







目录
写在前面
说来也搞笑,一个程序员我个人理解应该不会专门去为了学正则表达式而去学它,就算工作中需要用到正则不会写网上百度或者谷歌一下也能解决问题,那为什么我会去学正则呢?其实主要原因是因为自己okr中有个学习分享,然后就机缘巧合之下看到这个正则的知识,想着简单学习一下然后分享来完成自己的okr。但是在学习正则的过程中,发现正则真的很奇妙也很强大,打破了以往我对它的认知。比如:一个文本串aaa,使用正则:a*匹配到了两个结果,一个是aaa,一个是空字符串。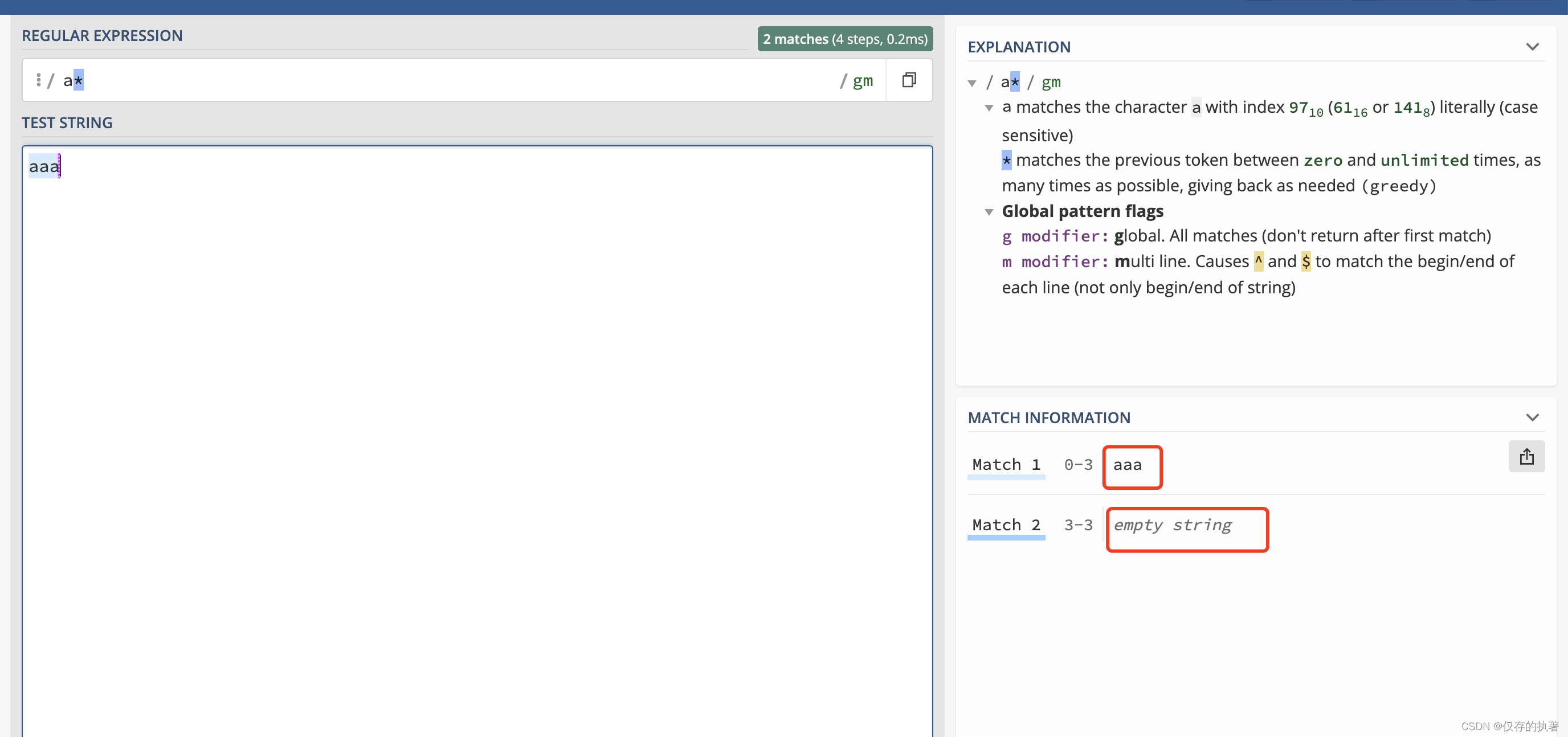
为什么3个a是作为整体被匹配到的而不是1个a一个个匹配?这其实就是正则的贪婪模式。
再比如:字符:
http://www.fapiao.com/dzfp-web/pdf/download?request=6e7JGm38jfjghVrv4ILd-kEn64HcUX4qL4a4qJ4-CHLmqVnenXC692m74H5oxkjgdsYazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf用正则:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$//|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$去匹配会发现cpu资源被大量占用的情况,这其实是因为正则的大量回溯所导致的。
以上只是正则部分有趣的地方,接下来一起学习吧!
在线学习验证正则表达式网站:regex101: build, test, and debug regex
一、什么是正则
正则,就是正则表达式,英文是 Regular Expression,简称 RE。顾名思义,正则其实就是一种描述文本内容组成规律的表示方式。
二、正则有什么用
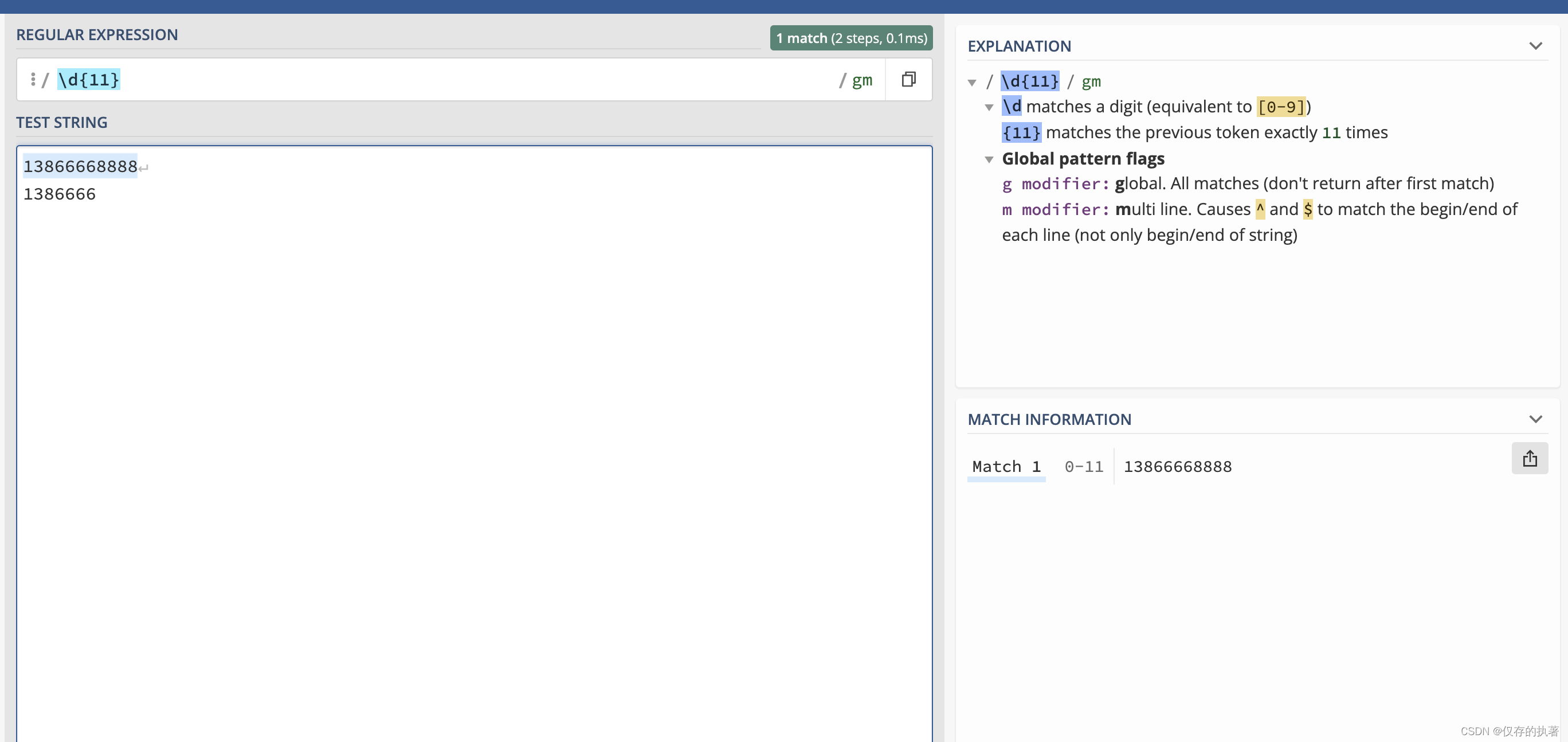
1.可以校验数据的有效性,比如用户输入的手机号是不是符合11位规则;
2.可以从文本中提取想要的内容,比如提取一段文本中的字母、数字、下划线数据;
3.可以用来做文本内容替换,比如替换重复内容。


三、元字符
元字符是正则的基础之一。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,元字符是构成正则表达式的基本元件。
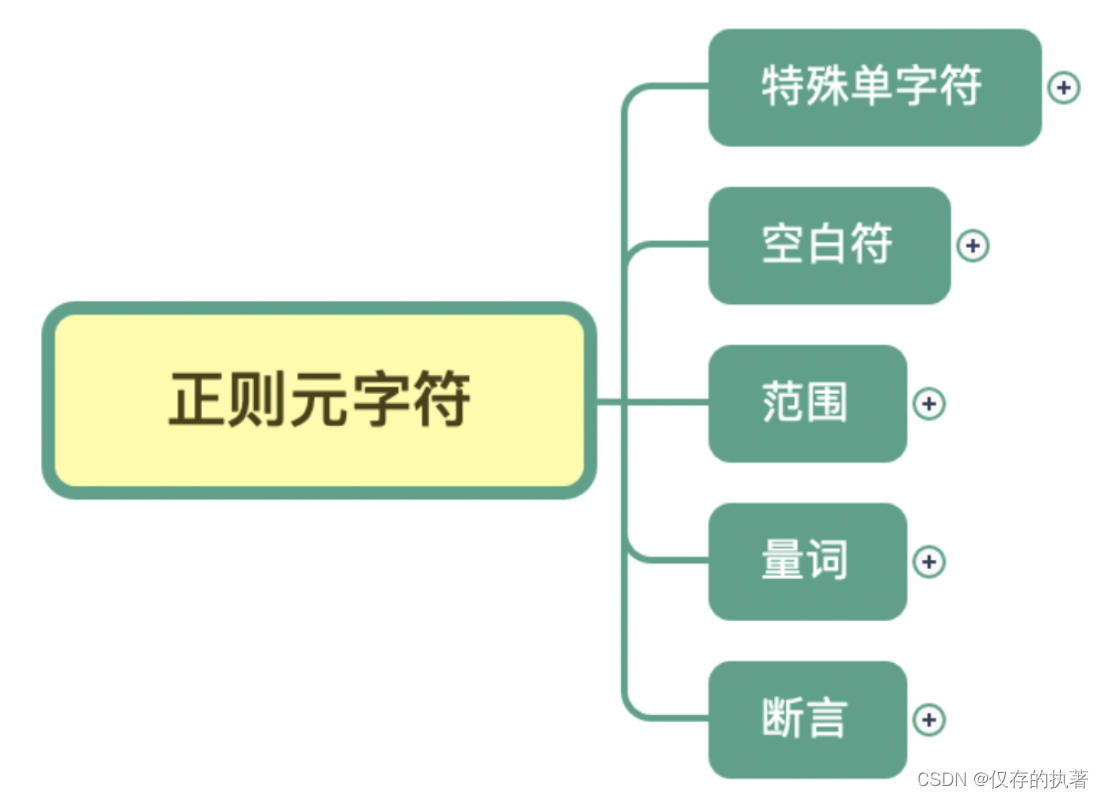
元字符主要分为5类
- - 特殊单字符
- - 空白符
- - 范围
- - 量词
- - 断言
-
1.特殊单字符
- 以下表示特殊单个字符的元字符

-
1.1 点.匹配任意字符(换行除外)

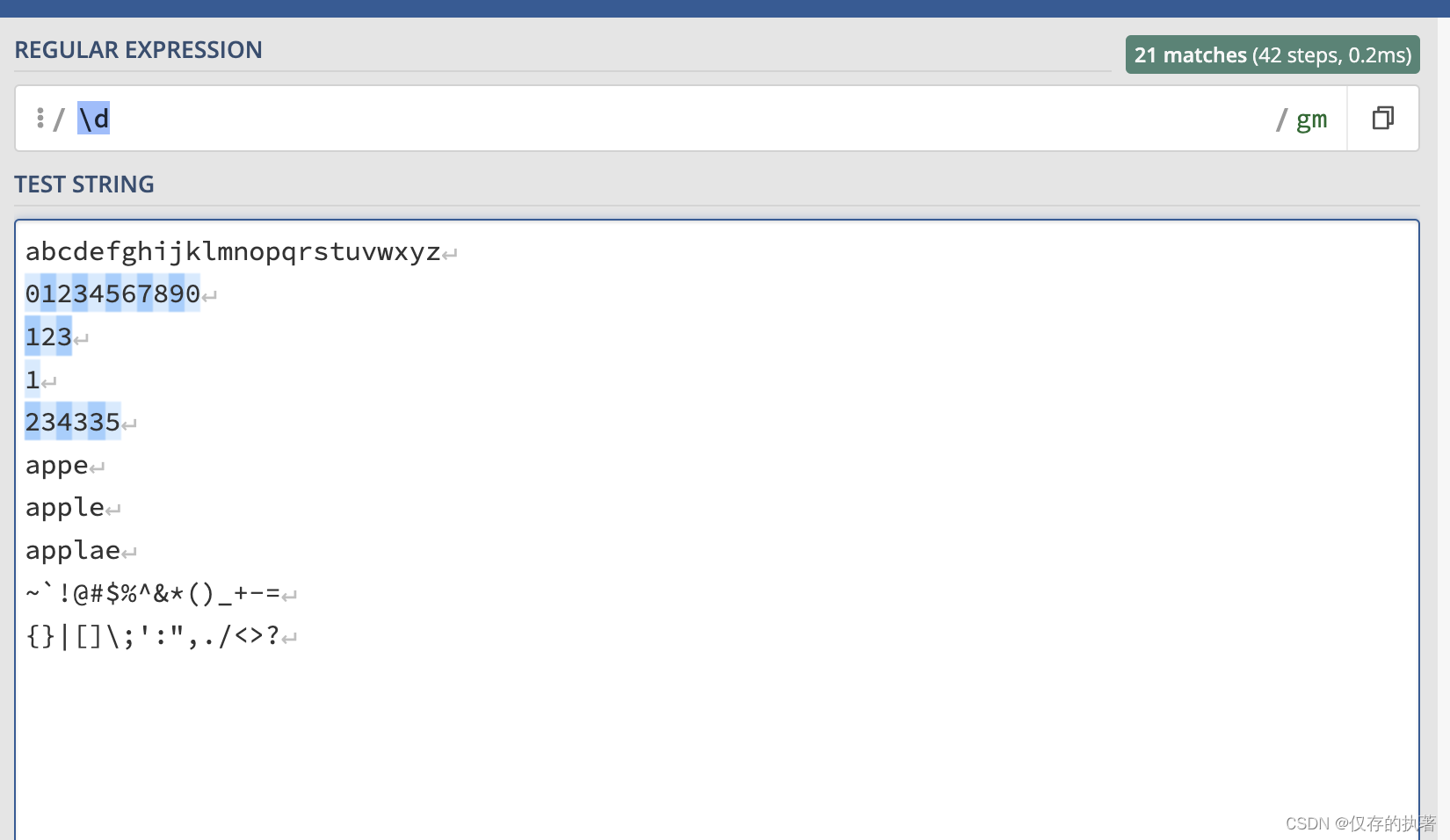
