






 本文介绍了一个完整的端到端中文语音识别系统,涵盖数据处理、模型搭建及环境配置。利用THCHS30、ST-CMDS等多个数据集,采用VAD端点检测技术,提取MFCC和FBank特征,通过数据增强提升模型鲁棒性。核心模型基于Transformer,包括encoder和decoder部分,采用多头注意力机制和位置编码。
本文介绍了一个完整的端到端中文语音识别系统,涵盖数据处理、模型搭建及环境配置。利用THCHS30、ST-CMDS等多个数据集,采用VAD端点检测技术,提取MFCC和FBank特征,通过数据增强提升模型鲁棒性。核心模型基于Transformer,包括encoder和decoder部分,采用多头注意力机制和位置编码。
本文搭建的是一个完整的端到端中文语音识别系统,包括数据处理,模型搭建和系统配置等,能够将音频文件直接识别出汉字。
语音识别过程
语音输入——端点检测——提取特征——transformer模型——文本输出
目录
一、数据处理
1.数据集
| 数据集 | 时长(h) | 介绍 |
| THCHS30 | 30 | 包含了1万余条语音文件,大约30小时的中文语音数据,内容以文章诗句为主,全部为女声。它是由清华大学语音与语言技术中心(CSLT)出版的开放式中文语音数据库。 |
| ST-CMDS | 500 | 包含10万余条语音文件,数据内容以平时的网上语音聊天和智能语音控制语句为主,855个不同说话者,同时有男声和女声,适合多种场景下使用。 |
| AISHELL | 178 | 是由北京希尔公司发布的一个中文语音数据集,其中包含约178小时的开源版数据。该数据集包含400个来自中国不同地区、具有不同的口音的人的声音。录音是在安静的室内环境中使用高保真麦克风进行录音,并采样降至16kHz。通过专业的语音注释和严格的质量检查,手动转录准确率达到95%以上。 |
| Primewords | 100 | 包含了大约100小时的中文语音数据,这个免费的中文普通话语料库由上海普力信息技术有限公司发布。语料库由296名母语为英语的智能手机录制。转录准确度大于98%,置信水平为95% |
| Aidatatang_200zh | 200 | 语料库长达200小时,由Android系统手机(16kHz,16位)和iOS系统手机(16kHz,16位)记录。邀请来自中国不同重点区域的600名演讲者参加录音,录音是在安静的室内环境或环境中进行,其中包含不影响语音识别的背景噪音。参与者的性别和年龄均匀分布。语料库的语言材料是设计为音素均衡的口语句子。每个句子的手动转录准确率大于98%。 |
| Magic Data | 755 | 语料库包含755小时的语音数据,其主要是移动终端的录音数据。邀请来自中国不同重点区域的1080名演讲者参与录制。句子转录准确率高于98%。录音在安静的室内环境中进行。数据库分为训练集,验证集和测试集,比例为51:1:2。 |
2.端点检测技术(VAD)
工作环境存在着各种各样的背景噪声,这些噪声会严重降低语音的质量从而影响语音应用的效果,比如会降低识别率。端点检测是语音识别和语音处理的一个基本环节,音频端点检测就是从连续的语音流中检测出有效的语音段。它包括两个方面,检测出有效语音的起始点即前端点,检测出有效语音的结束点即后端点,主要功能有:自动打断,去掉语音中的静音成分,获取语音中的有效语音,去除噪音,对语音进行增强。

端点检测:https://blog.csdn.net/godloveyuxu/article/details/76916339
from pyvad import trim
import librosa
sig, sample_rate = librosa.load(wav_file, sr=16000)
sig = trim(sig, 16000, fs_vad=16000, hoplength=30, thr=0, vad_mode=2)3.提取特征
神经网络不能将音频作为输入进行训练,所以我们要对音频数据进行特征提取。常见的特征提取都是基于人类的发声机理和听觉感知,从发声机理到听觉感知认识声音的本质。
梅尔频率倒谱系数(MFCC), MFCC 也是基于入耳听觉特性,梅尔频率倒谱频带划分是在 Mel刻度上等距划的,Mel频率的尺度值与实际频率的对数分布关系更符合人耳的听觉特性,所以可以使得语音信号有着更好的表示。
MFCC是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性,它与频率的关系可用下式近似表示:
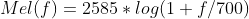
其中 f为频率,单位Hz。下图展示了Mel频率与线性频率之间的关系
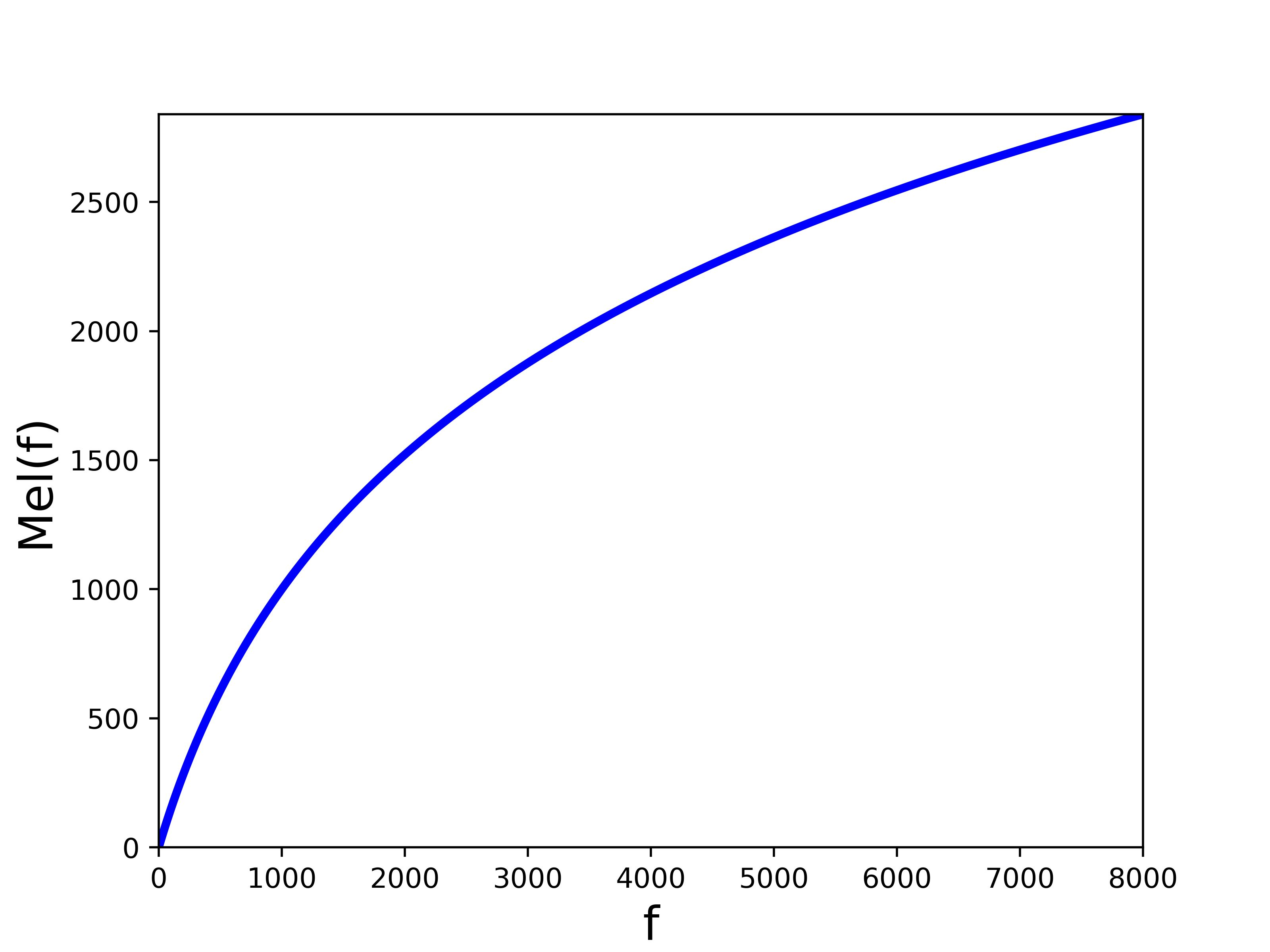
MFCC提取特征过程(详细请参考https://zhuanlan.zhihu.com/p/88625876)
语音信号——预加重——分帧——加窗——FFT——Mel滤波器组——对数运算——DCT
