







目录
二:MapReduce - WordCount程序练习所需环境
一、目的及要求:
1、熟悉常用的HDFS操作
实验目的:
- 熟练使用HDFS操作常用的Shell命令
- 理解HDFS在Hadoop体系结构中的角色
2、MapReduce - WordCount程序练习
实验目的:
- 了解Hadoop集群MapReduce程序的简单使用
- 上传WordCount的jar执行程序
- 使用WordCount进行MapReduce计算
二、环境要求:
一:熟悉常用的HDFS操作所需环境
- Hadoop版本:1.2.1或以上版本
- JDK版本:1.6或以上版本
二:MapReduce - WordCount程序练习所需环境
- 主机内存2G以上,磁盘剩余空间300M以上
- 一台独立PC机或虚拟机
- 已安装CentOS 7.2操作系统
- 已安装JDK
- 已完成Hadoop平台的搭建
集群规划:
★Hadoop的高可用完全分布模式中有HDFS的主节点和数据节点、MapReduce的主节点和任务节点、数据同步通信节点、主节点切换控制节点总共6类服务节点,其中HDFS的主节点、MapReduce的主节点、主节点切换控制节点共用相同主机Cluster-01和Cluster-02,HDFS的数据节点、MapReduce的任务节点共用相同主机Cluster-03、Cluster-04、Cluster-05, 数据同步通信节点可以使用集群中的任意主机,但因为其存放的是元数据备份,所以一般不与主节点使用相同主机。
★高可用完全分布模式中需要满足主节点有备用的基本要求,所以需要两台或以上的主机作为主节点,而完全分布模式中需要满足数据有备份和数据处理能够分布并行的基本要求,所以需要两台或以上的主机作为HDFS的数据节点和MapReduce的任务节点, 同时数据同步通信节点工作原理同Zookeeper类似, 需要三台或以上的奇数台主机,
具体规划如下:

三、操作步骤:
一:熟悉常用的HDFS操作
1:向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有文件;(追加文件内容以编程方式进行)。
例如:新建文本文档file1.txt;第二次重复上传本文件

2:从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名:。
例如:从HDFS中下载file1.txt到本地目录;和本地重名就自动重命名
3:将HDFS中指定文件的内容输出到终端:。
例如:查看打印HDFS中指定文件file1.txt的内容

4:显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息。
例如:查看HDFS中file1.txt的读写权限、文件大小、创建时间、路径等。

5:给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。
例如:新建目录dir1,/dir1/dir2,新建并上传文件file2.txt到dir1,file2.txt内容为Hello world!,新建并上传文件file3.txt到dir2,file3.txt的内容为Hello Hadoop!,然后查看dir1目录下的所有文件读写权限、大小等;递归输出dir2目录下所有文件相关信息。



6:提供一个HDFS内的文件路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录。
例如:HDFS内的文件file4.txt,指定路径为/dir1/dir3
![]()
7:提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除此目录。
例如:HDFS内的目录dir4,指定路径为/dir/,在HDFS中/dir1/dir4目录下新建文件file5.txt

8:向HDFS中指定的文件追加内容HelloHadoop!
例如:向file5.txt文件内追加内容HelloHadoop!

二:MapReduce - WordCount程序练习
现在以admin普通用户登录Master.Hadoop服务器。即在主节点操作
创建文件夹file
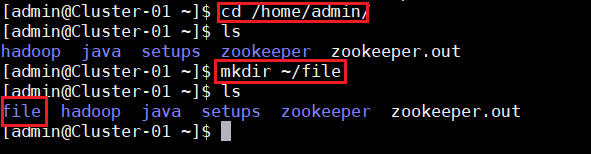
1:创建本地示例文件。
然后创建两个文本文件file1.txt和file2.txt
使file1.txt内容为“Hello World”,而file2.txt的内容为“Hello Hadoop”。

2:在HDFS上创建输入文件。
![]()
3:上传本地file中文件到集群的input目录下。

4:上传jar包。
先使用Xftp工具把WordCount的jar执行程序包上传到~/hadoop/hadoop/2.7.3/share/hadoop/mapreduce目录下

5:在集群上运行WordCount程序(备注:以input作为输入目录,output作为输出目录)。


6:查看结果。
查看HDFS上output目录内容

查看结果输出文件内容

Hadoop的Web验证



四、所遇问题:
出现问题、未找到hadoop命令
解决方案1:提示我 hadoopp的命令未找到,经过排查,发现是因为HADOOP_HOME的路径没有配置。首先打开/etc/profile
sudo gedit /etc/profile
然后再输入下面代码 设置HADOOP_HOME
export HADOOP_HOME=XXX
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export PATH=HADOOP_HOME/bin:$PATH
其中XXX代表你的hadoop放的路径。
然后再格式化namenode 。
解决方案2:经过与之前的实验对比,发现使用Hadoop命令,是要在zookeeper服务启动的前提下用命令Start-all.sh启动Hadoop集群。
五、小结
- 在一个典型的HA集群中,每个NameNode是一台独立的服务器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了,如下图所示。

- HDFS和MapReduce是Hadoop的两个重要核心,其中MR是Hadoop的分布式计算模型。MapReduce主要分为两步Map步和Reduce步。
- MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
- 在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
- 需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
- 在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。map函数接收一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,Hadoop函数接收一个如<key,(list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式的。
- Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_201202292213_0002,而且得知输入文件有两个(Total input paths to process : 2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。比如说,在本例中,map的task数量是2个,reduce的task数量是一个。map的输入record数是2个,输出record数是4个等信息。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









