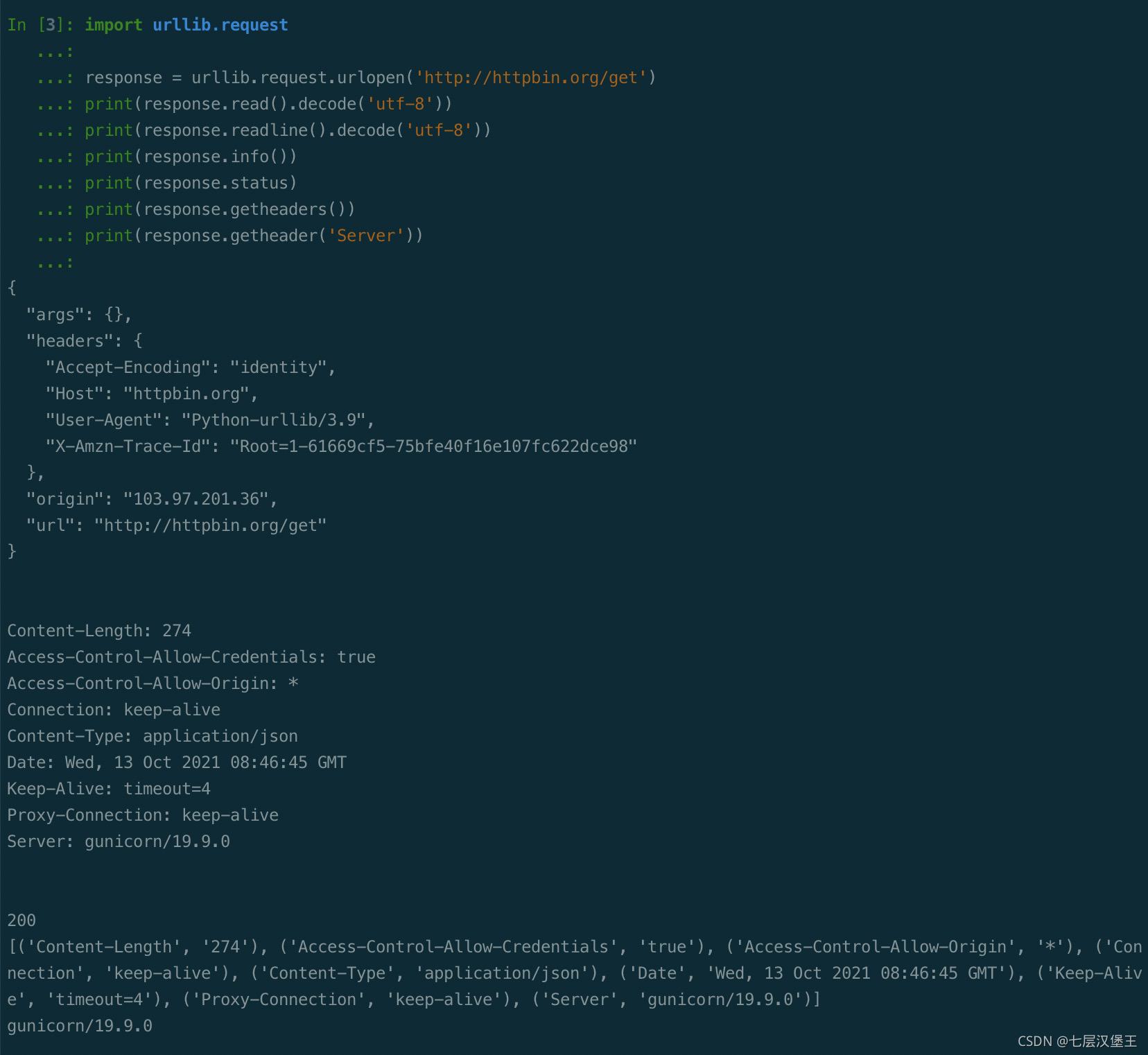
response 对象
- read() 获取响应返回的数据
- readline() 读取一行
- info() 获取响应头信息
- geturl() 获取访问的url
- getcode() 返回状态码
- getheaders() 返回头部信息 列表
data 参数
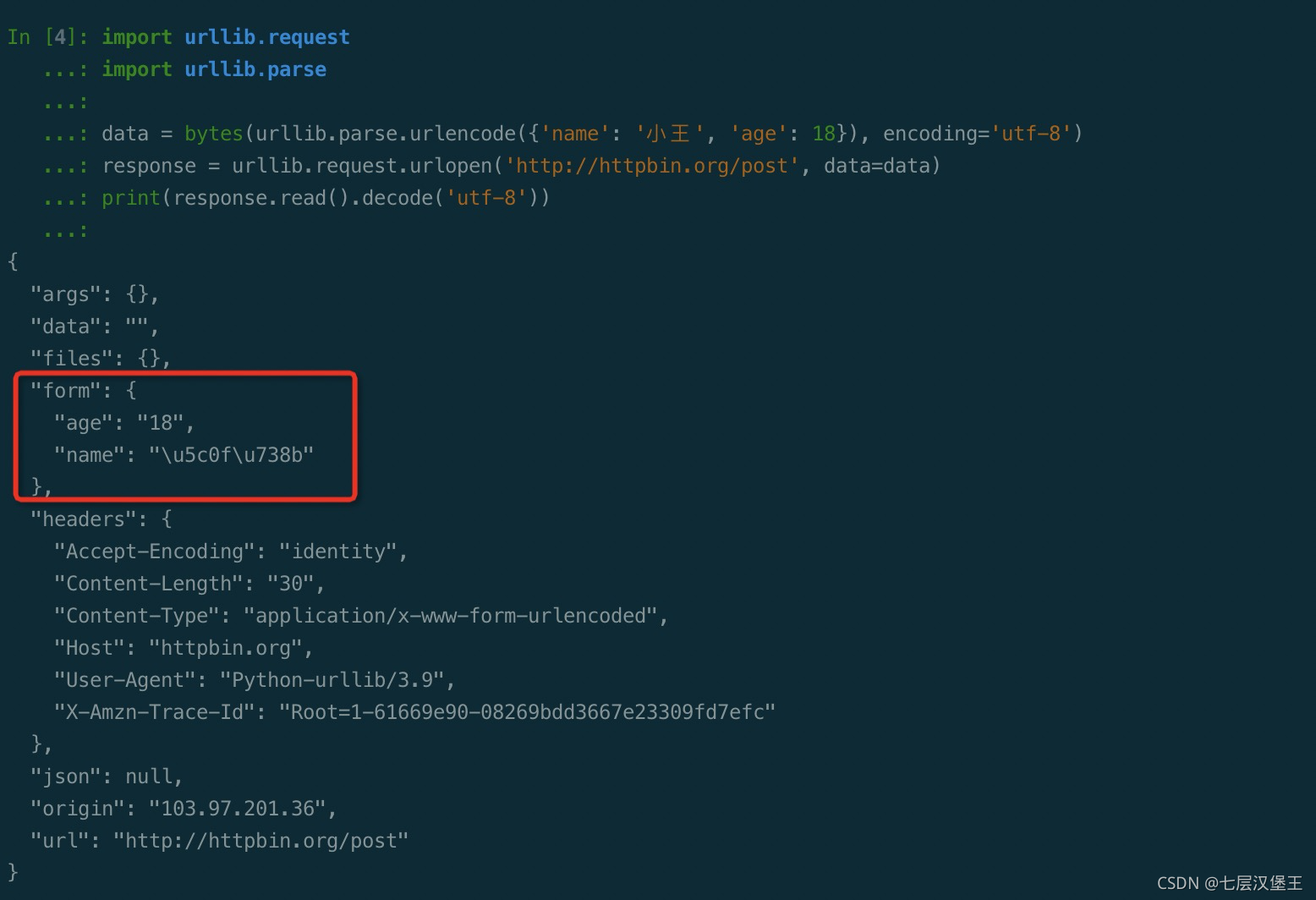
通过data参数向服务端提交参数需要urlencode编码后发送
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'name': '小王', 'age': 18}))
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read().decode('utf-8'))
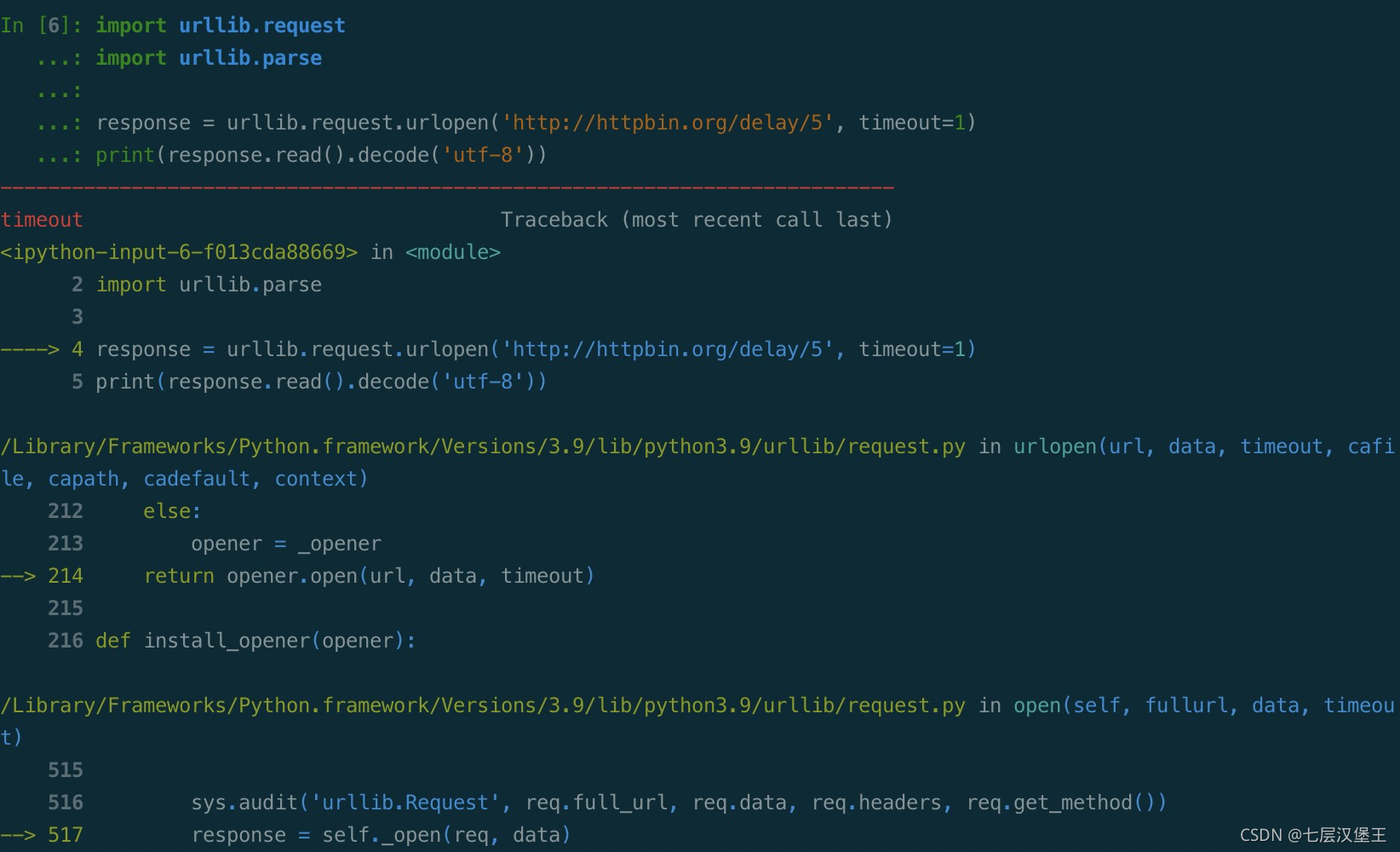
timeout参数
import urllib.request
import urllib.parse