基于滤波器组的特征 Fbank(Filter bank), Fbank 特征提取方法就是相当 于 MFCC 去掉最后一步的离散余弦变换(有损变换),跟 MFCC 特征, Fbank 特征保留了更多的原始语音数据。
import torchaudio as ta
compute_fbank = ta.compliance.kaldi.fbank
def wav_feature(self, path, if_augment=False):
feature = self._load_wav(path)
feature = self._fbank(feature, self.params['data']['num_mel_bins'])#40
if if_augment:
feature = self.spec_augment(feature)
feature = self._normalize(feature)
return feature
def _load_wav(self, wav_file):
feature, _ = ta.load_wav(wav_file)
return feature
def _fbank(self,feature,num_mel_bins):
feature = compute_fbank(feature, num_mel_bins=num_mel_bins)
return feature
def _normalize(self, feature):
feature = (feature - feature.mean()) / feature.std()
return feature4.数据增强
训练过程中会出现过拟合现象,在现有数据情况下怎么提高准确率,通常采用增大数据量和测试样本集的方法来解决过拟合的问题,但这会增加计算成本。数据增强的技术,无需引入额外的数据,能更高效地解决自动语音识别(ASR)系统模型出现的过拟合问题。
添加噪声(随机噪声/背景噪声)
import librosa
import numpy as np
def add_noise(data):
wn = np.random.normal(0,1,len(data))
data_noise = np.where(data != 0.0, data.astype('float64') + 0.02 * wn, 0.0).astype(np.float32)
return data_noise
data, fs = librosa.load('1.wav')
data_noise = add_noise(data)振幅和音速的变化
音高变化增量是围绕频率轴的±10%范围内的随机滚动,时移增强是通过沿时间轴滚动信号来随机移位信号。
def _aug_amplitude(self,sig):
nsig = sig*random.uniform(0.9, 1.1)
return nsig
def _aug_speed(self, sig):
speed_rate = random.Random().uniform(0.9, 1.1)
old_length = sig.shape[1]
new_length = int(sig.shape[1] / speed_rate)
old_indices = np.arange(old_length)
new_indices = np.linspace(start=0, stop=old_length, num=new_length)
sig[0] = np.interp(new_indices, old_indices, sig[0])
return nsig频域的增强
def spec_augment(self, feature, frequency_mask_num=1, time_mask_num=2,
frequency_masking_para=27, time_masking_para=15):
tau = feature.shape[0]
v = feature.shape[1]
warped_feature = feature
# Step 2 : Frequency masking
if frequency_mask_num > 0:
for i in range(frequency_mask_num):
f = np.random.uniform(low=0.0, high=frequency_masking_para)
f = int(f)
f0 = random.randint(0, v-f)
warped_feature[:, f0:f0+f] = 0
# Step 3 : Time masking
if time_mask_num > 0:
for i in range(time_mask_num):
t = np.random.uniform(low=0.0, high=time_masking_para)
t = int(t)
t0 = random.randint(0, tau-t)