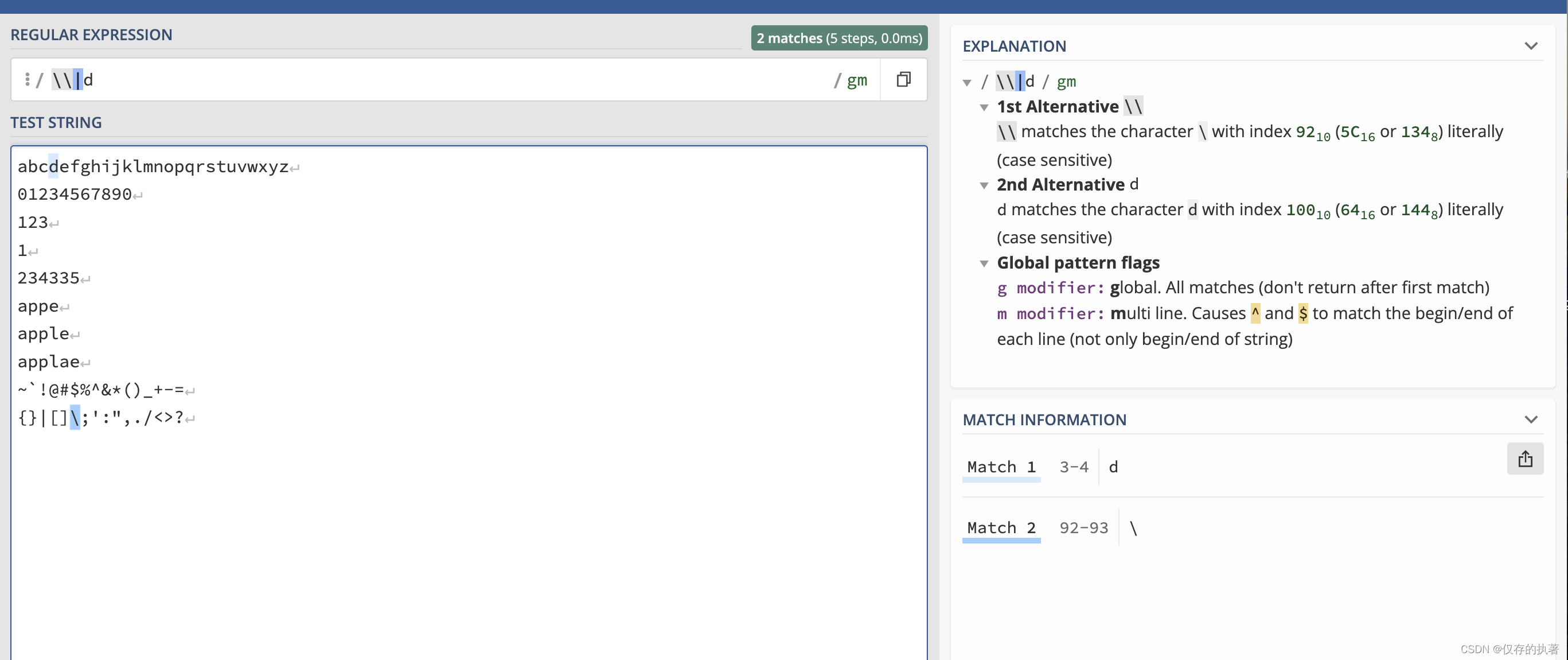
1.2 \d匹配任意数字,注意:\\|d匹配反斜杠或d字母
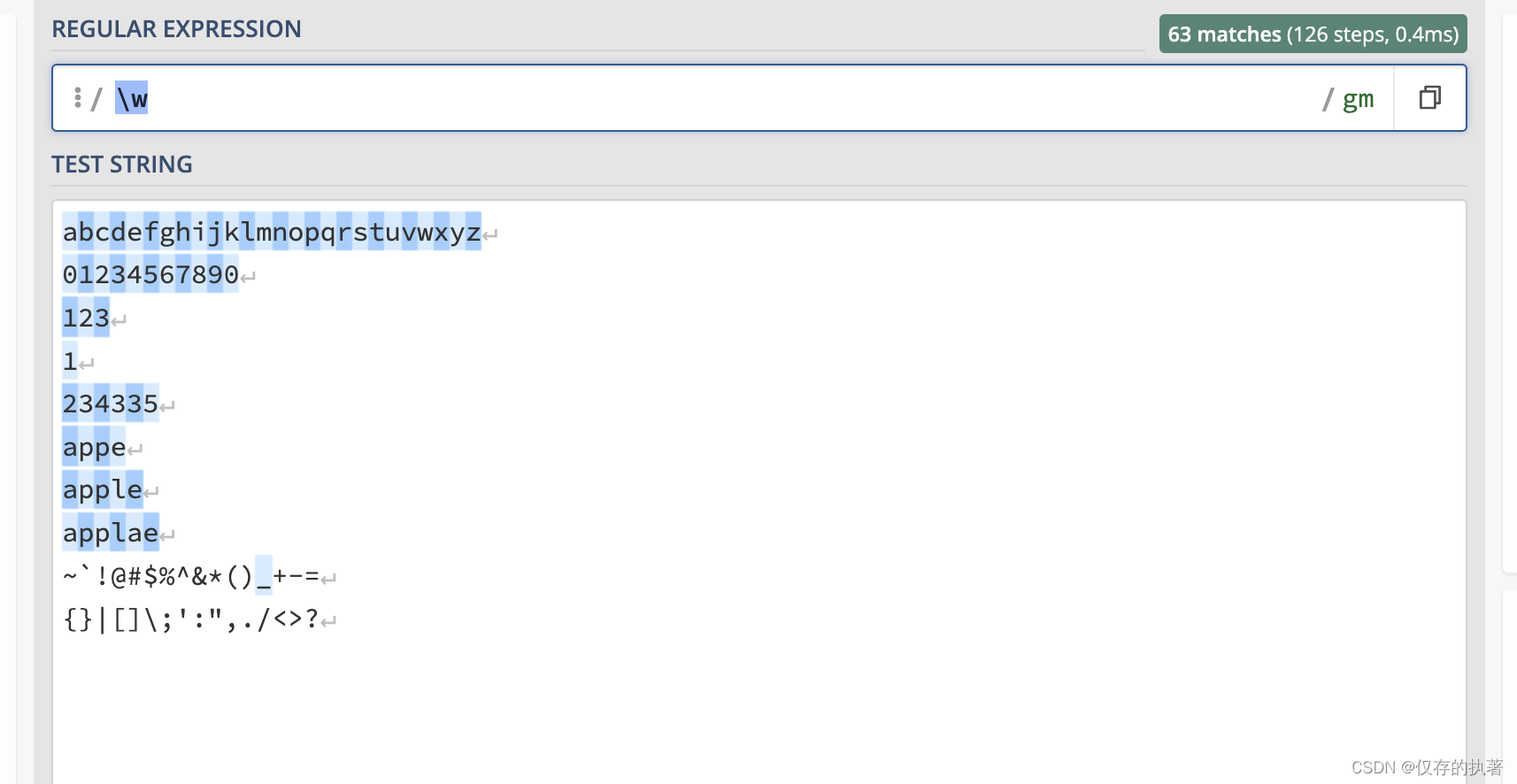
1.3 \w匹配任意字母数字下划线。注意:不匹配空格、换行符等
1.4 \s匹配任意空白符
2.空白符
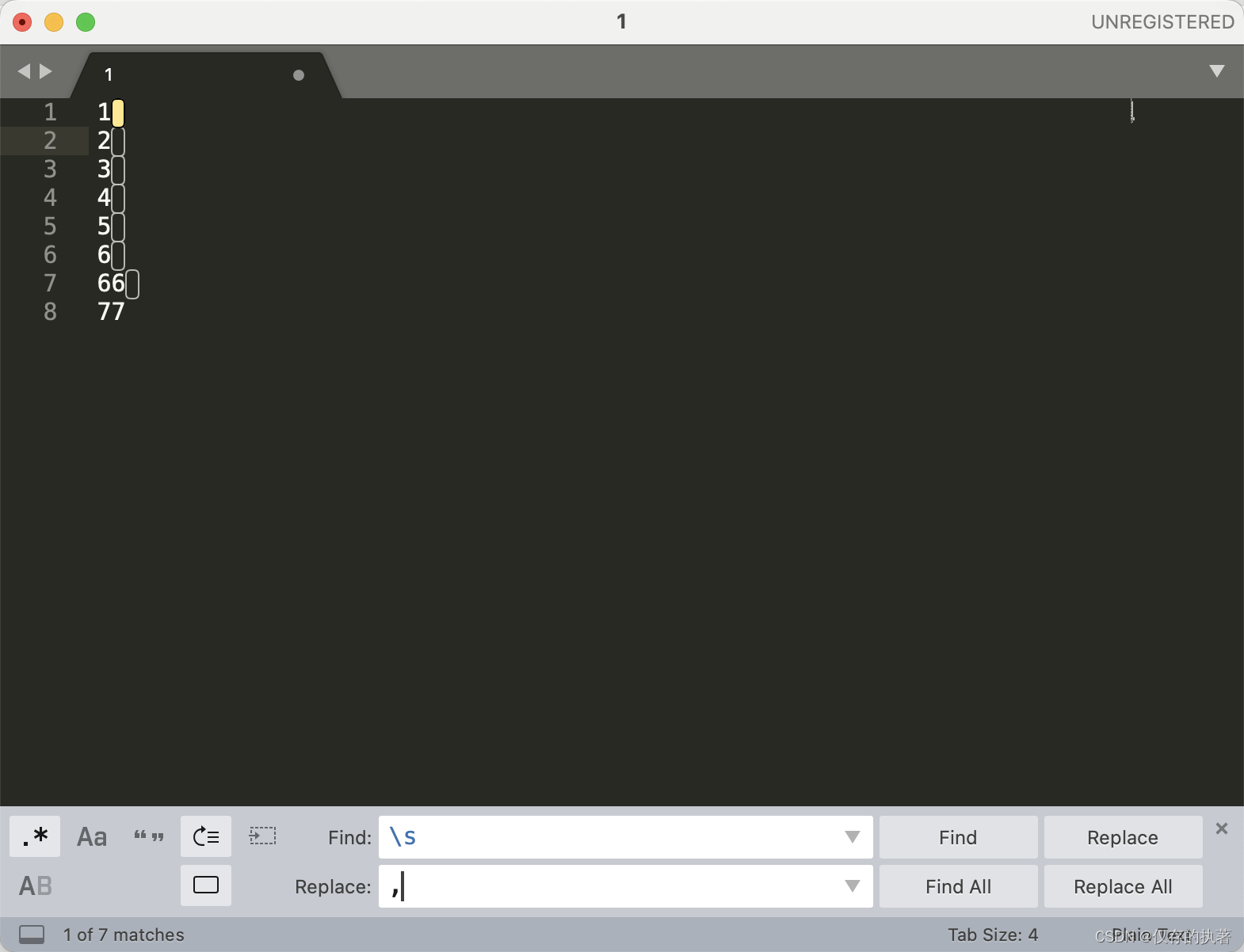
有时候我们在查sql,比如给了我们一批id让我们查询对应的记录,我们需要在每个id后面加个逗号类似如下:
一批id:
1
2
3
4
5
6
66
77
...我们需要按照这样查询:
select * from table where id in(1,2,3,4,5,6,66,77);这时候我们就可以使用空白符将换行符替换为逗号。
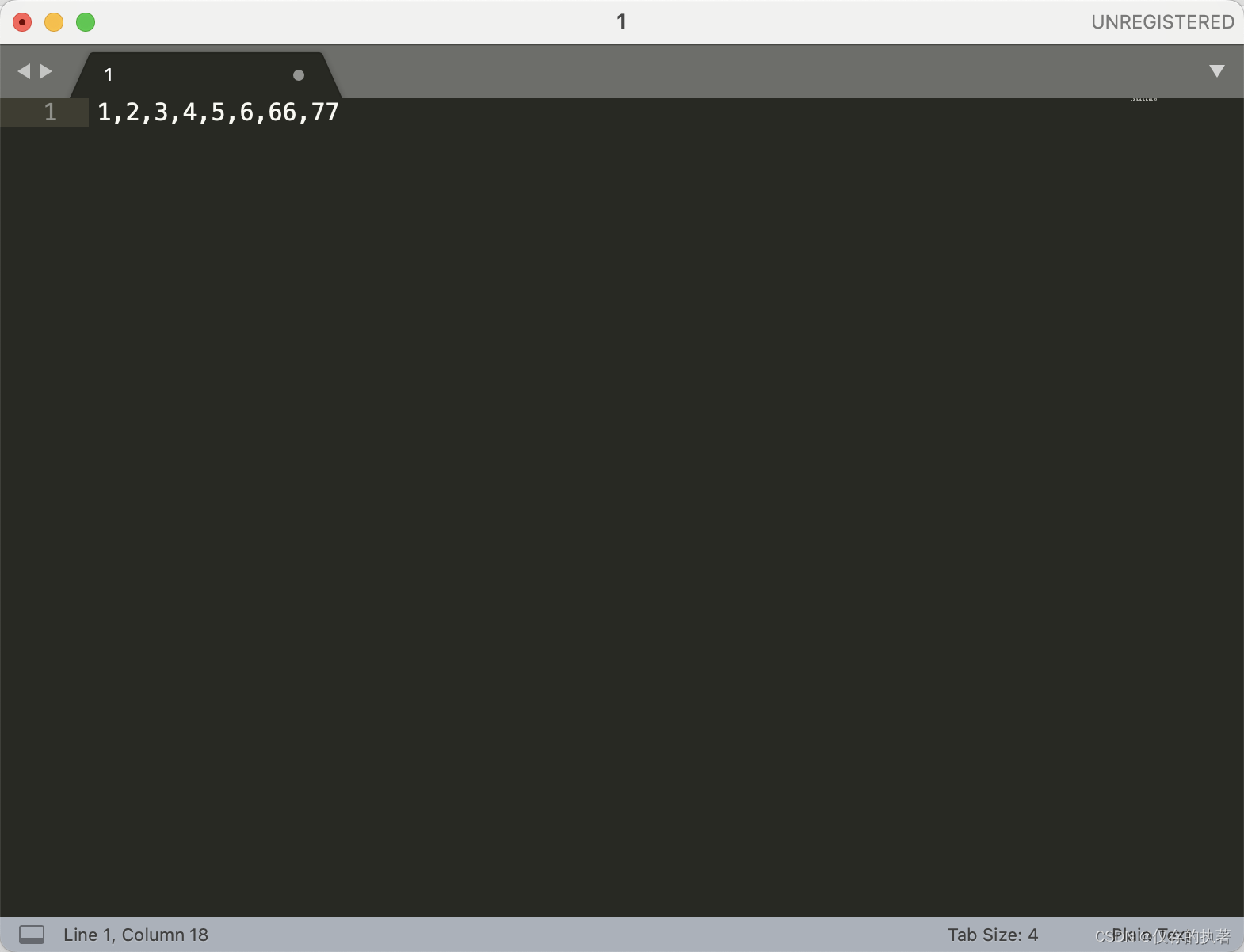