# 指定延时5秒返回。但是timeout为1秒 所以会超时报错
# 修改timeout时间避免超时
response = urllib.request.urlopen('http://httpbin.org/delay/5', timeout=1)
print(response.read().decode('utf-8'))
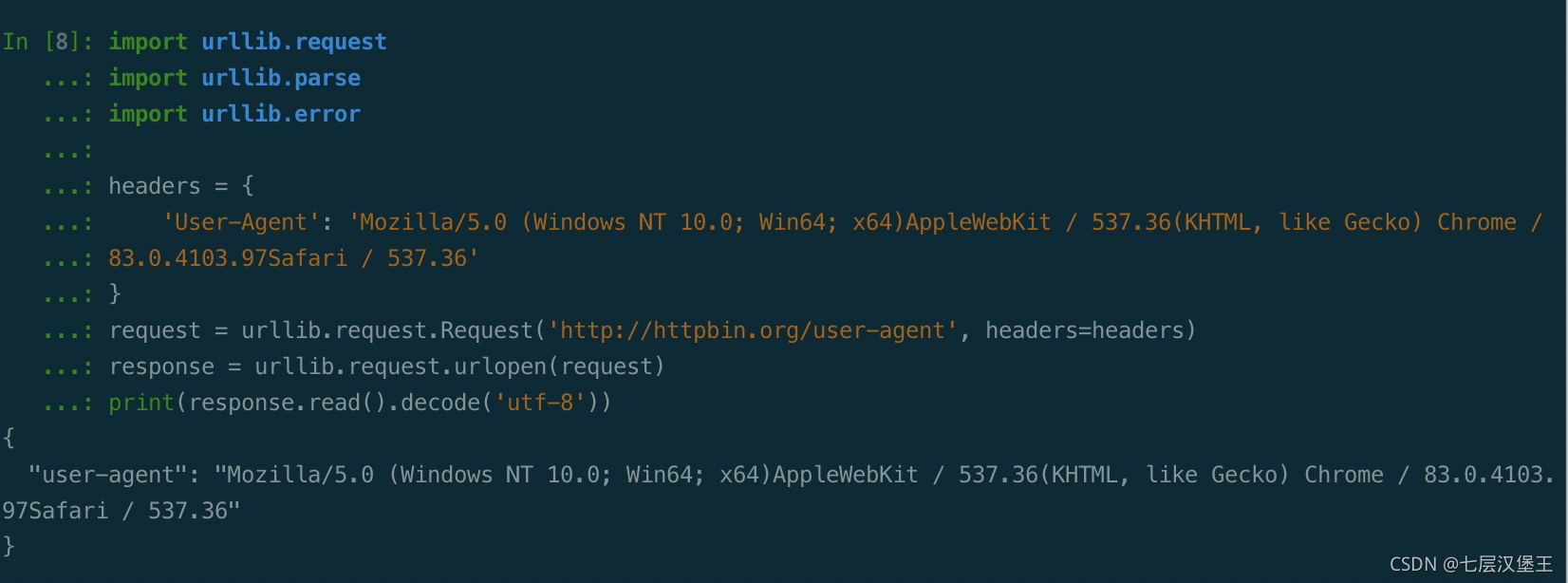
Request
urlopen 可以请求一些简单的请求,但爬虫很多时候都是要加入headers等参数,使用Request类来构造请求参数会比较方便。
import urllib.request
import urllib.parse
import urllib.error
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 83.0.4103.97Safari / 537.36'
}
request = urllib.request.Request('http://httpbin.org/user-agent', headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
error