warped_feature[t0:t0+t, :] = 0
return warped_feature二、模型搭建
transformer模型
是谷歌在17年做机器翻译任务的“Attention is all you need”的论文中提出的,引起了相当大的反响,Transformer模型中也采用了 encoer-decoder 架构。
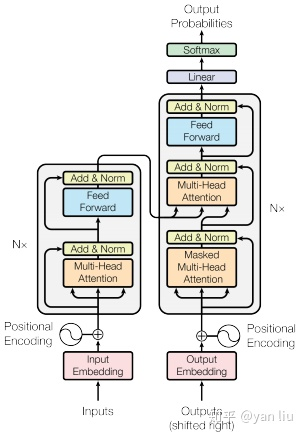
encoder
对于encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。
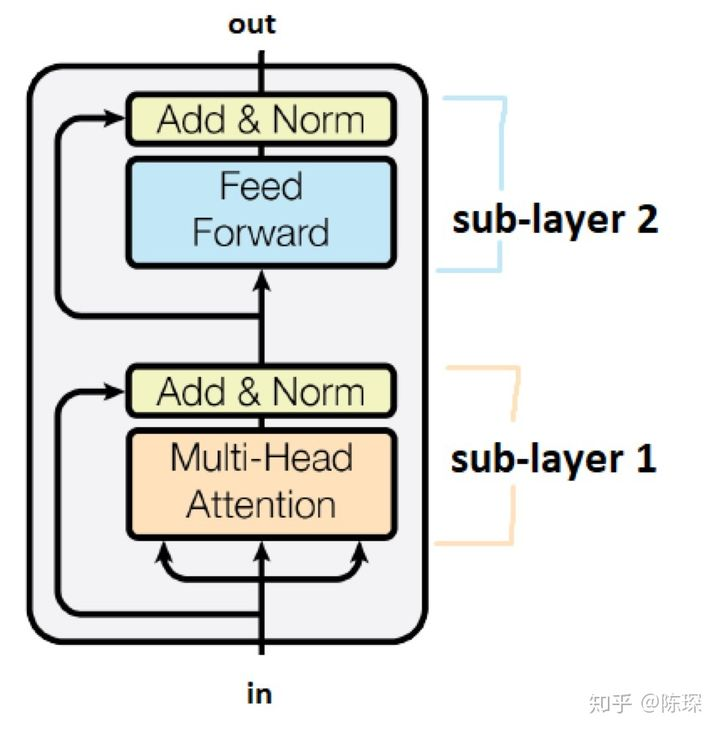
self_attention:首先,self-attention会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和embedding的维度一样,而在音频领域是用特征向量乘以三个不同权值矩阵(随机初始化)得到Q,K,V。
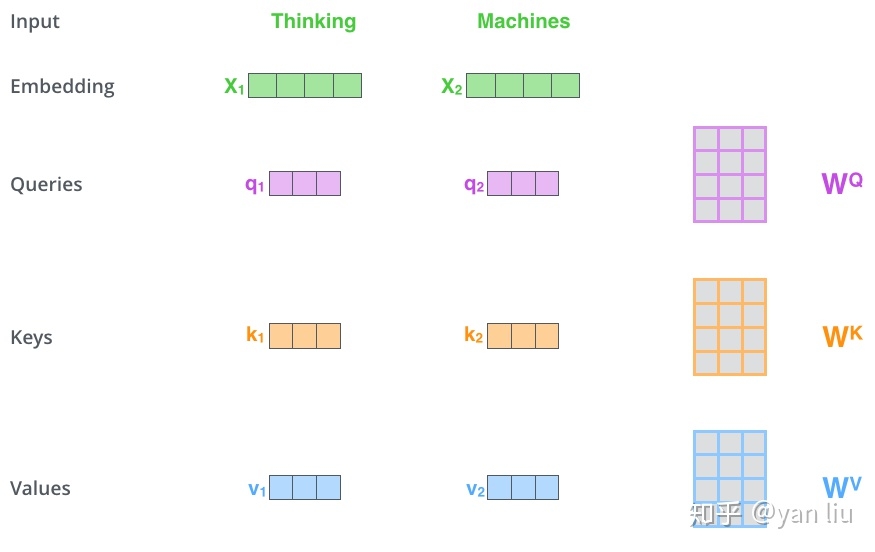
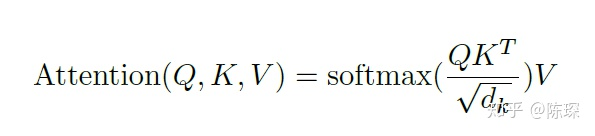
矩阵乘法表示
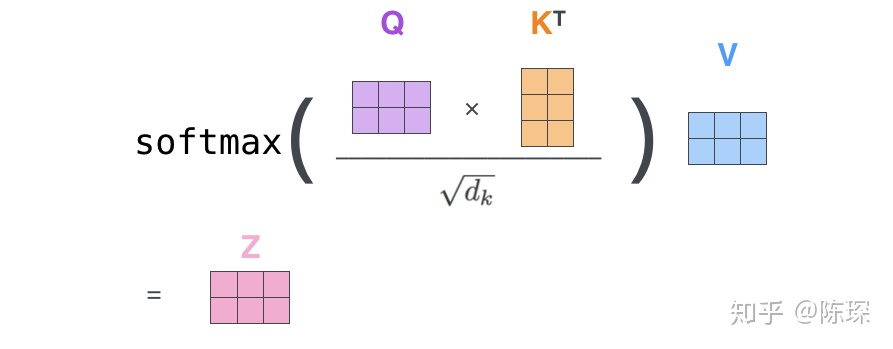
其过程:
1.输入音频的特征向量
2.根据特征向量得到Q,K,V 三个向量
3.为每个向量计算一个score:
4.为了梯度的稳定,Transformer使用了缩放,即除以
5.对score施以softmax激活函数
6.softmax点乘Value值 v,得到加权的每个输入向量的评分 v
7.相加之后得到最终的输出结果 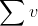
在self-attention需要强调的最后一点是其采用了残差网络,目的当然是解决深度学习中的退化问题。
class TransformerEncoder(nn.Module):
def __init__(self, input_size, d_model=256, attention_heads=4, linear_units=2048, num_blocks=6, pos_dropout_rate=0.0,
slf_attn_dropout_rate=0.0, ffn_dropout_rate=0.0, residual_dropout_rate=0.1, input_layer="conv2d",
normalize_before=True, concat_after=False, activation='relu', type='transformer'):
super(TransformerEncoder, self).__init__()
self.normalize_before = normalize_before
if input_layer == "linear":
self.embed = LinearWithPosEmbedding(input_size, d_model, pos_dropout_rate)
elif input_layer == "conv2d":
self.embed = Conv2dSubsampling(input_size, d_model, pos_dropout_rate)
elif input_layer == 'conv2dv2':
self.embed = Conv2dSubsamplingV2(input_size, d_model, pos_dropout_rate)
self.blocks = nn.ModuleList([
TransformerEncoderLayer(attention_heads, d_model, linear_units, slf_attn_dropout_rate, ffn_dropout_rate,
residual_dropout_rate=residual_dropout_rate, normalize_before=normalize_before,
concat_after=concat_after, activation=activation) for _ in range(num_blocks)
])
if self.normalize_before:
self.after_norm = LayerNorm(d_model)
def forward(self, inputs, input_length, streaming=False):
enc_mask = get_enc_padding_mask(inputs, input_length)
enc_output, enc_mask = self.embed(inputs, enc_mask)
enc_output.masked_fill_(~enc_mask.transpose(1, 2), 0.0)
