






背景
由于公司服务器网络环境不通公网,每次安装新的插件都需要下载并转存到内网服务器,次数多了决定还是直接把所有插件下载回来在公司建立一个私有的插件源
实施思路
由于插件的数据巨多,一个一个点下载肯定是不现实,所以考虑到这种情况使用python 通过爬虫将插件源中所有插件目前最新版本的链接获取并下载保存到本地
依赖
python 3.6+
requests 2.28.1
BeautifulSoup 4.12.2
tqdm 4.64.1
插件源: https://mirrors.tuna.tsinghua.edu.cn/jenkins/plugins/
(我这边选择比较稳定的清华大学提供的源)
实现代码
import os
import time
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
base_url = "https://mirrors.tuna.tsinghua.edu.cn/jenkins/plugins/"
download_directory = "/jenkins_plugins"
# 创建下载目录
if not os.path.exists(download_directory):
os.makedirs(download_directory)
# 获取插件列表
response = requests.get(base_url)
soup = BeautifulSoup(response.text, "html.parser")
plugin_links = soup.find_all("a")
# 找到并获取latest版本的包
for link in plugin_links:
plugin_name = link.text
plugin_directory = base_url + plugin_name + "/latest/"
response = requests.get(plugin_directory)
soup = BeautifulSoup(response.text, "html.parser")
file_links = soup.find_all("a")
# 只下载hpi或jpi格式的插件
for file_link in file_links:
file_name = file_link["href"]
if file_name.endswith(".hpi") or file_name.endswith(".jpi"):
file_url = plugin_directory + file_name
file_path = os.path.join(download_directory, file_name)
# 检查文件是否已存在 用于重复执行该脚本
if os.path.exists(file_path):
print(f"Skipping {file_name} as it already exists.")
continue
# 下载文件
print(f"Downloading {file_name}...")
response = requests.get(file_url,stream=True)
total = int(response.headers.get('content-length', 0))
with open(file_path, "wb") as file,tqdm( # tqdm部分为显示下载进度条
desc = file_path,
total = total,
unit = 'iB',
unit_scale = True,
unit_divisor = 1024,
) as bar:
for data in response.iter_content(chunk_size=1024):
size = file.write(data)
bar.update(size)
# 每下载30个文件停止一分钟,避免被源拒绝请求,时间跟下载文件数量可以调整
if len(os.listdir(download_directory)) % 30 == 0:
print("停止1分钟")
time.sleep(60)
运行效果
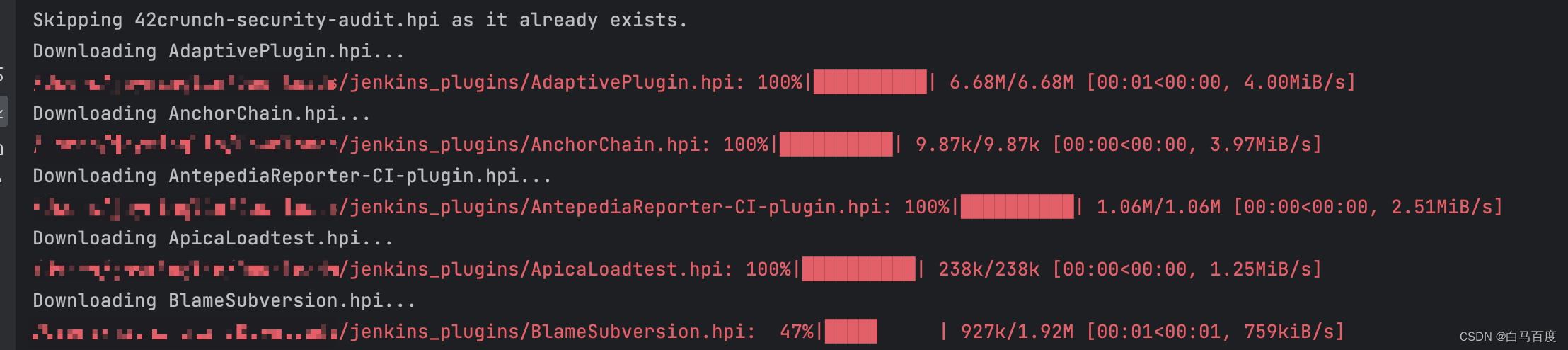
可以看到已经下载的会自动跳过以及下载的状态跟进度















 3117
3117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