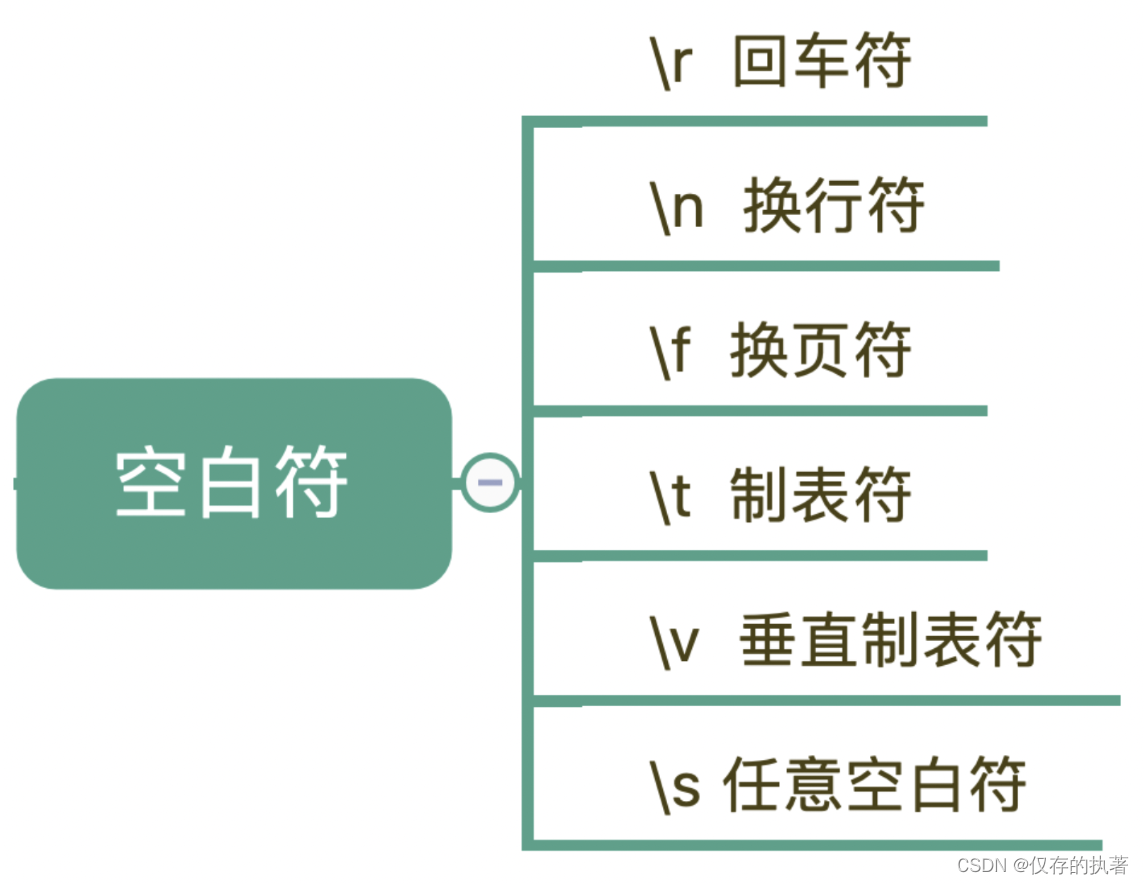
不同的系统在每行文本结束位置默认的“换行”会有区别。比如在 Windows 里是 \r\n,在 Linux 和 MacOS 中是 \n。在正则中,也是类似于 \n 或 \r 等方式来表示空白符号,平时使用正则,大部分场景使用 \s 就可以满足需求,\s 代表任意单个空白符号。
3.范围
有时候我们需要在一个特定的范围内找到符合要求的文本,这个时候就需要使用正则的范围。

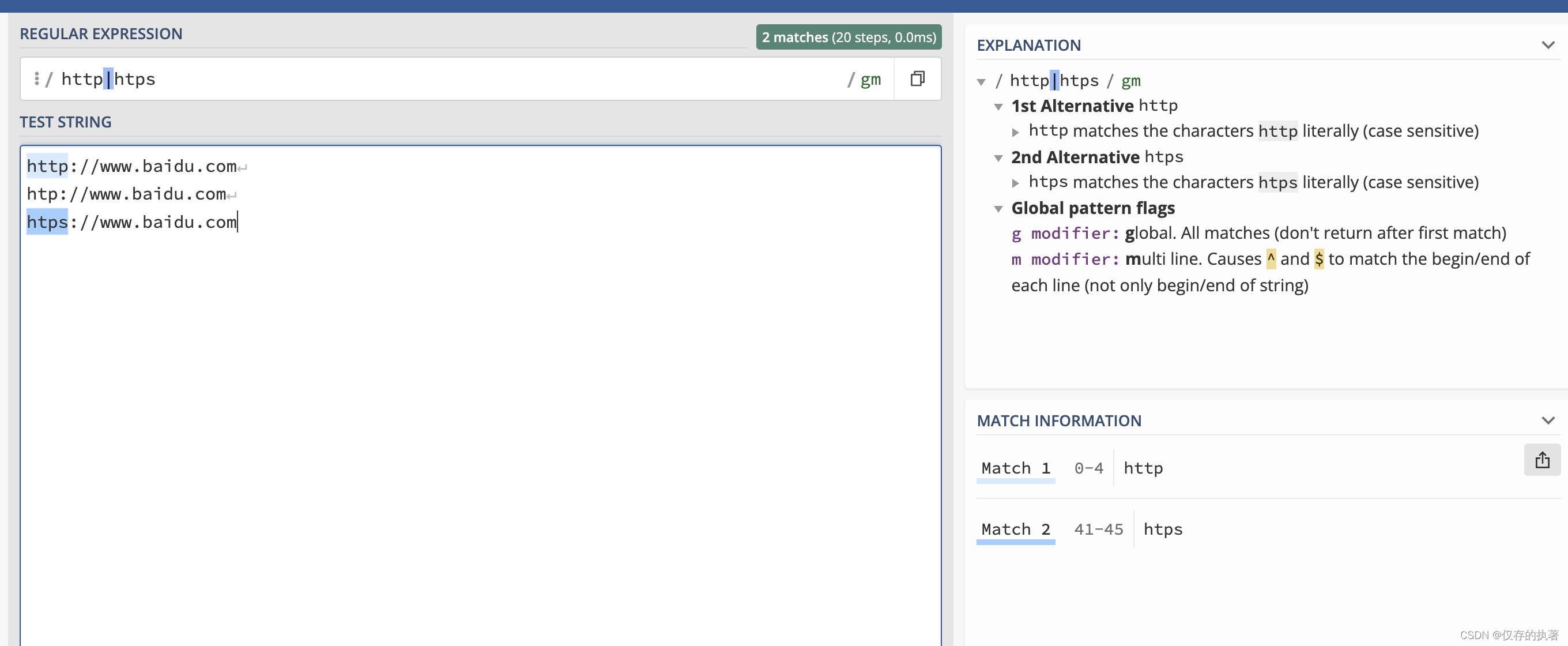
比如:需要匹配http或htps,使用管道"|":http|htps
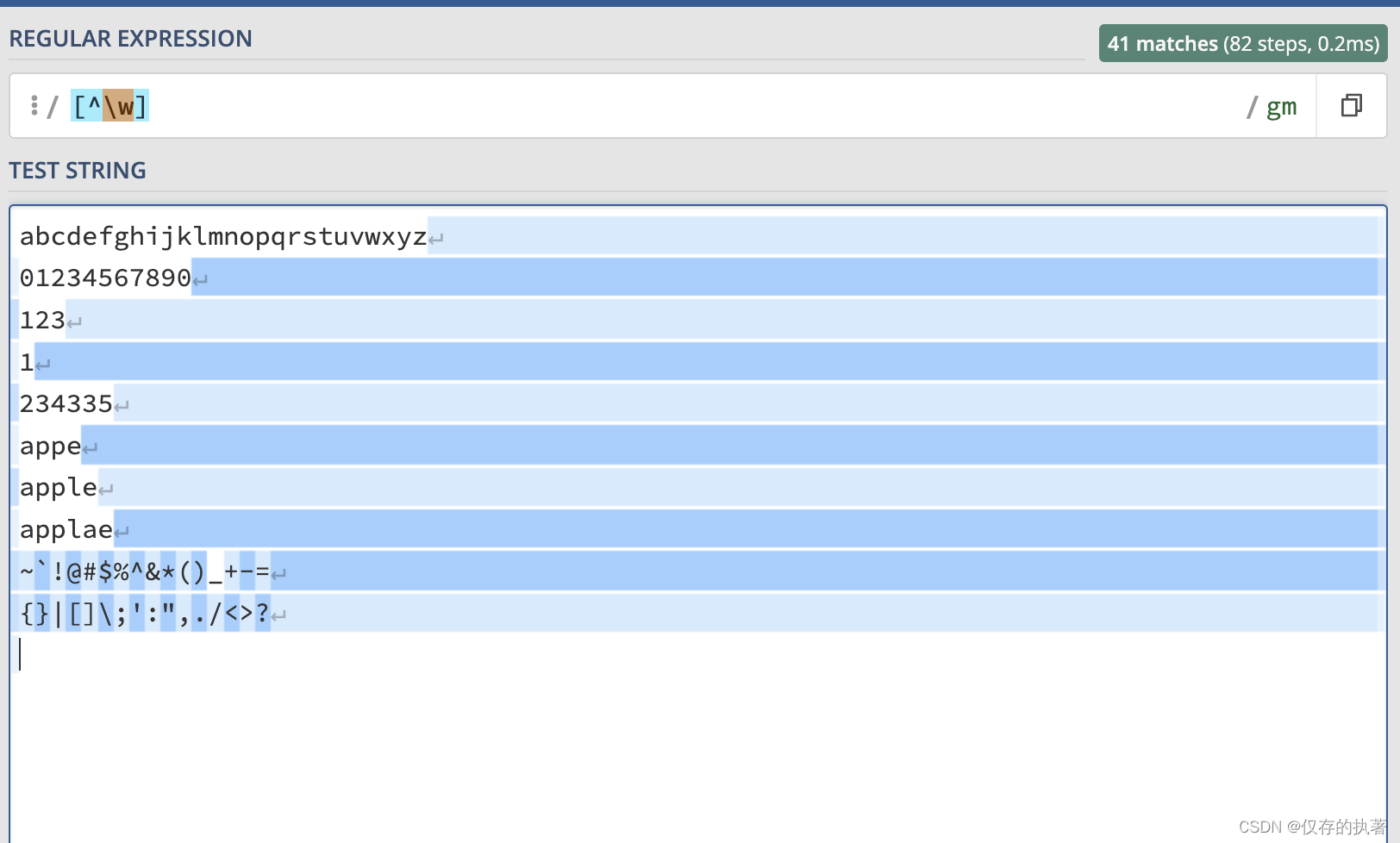
再比如:把不是字母数字下划线匹配出来,使用正则:[^\w]
4.量词
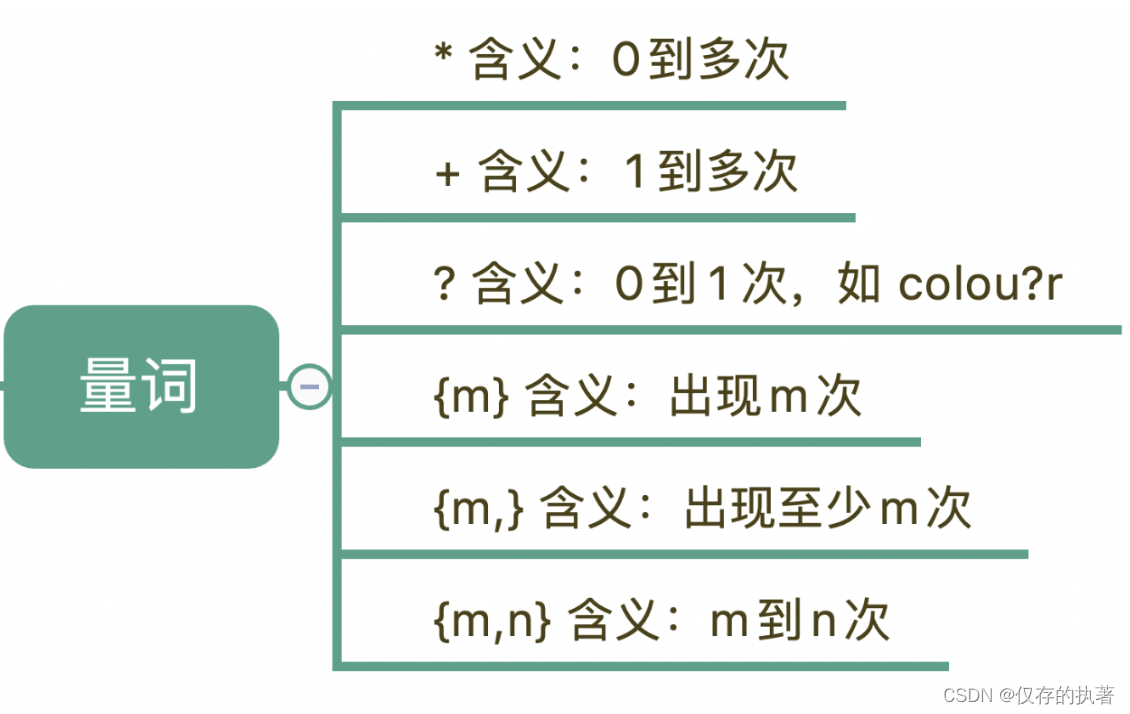