# if streaming:
# length = torch.sum(enc_mask.squeeze(1), dim=-1)
# enc_mask = get_streaming_mask(enc_output, length, left_context=20, right_context=0)
for _, block in enumerate(self.blocks):
enc_output, enc_mask = block(enc_output, enc_mask)
enc_output.masked_fill_(~enc_mask.transpose(1, 2), 0.0)
if self.normalize_before:
enc_output = self.after_norm(enc_output)
return enc_output, enc_mask
class TransformerEncoderLayer(nn.Module):
def __init__(self, attention_heads, d_model, linear_units, slf_attn_dropout_rate,
ffn_dropout_rate, residual_dropout_rate, normalize_before=False,
concat_after=False, activation='relu'):
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiHeadedAttention(attention_heads, d_model, slf_attn_dropout_rate)
self.feed_forward = PositionwiseFeedForward(d_model, linear_units, ffn_dropout_rate, activation)
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(residual_dropout_rate)
self.dropout2 = nn.Dropout(residual_dropout_rate)
self.normalize_before = normalize_before
self.concat_after = concat_after
if self.concat_after:
self.concat_linear = nn.Linear(d_model * 2, d_model)
def forward(self, x, mask):
"""Compute encoded features
:param torch.Tensor x: encoded source features (batch, max_time_in, size)
:param torch.Tensor mask: mask for x (batch, max_time_in)
:rtype: Tuple[torch.Tensor, torch.Tensor]
"""
residual = x
if self.normalize_before:
x = self.norm1(x)
if self.concat_after:
x_concat = torch.cat((x, self.self_attn(x, x, x, mask)), dim=-1)
x = residual + self.concat_linear(x_concat)
else:
x = residual + self.dropout1(self.self_attn(x, x, x, mask))
if not self.normalize_before:
x = self.norm1(x)
residual = x
if self.normalize_before:
x = self.norm2(x)
x = residual + self.dropout2(self.feed_forward(x))
if not self.normalize_before:
x = self.norm2(x)
return x, maskfeed-forward network:
class PositionwiseFeedForward(nn.Module):
"""Positionwise feed forward
:param int idim: input dimenstion
:param int hidden_units: number of hidden units
:param float dropout_rate: dropout rate
"""
def __init__(self, idim, hidden_units, dropout_rate, activation='relu'):
super(PositionwiseFeedForward, self).__init__()