import urllib.request
import urllib.parse
import urllib.error
from urllib import request, error
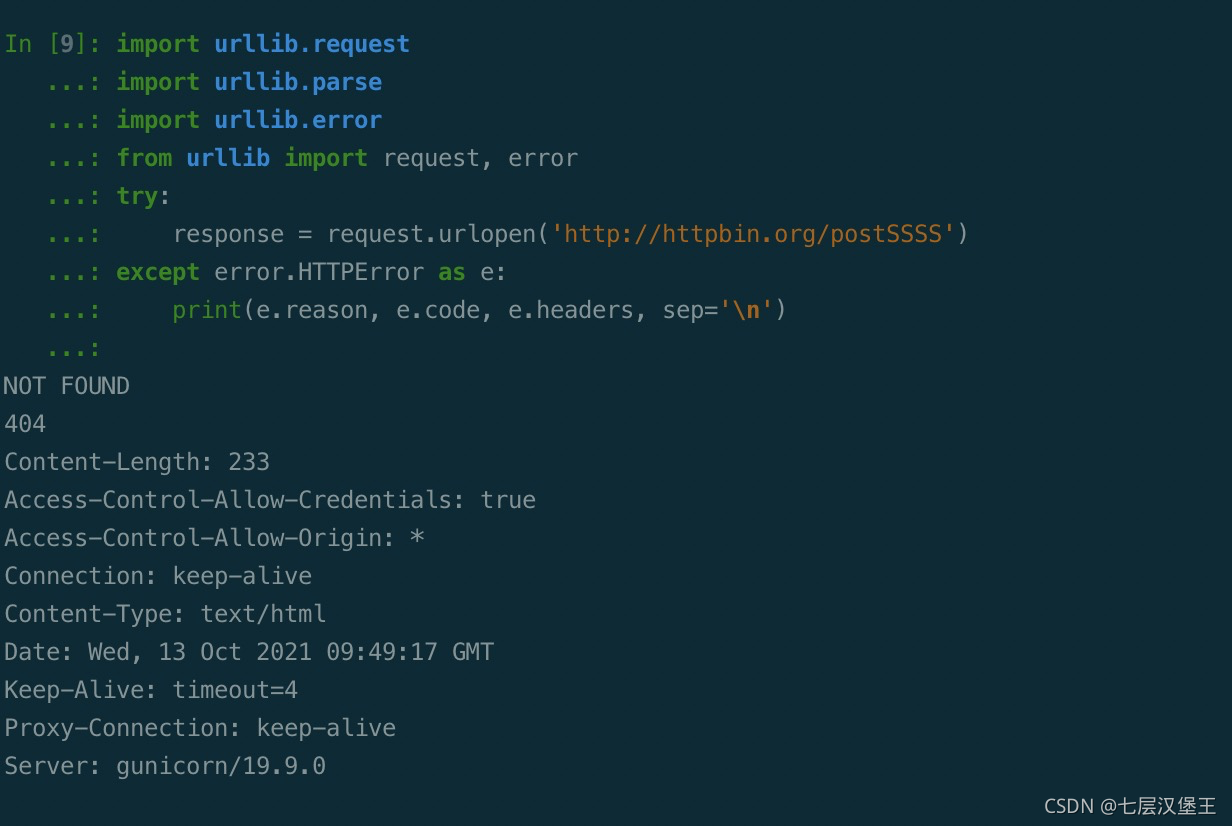
try:
response = request.urlopen('http://httpbin.org/postSSSS')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
urlparse
urllib 库里还提供了 parse 模块,它定义了处理 URL 的标准接口,例如实现 URL 各部分的抽取、合 并以及链接转换。它支持如下协议的 URL 处理:file、ftp、gopher、hdl、http、https、imap、 mailto、 mms、news、nntp、prospero、rsync、rtsp、rtspu、sftp、 sip、sips、snews、svn、svn+ssh、telnet 和 wais
from urllib.parse import urlparse