像上面\d或者空白符只能匹配单个,有时候我们需要匹配“至少1个”,或者匹配11个数字等等这个时候就需要用到正则的量词。
匹配两位数字
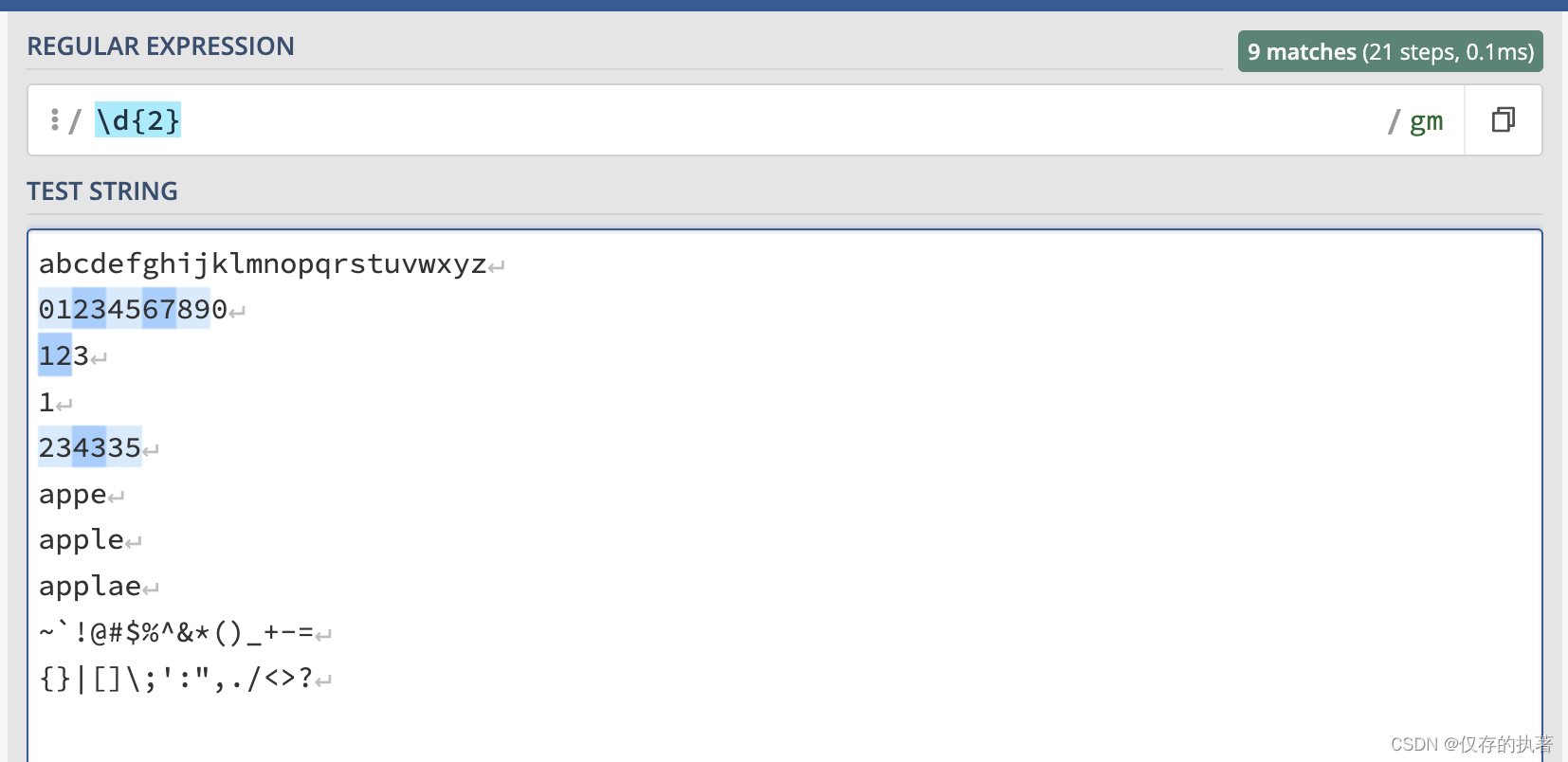
匹配结果:
01
23
45
67
89
12
23
43
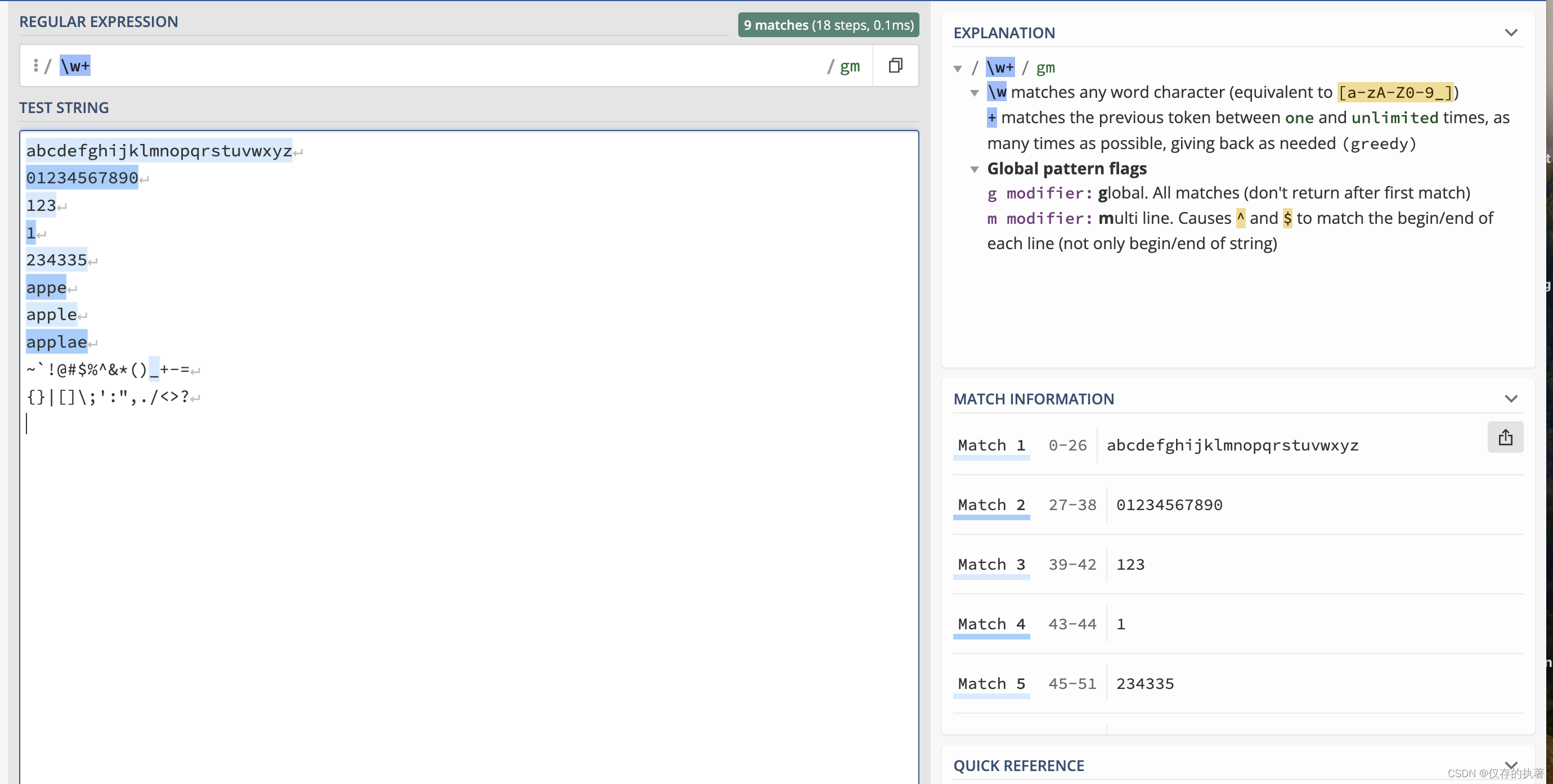
35至少出现5个字母或数字
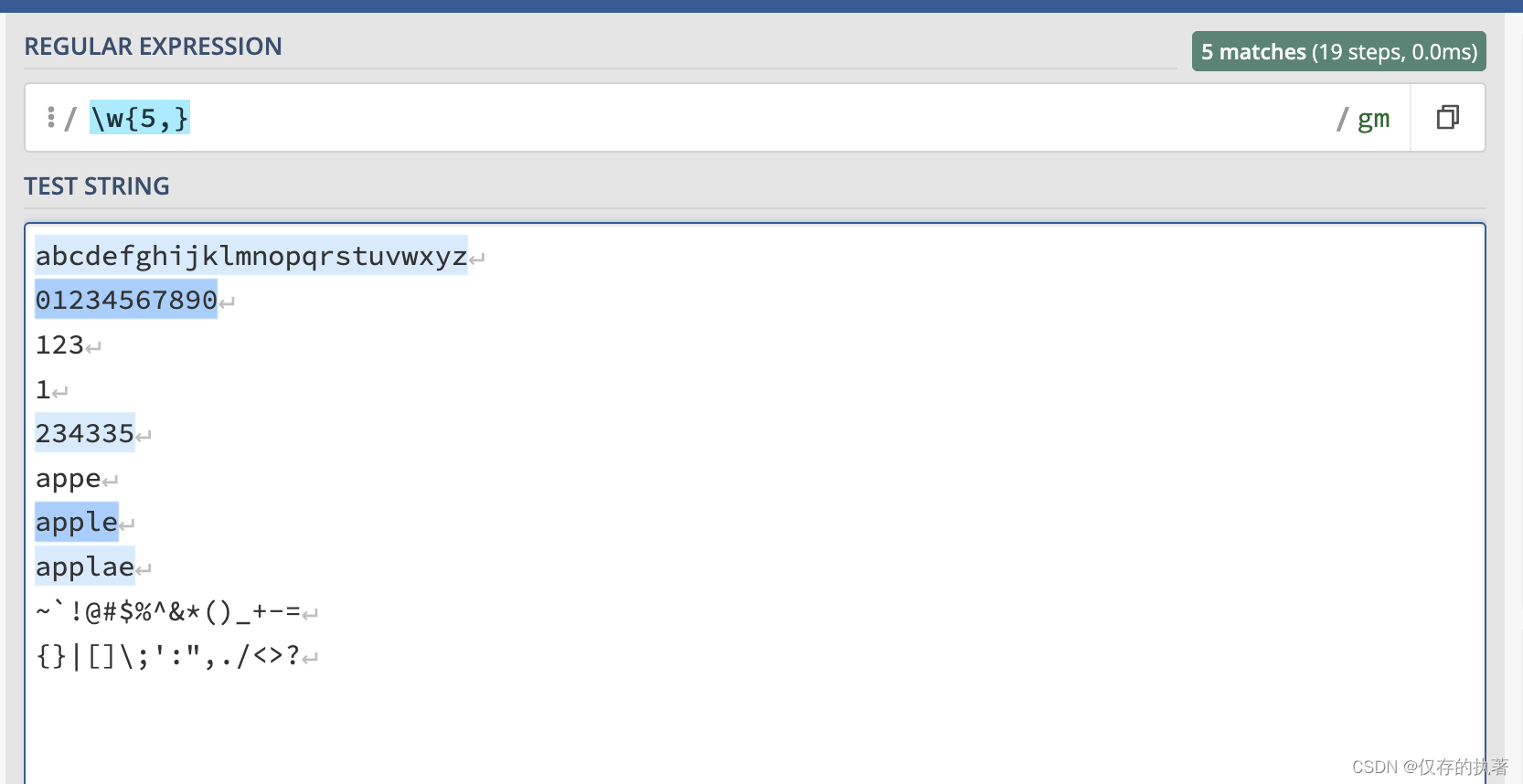
匹配结果:
abcdefghijklmnopqrstuvwxyz
01234567890
234335
apple
applae另外,
星号(0到多次)*等同于{0,}
加号(1到多次)+等同于{1,}
问号(0到1次)?等同于{0,1}
5.断言
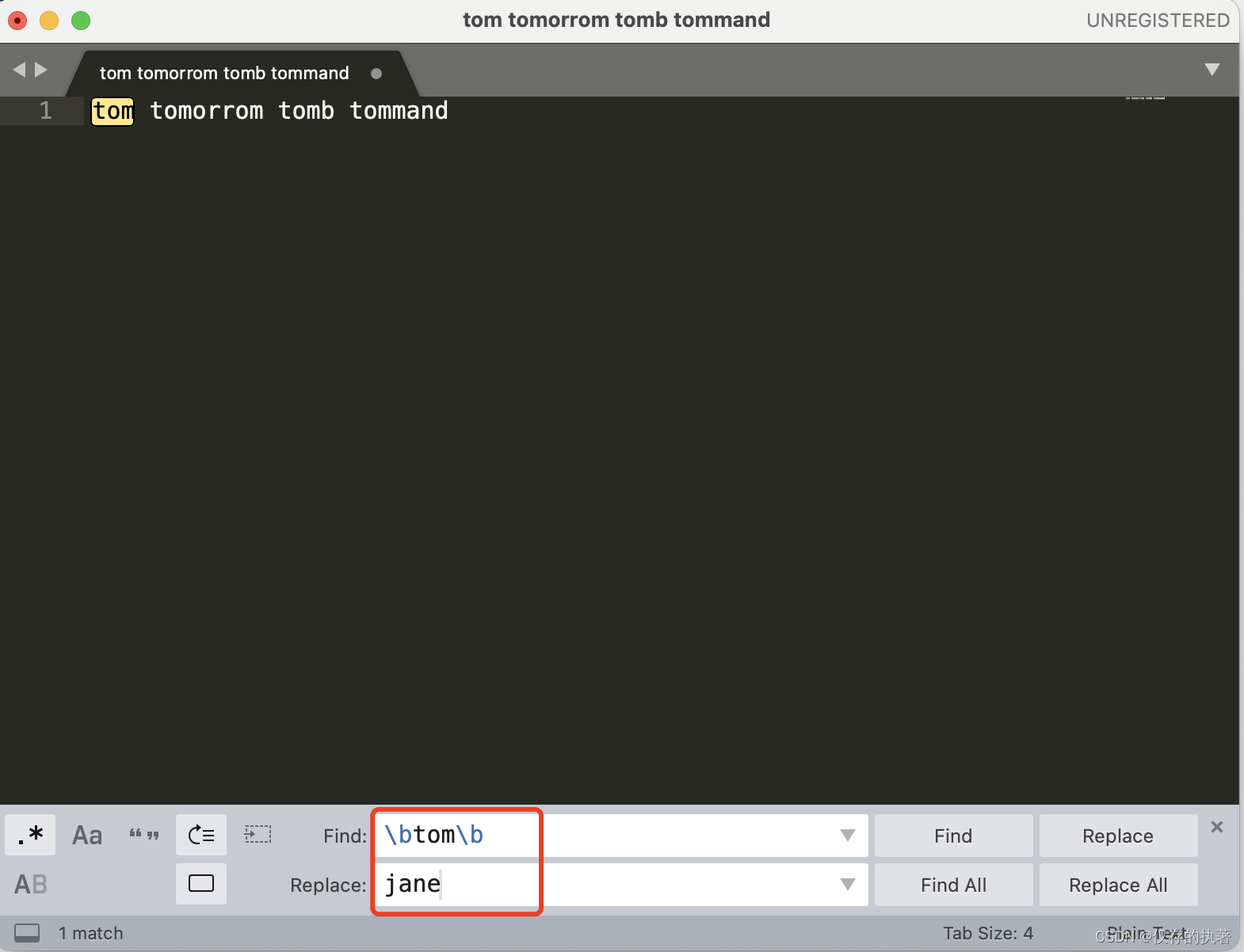