self.activation = activation
self.w_1 = nn.Linear(idim, hidden_units * 2 if activation == 'glu' else hidden_units)
self.w_2 = nn.Linear(hidden_units, idim)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, x):
x = self.w_1(x)
if self.activation == 'relu':
x = F.relu(x)
elif self.activation == 'tanh':
x = F.tanh(x)
elif self.activation == 'glu':
x = F.glu(x)
else:
raise NotImplementedError
return self.w_2(self.dropout(x))Multi-Head Attention相当于 h个不同的self-attention的集成
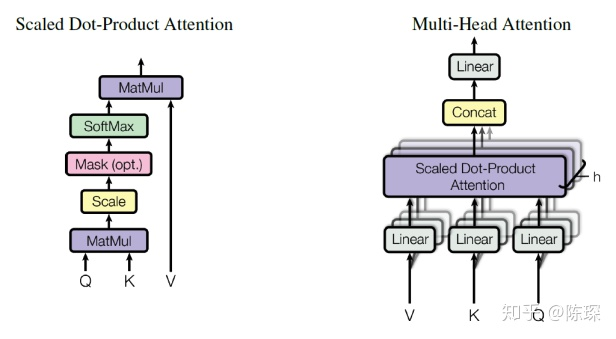
class MultiHeadedAttention(nn.Module):
"""Multi-Head Attention layer
:param int n_head: the number of head s
:param int n_feat: the number of features
:param float dropout_rate: dropout rate
"""
def __init__(self, n_head, n_feat, dropout_rate):
super(MultiHeadedAttention, self).__init__()
assert n_feat % n_head == 0
# We assume d_v always equals d_k
self.d_k = n_feat // n_head
self.h = n_head
self.linear_q = nn.Linear(n_feat, n_feat)
self.linear_k = nn.Linear(n_feat, n_feat)
self.linear_v = nn.Linear(n_feat, n_feat)
self.linear_out = nn.Linear(n_feat, n_feat)
self.attn = None
self.dropout = nn.Dropout(p=dropout_rate)
def forward(self, query, key, value, mask):
n_batch = query.size(0)
q = self.linear_q(query).view(n_batch, -1, self.h, self.d_k)
k = self.linear_k(key).view(n_batch, -1, self.h, self.d_k)
v = self.linear_v(value).view(n_batch, -1, self.h, self.d_k)
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
mask = mask.unsqueeze(1).eq(0)
min_value = float(numpy.finfo(torch.tensor(0, dtype=scores.dtype).numpy().dtype).min)
scores = scores.masked_fill(mask, min_value)
self.attn = torch.softmax(scores, dim=-1).masked_fill(mask, 0.0)
else:
self.attn = torch.softmax(scores, dim=-1)
p_attn = self.dropout(self.attn)
x = torch.matmul(p_attn, v) # (batch, head, time1, d_k)
x = x.transpose(1, 2).contiguous().view(n_batch, -1, self.h * self.d_k) # (batch, time1, d_model)
return self.linear_out(x) # (batch, time1, d_model)Position Embedding:我们介绍的Transformer模型目前并没有捕捉顺序序列的能力,论文中在编码词向量时引入了位置编码的特征,论文给出的编码公式如下:
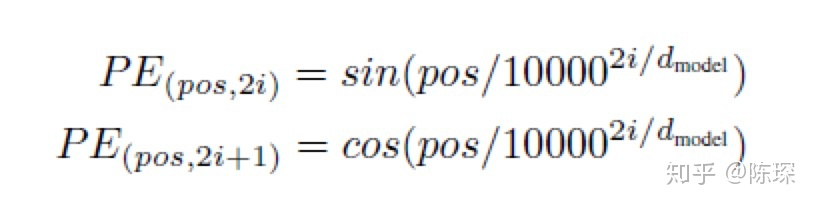