result = urlparse('http://httpbin.org/get?id=5#comment')
print(type(result), result)

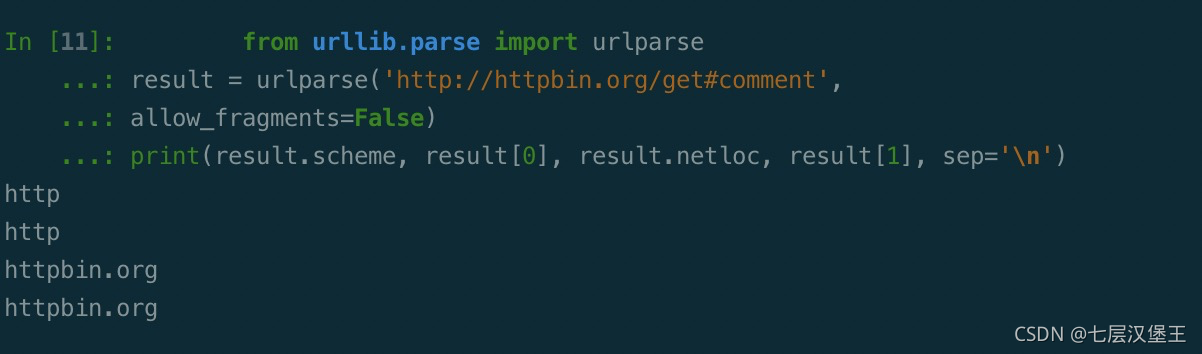
当 URL 中不包含 params 和 query 时,fragment 便会被解析为 path 的一部分。
from urllib.parse import urlparse
result = urlparse('http://httpbin.org/get#comment',
allow_fragments=False)
print(result.scheme, result[0], result.netloc, result[1], sep='\n')
urlencode
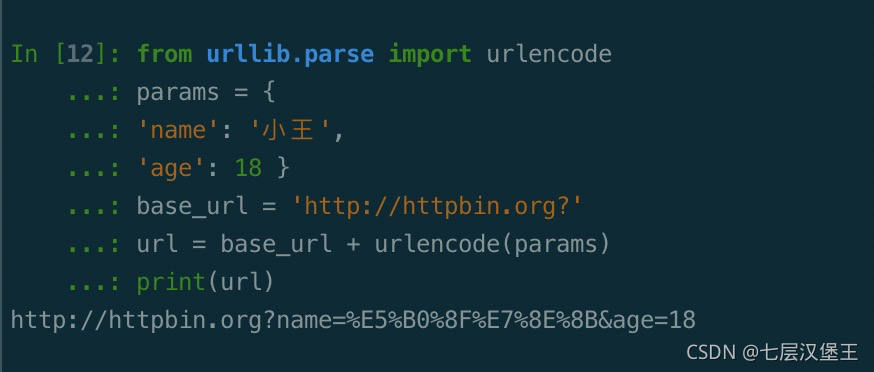
将参数编码。 例如有get请求中有中文时浏览器也会自动编码
from urllib.parse import urlencode
params = {
'name': '小王',
'age': 18 }
base_url = 'http://httpbin.org?'