什么是断言呢?简单来说,断言是指对匹配到的文本位置有要求。比如,去查找一个单词,我们要查找 tom,但其它的单词,比如 tomorrow 中也包含了 tom。
在有些情况下,我们对要匹配的文本的位置也有一定的要求。为了解决这个问题,正则中提供了一些结构,只用于匹配位置,而不是文本内容本身,这种结构就是断言。常见的断言有三种:单词边界、行的开始或结束以及环视。
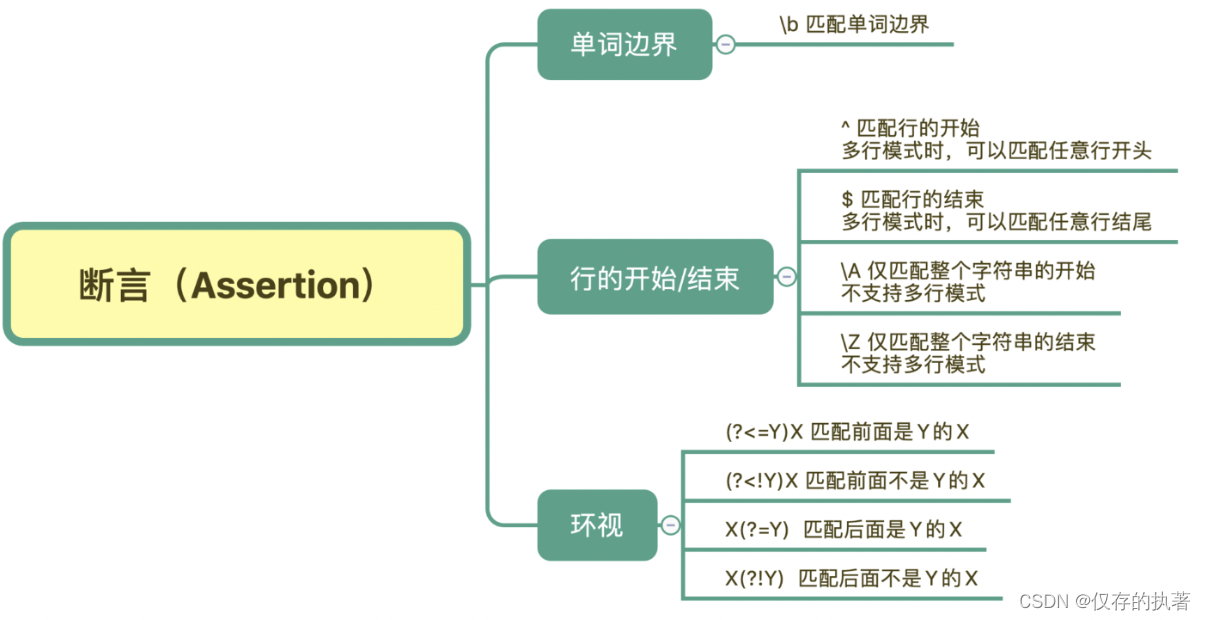
- 单词边界:\b

找到tom并替换为jane
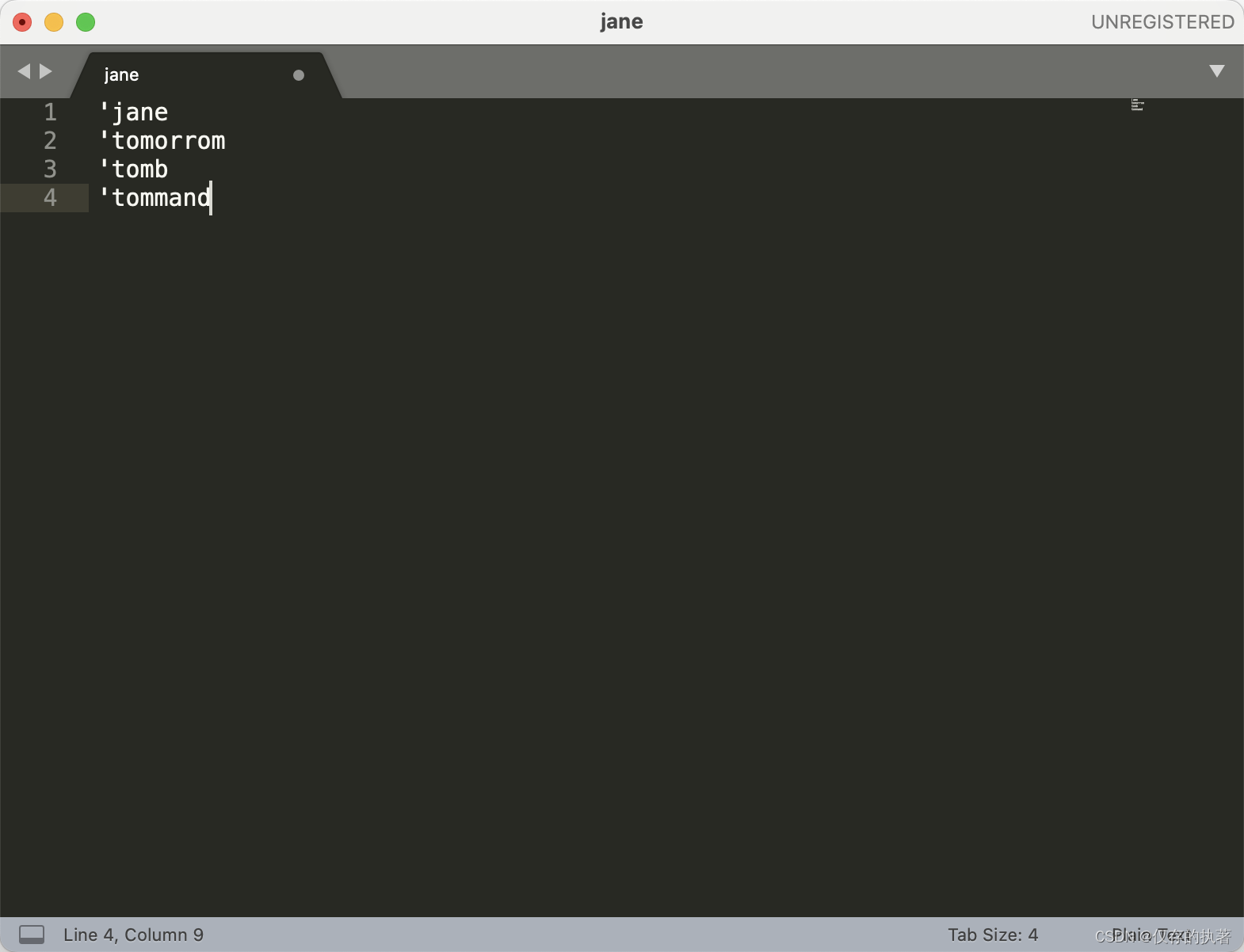
- 行的开始与结束:^和$,\A 和 \z 来匹配整个文本的开头或结尾。举例:文本的每行开头添加个单引号‘
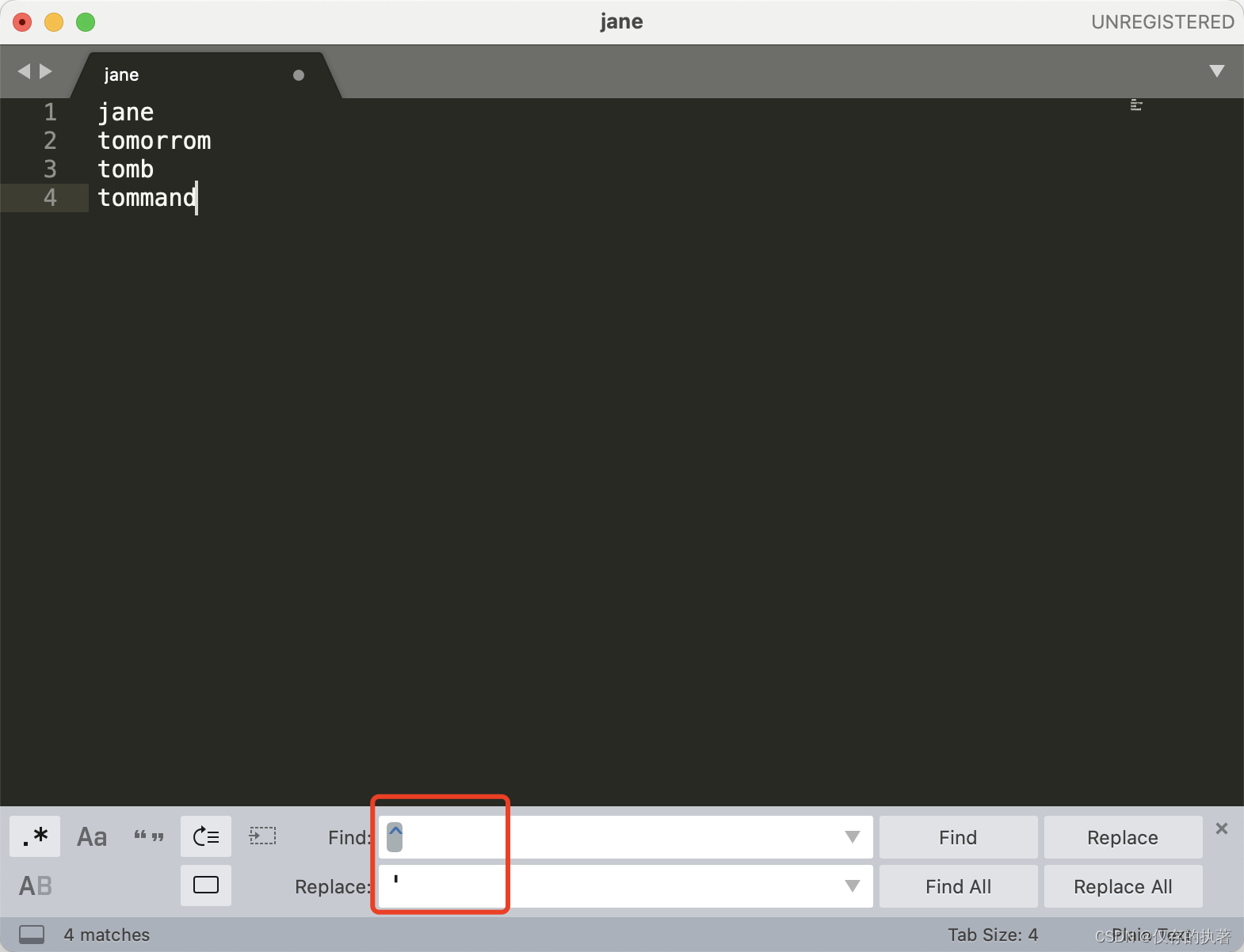