pos表示单词的位置, i表示单词的维度,在音频上pos表示时间的位置,i表示某一时间节点的维度。transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,或者说在一个句子中不同的词之间的距离。
class LinearWithPosEmbedding(nn.Module):
def __init__(self, input_size, d_model, dropout_rate=0.0):
super(LinearWithPosEmbedding, self).__init__()
self.linear = nn.Linear(input_size, d_model)
# self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout_rate)
self.activation = nn.ReLU()
self.pos_embedding = PositionalEncoding(d_model, pos_dropout_rate)
def forward(self, inputs, mask):
inputs = self.linear(inputs)
# inputs = self.norm(inputs)
inputs = self.activation(self.dropout(inputs))
encoded_inputs = self.pos_embedding(inputs)
return encoded_inputs, mask位置详细介绍:https://zhuanlan.zhihu.com/p/92017824
decoder
Decoder SubLayer-1 使用的是 “masked” Multi-Headed Attention 机制,防止为了模型看到要预测的数据,防止泄露。
确保生成位置i的预测时,仅依赖小于i的位置处的已知输出,相当于把后面不该看到的信息屏蔽掉。
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])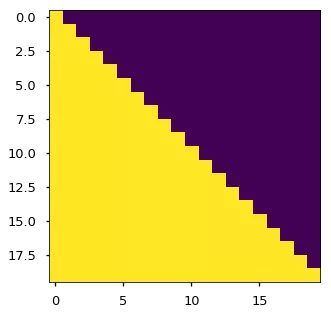
class TransformerDecoder(nn.Module):
def __init__(self, output_size, d_model=256, attention_heads=4, linear_units=2048, num_blocks=6, pos_dropout_rate=0.0,
slf_attn_dropout_rate=0.0, src_attn_dropout_rate=0.0, ffn_dropout_rate=0.0, residual_dropout_rate=0.1,
activation='relu', normalize_before=True, concat_after=False, share_embedding=False):
super(TransformerDecoder, self).__init__()
self.normalize_before = normalize_before
self.embedding = torch.nn.Embedding(output_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, pos_dropout_rate)
self.blocks = nn.ModuleList([
TransformerDecoderLayer(attention_heads, d_model, linear_units, slf_attn_dropout_rate, src_attn_dropout_rate,
ffn_dropout_rate, residual_dropout_rate, normalize_before=normalize_before, concat_after=concat_after,
activation=activation) for _ in range(num_blocks)
])
if self.normalize_before:
self.after_norm = LayerNorm(d_model)
self.output_layer = nn.Linear(d_model, output_size)
if share_embedding:
assert self.embedding.weight.size() == self.output_layer.weight.size()
self.output_layer.weight = self.embedding.weight
def forward(self, targets, target_length, memory, memory_mask):
dec_output = self.embedding(targets)
dec_output = self.pos_encoding(dec_output)