url = base_url + urlencode(params)
print(url)
quote
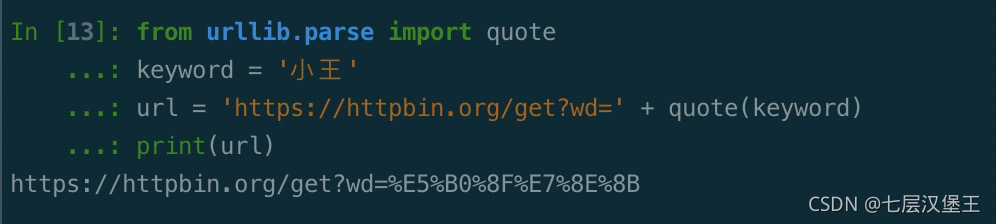
该方法可以将内容转化为 URL 编码的格式。URL 中带有中文参数时,有时可能会导致乱码的问题,此 时用这个方法可以将中文字符转化为 URL 编码,示例如下:
from urllib.parse import quote
keyword = '小王'
url = 'https://httpbin.org/get?wd=' + quote(keyword)
print(url)
unquote
将url编码的内容解码
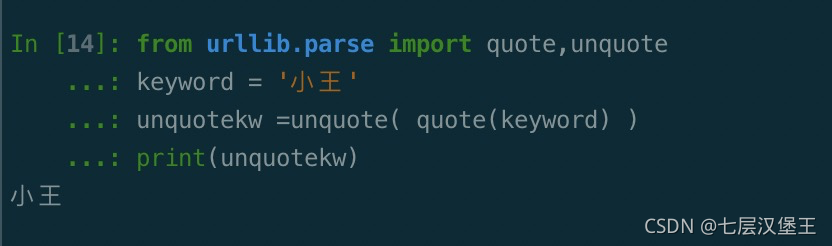
from urllib.parse import quote,unquote
keyword = '小王'
unquotekw =unquote( quote(keyword) )
print(unquotekw)
Robots 协议
Robots 协议也称作爬虫协议、机器人协议,它的全名叫作网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫作 robots.txt 的文本文件,一般放在网站的根目录下。
# https://www.jd.com/robots.txt
User-agent: * # User-agent: * 这里将其设置为 * 则代表该协议对任何爬取爬虫有效 Disallow: /?* # 禁止抓取网站中/目录后的网址
Disallow: /pop/*.html # 禁止抓取 /pop/后面的所有 html文件
Disallow: /pinpai/*.html?* # 静止抓取 /pinpai/ 里面html 携带 ? 参数的文件
User-agent: EtaoSpider # 一淘网蜘蛛
Disallow: /
User-agent: HuihuiSpider # 惠惠购物助手
Disallow: /
User-agent: GwdangSpider # 购物党爬虫
Disallow: /
User-agent: WochachaSpider # 我查查爬虫:
Disallow: /
参考各个厂的爬虫ua : https://www.cheshirex.com/2110.html
urllib3
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性:
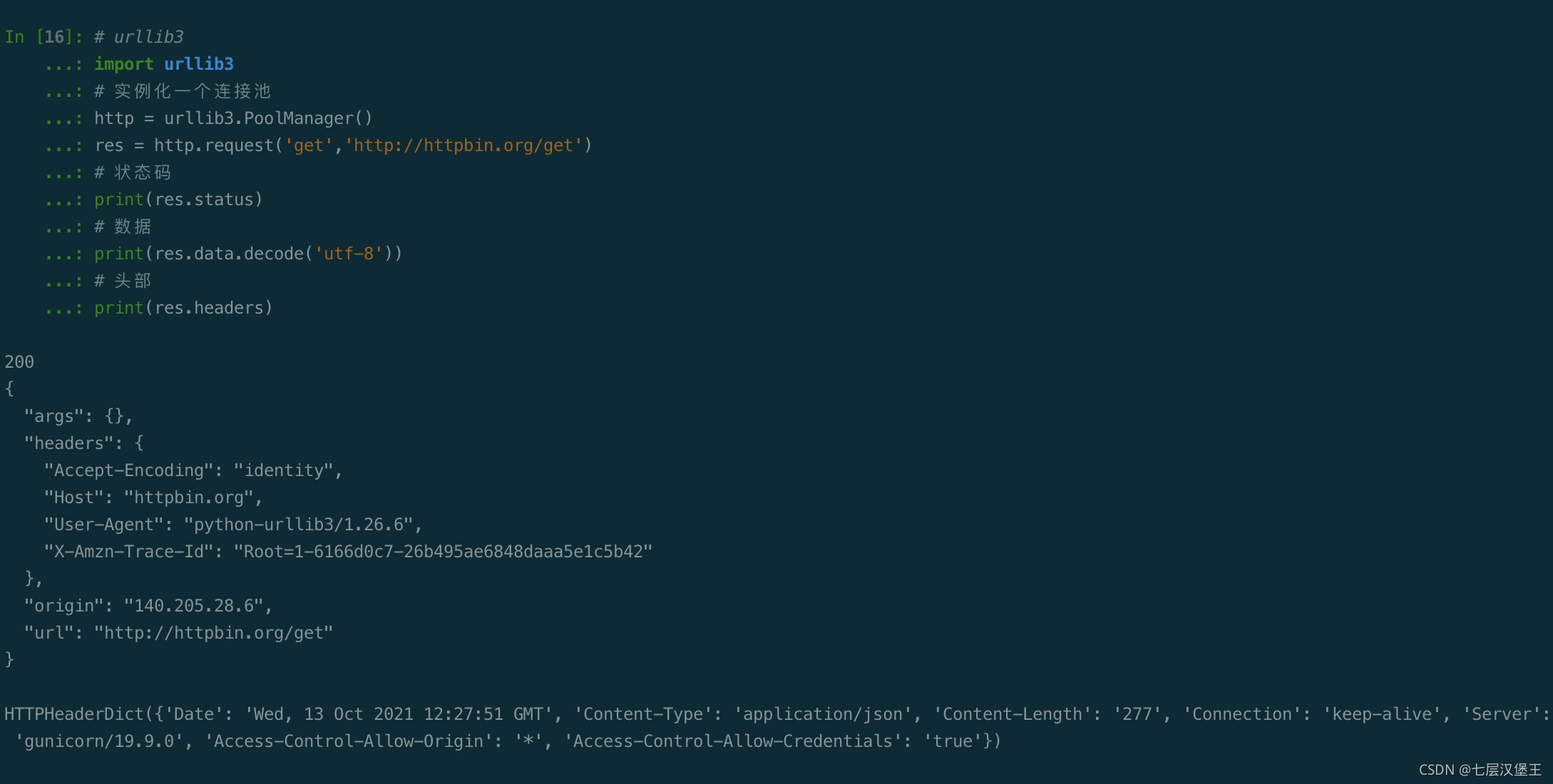
# urllib3
import urllib3
# 实例化一个连接池
http = urllib3.PoolManager()
res = http.request('get','http://httpbin.org/get')
# 状态码
print(res.status)
# 数据
print(res.data.decode('utf-8'))
# 头部
print(res.headers)
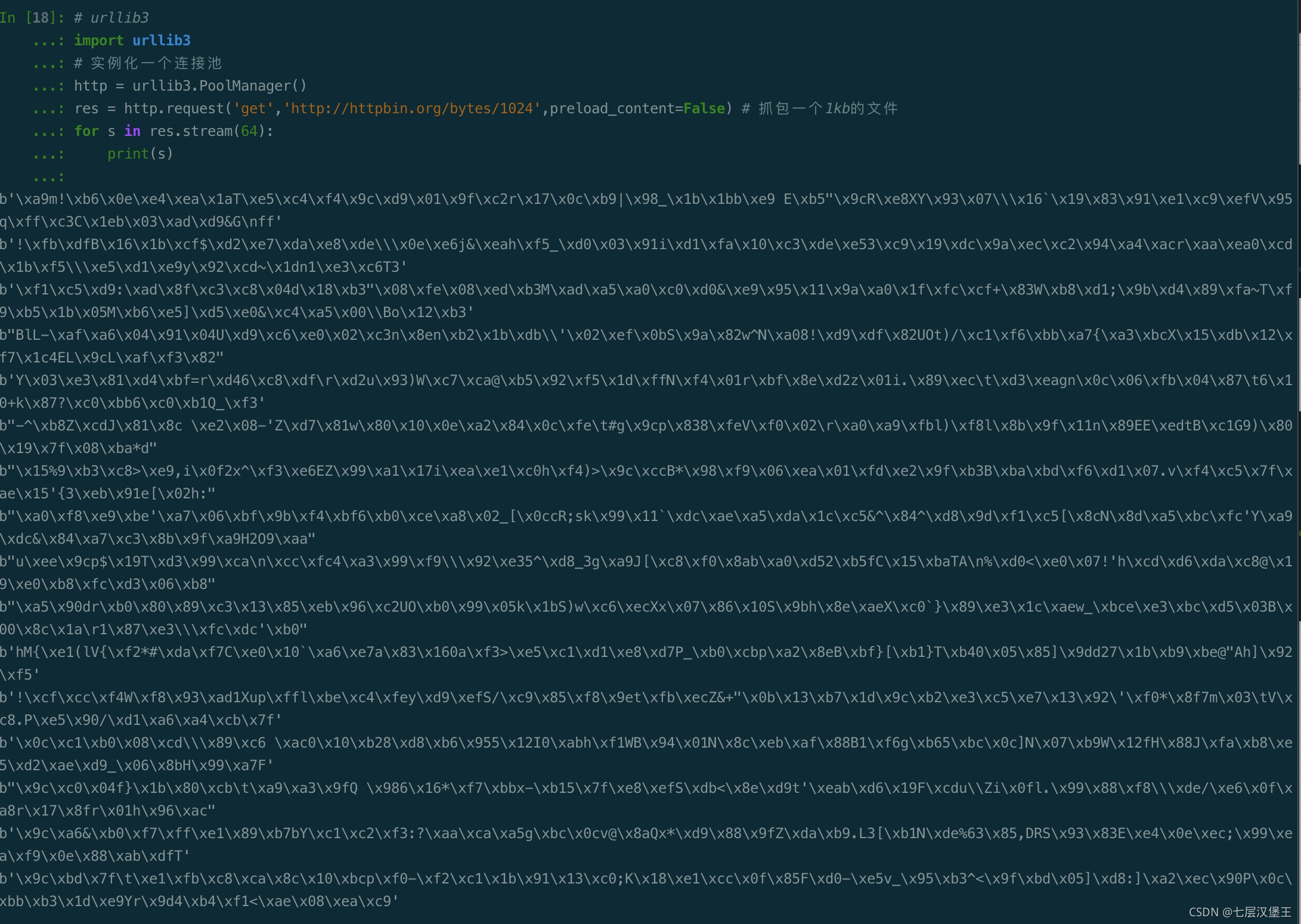
处理大文件
# urllib3
import urllib3
# 实例化一个连接池
http = urllib3.PoolManager()
res = http.request('get','http://httpbin.org/bytes/1024',preload_content=False) # 抓包一个1kb的文件
for s in res.stream(64):
print(s)
设置代理
import urllib3
http = urllib3.ProxyManager('https://103.103.3.6:8080')
res = http.request('get','http://httpbin.org/ip')
print(res.data)
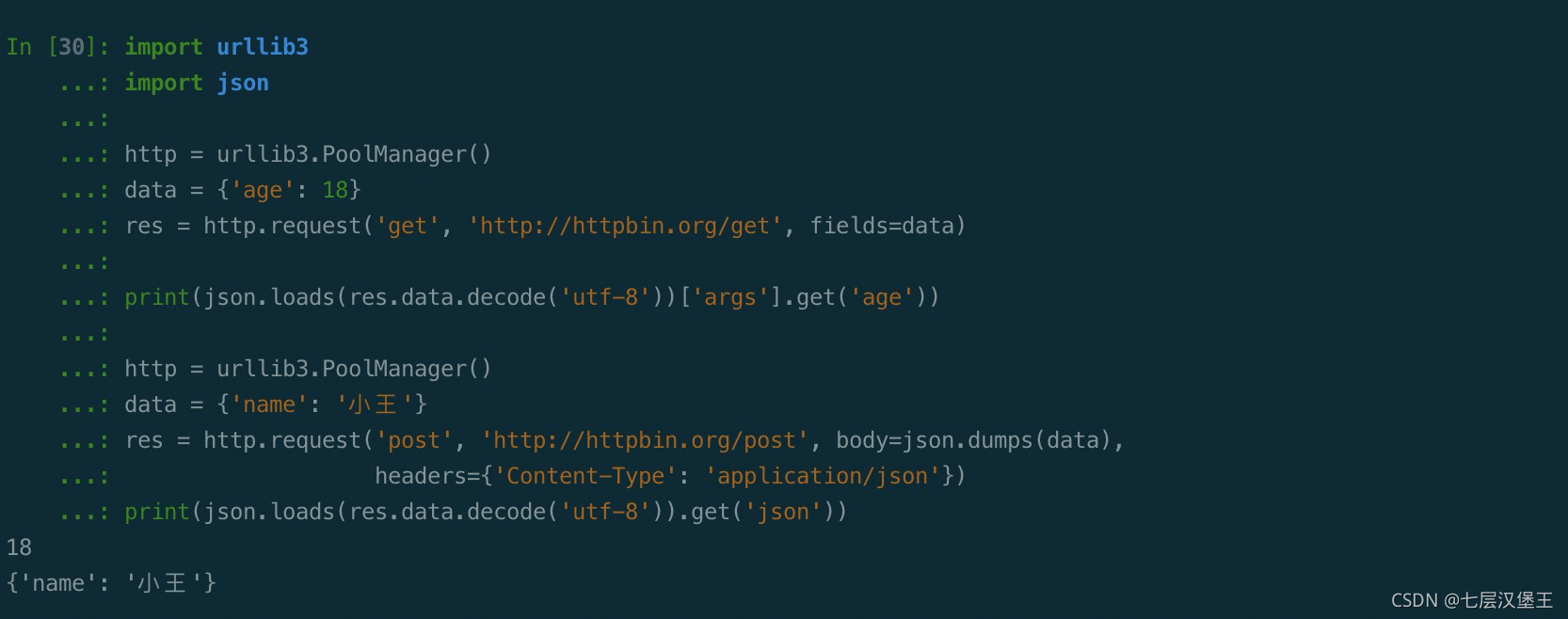
设置请求头
import urllib3
import json
http = urllib3.PoolManager()
data = {'age': 18}
res = http.request('get', 'http://httpbin.org/get', fields=data)