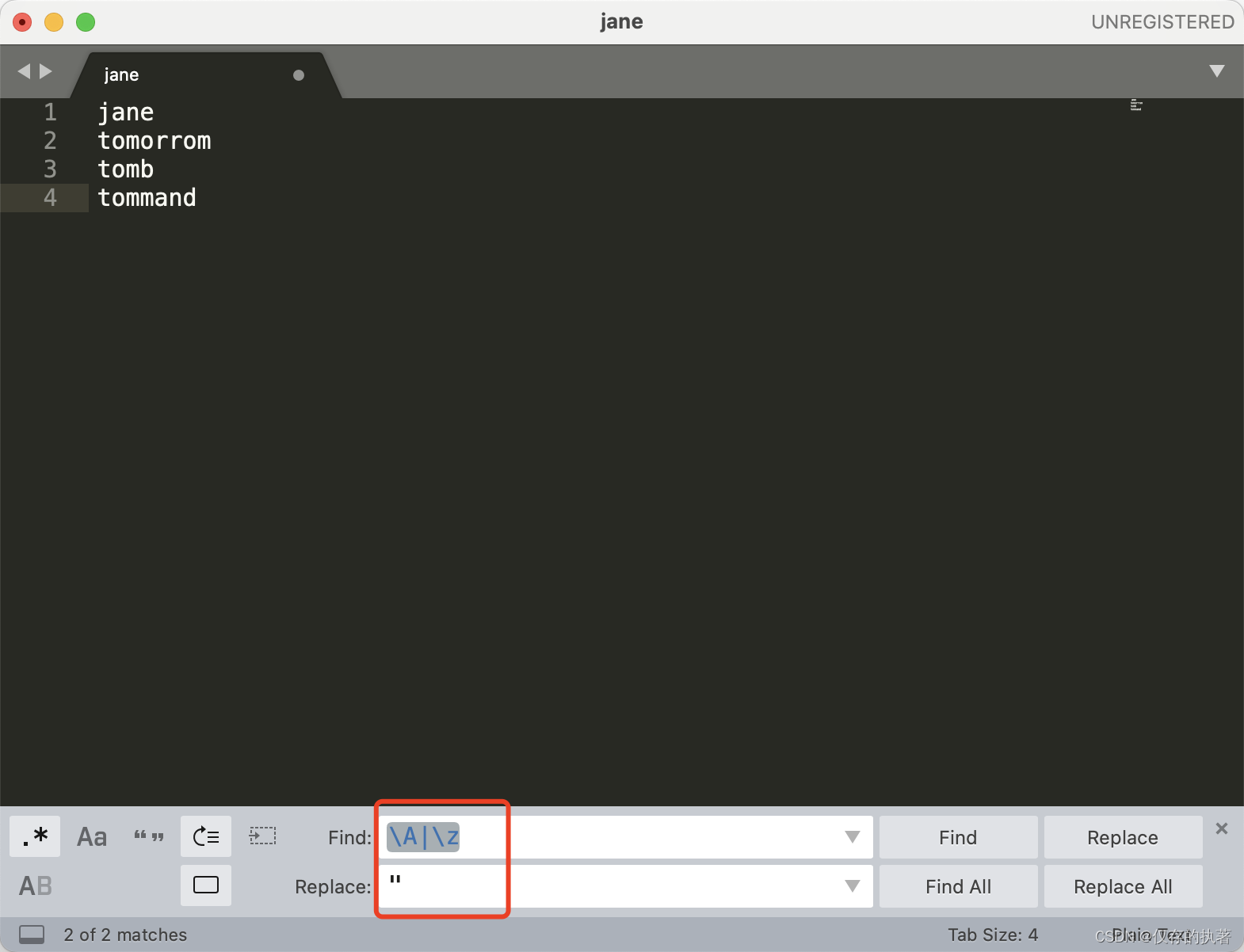
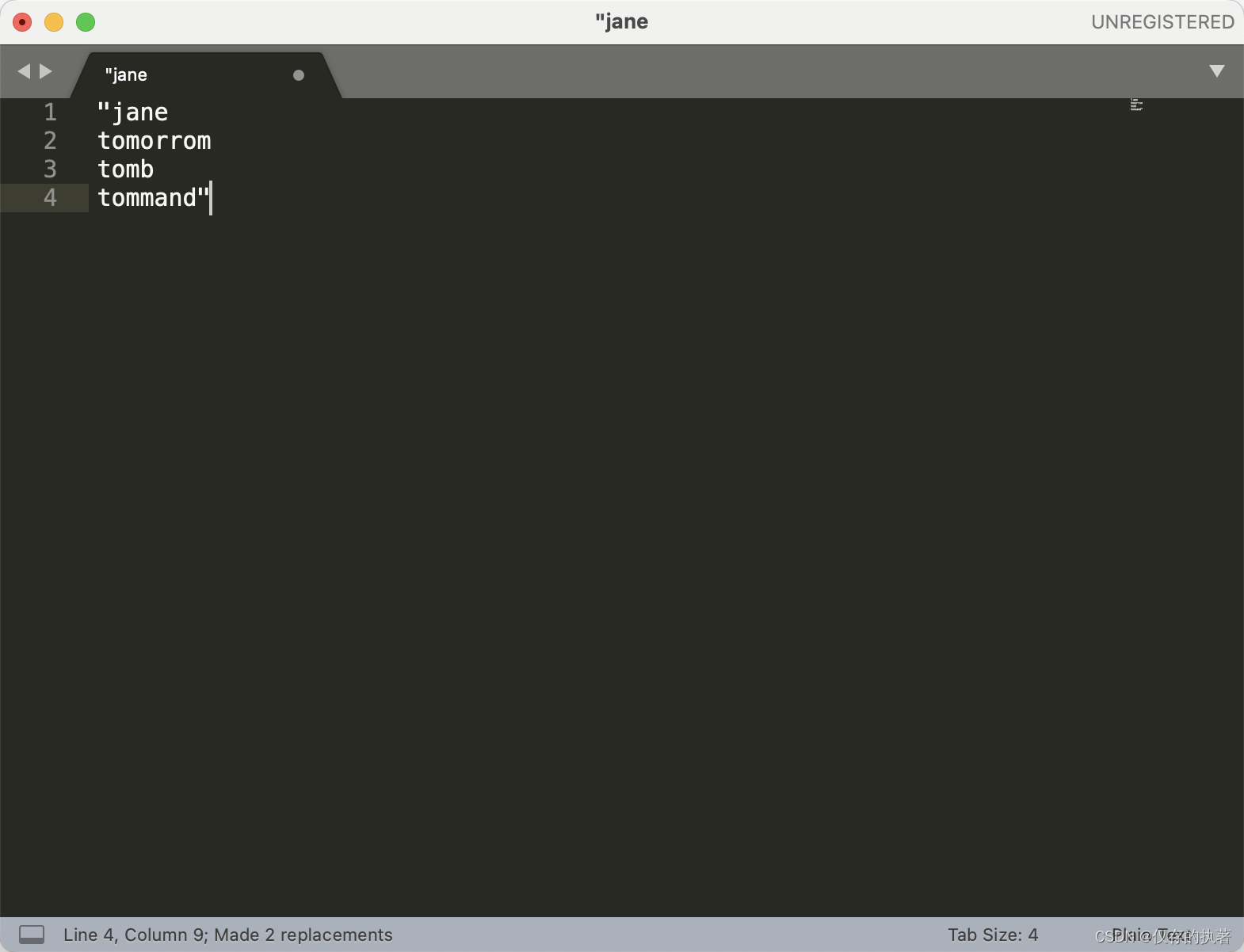
举例:在文本的开头与结尾添加个双引号"
- 环视:要求匹配部分的前面或后面要满足(或不满足)某种规则
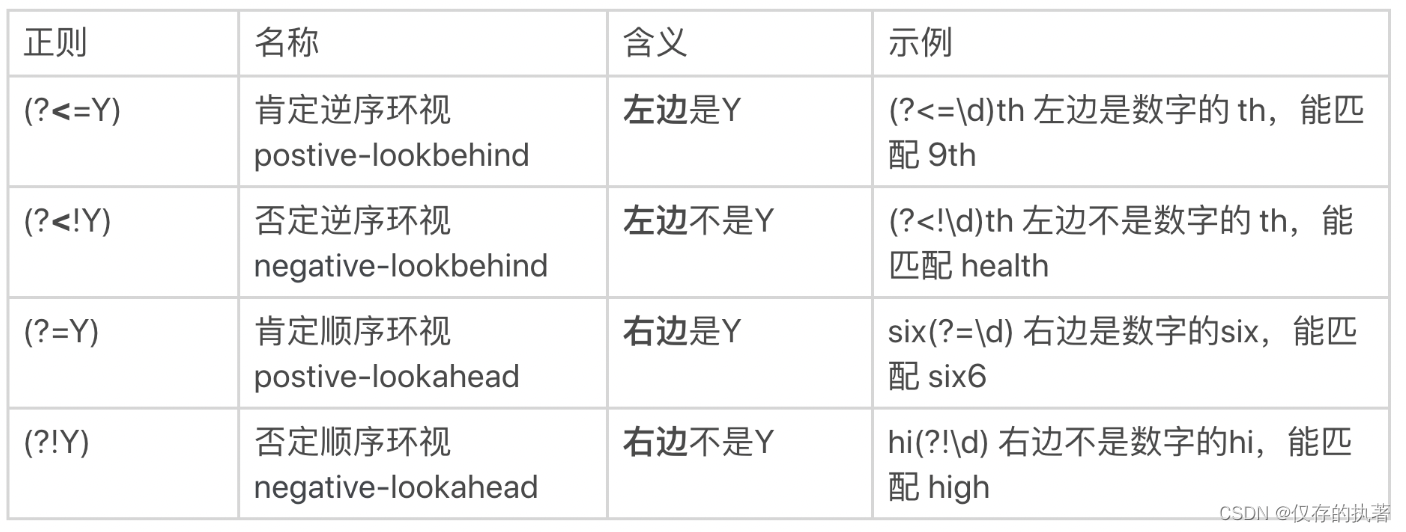
记忆口诀:左尖括号是左边,没有尖括号是右边,感叹号是非
举例:使用正则的环视提取以下文本中只有6位数字的文本
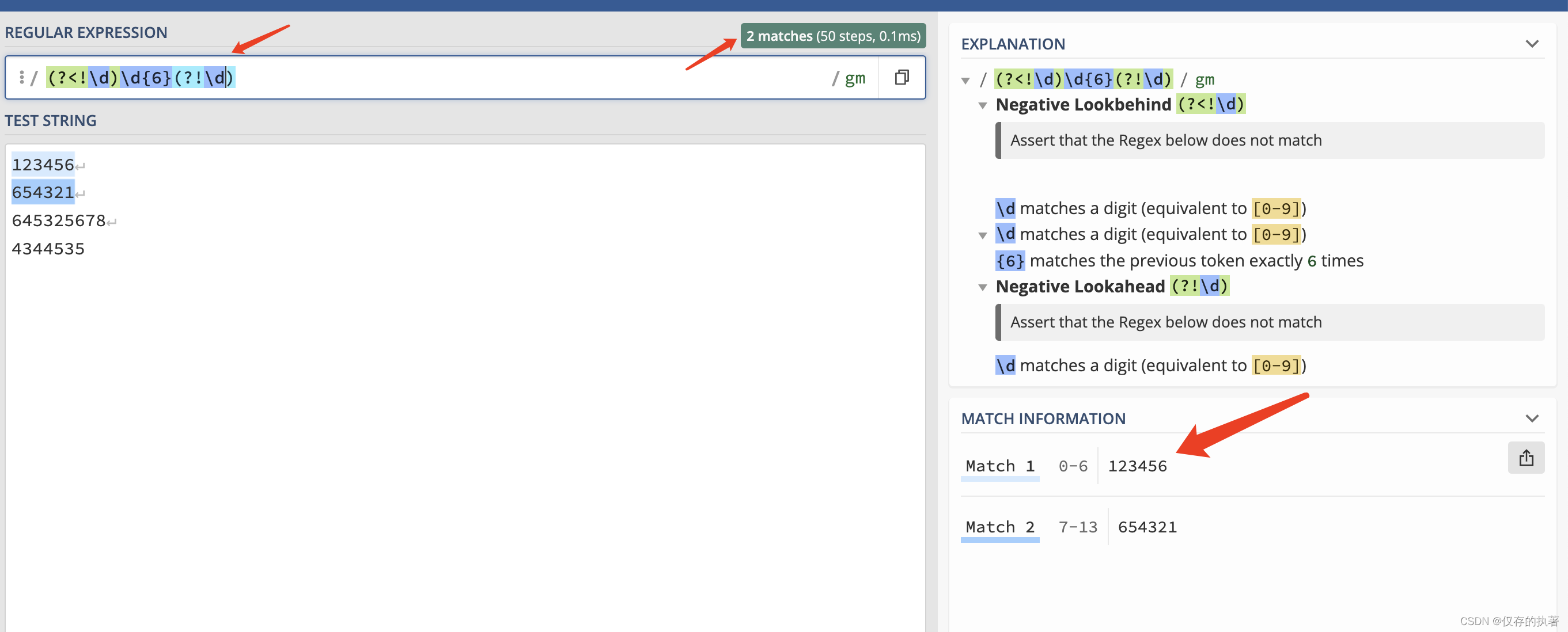
总结
以上主要介绍了正则的概念、正则的用处以及正则的基础——元字符,正则还有三种模式、分组与引用、匹配模式等等知识,后续会持续输出,敬请关注!















 1505
1505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