print(json.loads(res.data.decode('utf-8'))['args'].get('age'))
http = urllib3.PoolManager()
data = {'name': '小王'}
res = http.request('post', 'http://httpbin.org/post', body=json.dumps(data),
headers={'Content-Type': 'application/json'})
print(json.loads(res.data.decode('utf-8')).get('json'))
图片上传
import urllib3
import json
# 上传文件
http = urllib3.PoolManager()
with open('1.jpeg', 'rb') as f:
data = f.read()
res = http.request('post', 'http://httpbin.org/post', body=data, headers={'Content-Type': 'image/jpeg'})
print(json.loads(res.data.decode('utf-8')).get('data'))
实际案例(爬取小姐姐图片)
仅供学习,切莫乱用
import urllib3
import json
import re
import os
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
class S_wm(object):
def __init__(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
self.http = urllib3.PoolManager()
def get_url_list(self, urls):
res = self.http.request('get', urls, headers=self.headers)
html = res.data.decode('utf-8')
url_list = re.findall('<a href="(.*?)" alt=".*?" title=".*?">', html)
print(url_list)
return url_list
def save_image(self, filename, img):
with open(filename, 'wb') as f:
f.write(img.data)
print('图片提取成功')
def run(self, url):
url_list = self.get_url_list(url)
# 测试一下就好了 别乱爬哈。毕竟人家给我们提供小姐姐也不容易
for u in url_list[:1]:
file_name = './wm/{}'.format(u.split('/')[-1])
print('https:' + u)
data = self.http.request('get', 'https:' + u, headers=self.headers)
self.save_image(file_name, data)
if __name__ == '__main__':
url = 'http://www.vmgirls.com/17606.html'
s = S_wm()
if os.path.exists("./wm") is False:
os.mkdir('./wm')
s.run(url)
案例中遇到的问题
1、无法打开控制台查看网页代码
先打开一个网页并把dock调整为浮窗
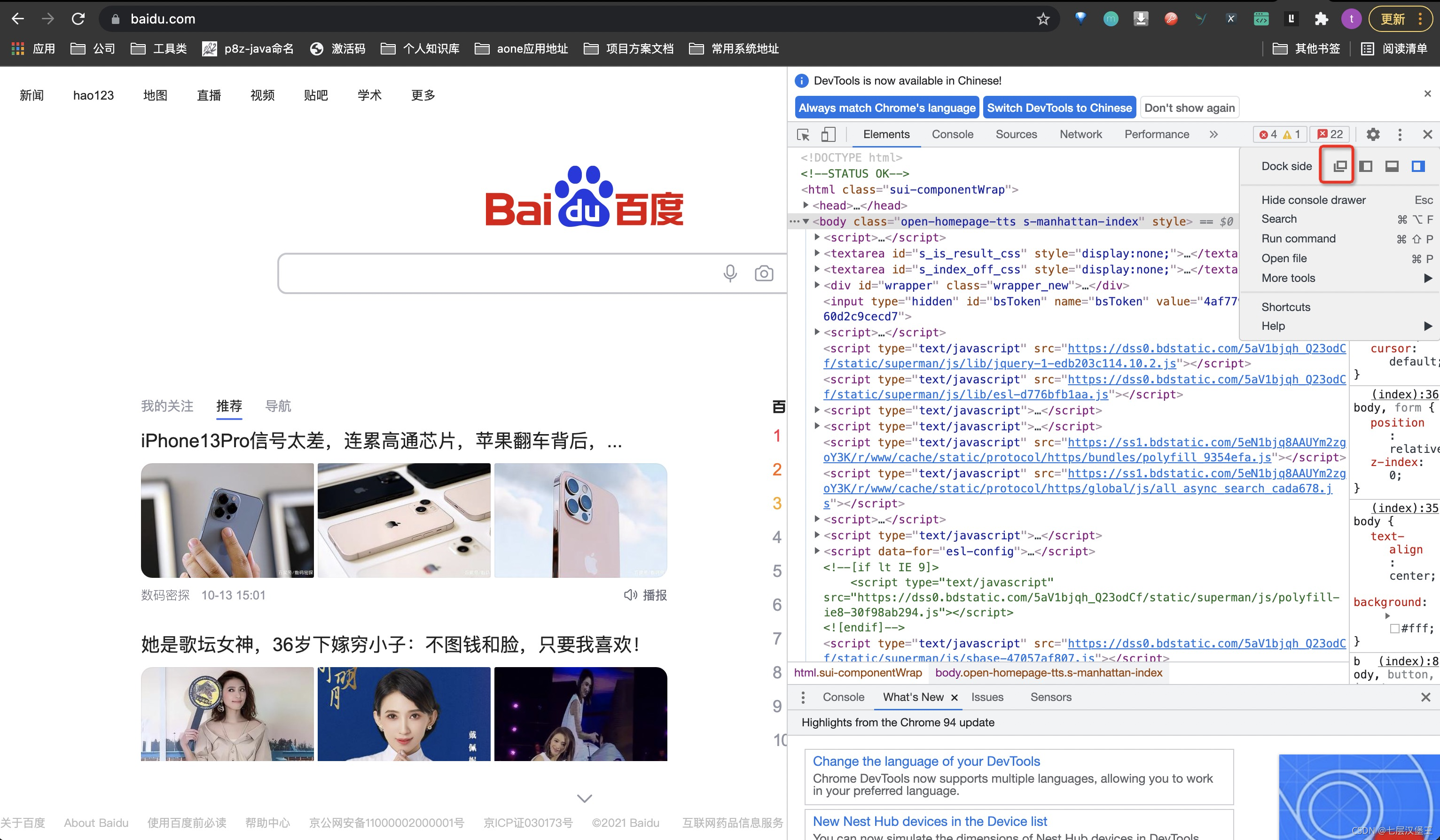
然后在该网站输入想要查看的网址
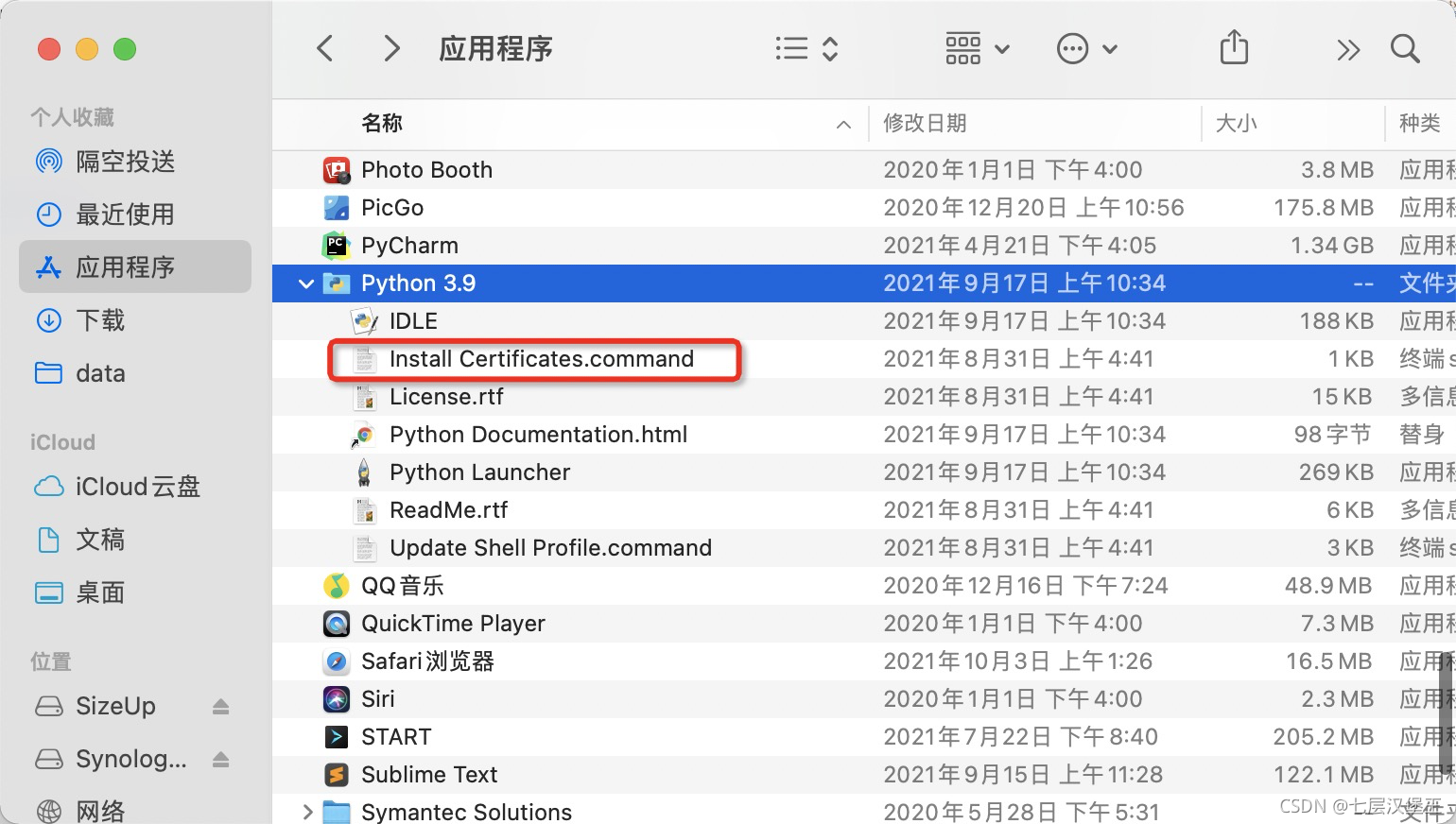
macOS python urllib3 HTTPS请求证书校验报错
点击执行这个可执行文件下载证书既可
参考: https://stackoverflow.com/questions/52805115/certificate-verify-failed-unable-to-get-local-issuer-certificate















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