dec_mask = get_dec_seq_mask(targets, target_length)
for _, block in enumerate(self.blocks):
dec_output, dec_mask = block(dec_output, dec_mask, memory, memory_mask)
if self.normalize_before:
dec_output = self.after_norm(dec_output)
logits = self.output_layer(dec_output)
return logits, dec_mask
class TransformerDecoderLayer(nn.Module):
def __init__(self, attention_heads, d_model, linear_units, slf_attn_dropout_rate, src_attn_dropout_rate,
ffn_dropout_rate, residual_dropout_rate, normalize_before=True, concat_after=False, activation='relu'):
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiHeadedAttention(attention_heads, d_model, slf_attn_dropout_rate)
self.src_attn = MultiHeadedAttention(attention_heads, d_model, src_attn_dropout_rate)
self.feed_forward = PositionwiseFeedForward(d_model, linear_units, ffn_dropout_rate, activation)
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.norm3 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(residual_dropout_rate)
self.dropout2 = nn.Dropout(residual_dropout_rate)
self.dropout3 = nn.Dropout(residual_dropout_rate)
self.normalize_before = normalize_before
self.concat_after = concat_after
if self.concat_after:
self.concat_linear1 = nn.Linear(d_model * 2, d_model)
self.concat_linear2 = nn.Linear(d_model * 2, d_model)
def forward(self, tgt, tgt_mask, memory, memory_mask):
"""Compute decoded features
:param torch.Tensor tgt: decoded previous target features (batch, max_time_out, size)
:param torch.Tensor tgt_mask: mask for x (batch, max_time_out)
:param torch.Tensor memory: encoded source features (batch, max_time_in, size)
:param torch.Tensor memory_mask: mask for memory (batch, max_time_in)
"""
residual = tgt
if self.normalize_before:
tgt = self.norm1(tgt)
if self.concat_after:
tgt_concat = torch.cat((tgt, self.self_attn(tgt, tgt, tgt, tgt_mask)), dim=-1)
x = residual + self.concat_linear1(tgt_concat)
else:
x = residual + self.dropout1(self.self_attn(tgt, tgt, tgt, tgt_mask))
if not self.normalize_before:
x = self.norm1(x)
residual = x
if self.normalize_before:
x = self.norm2(x)
if self.concat_after:
x_concat = torch.cat((x, self.src_attn(x, memory, memory, memory_mask)), dim=-1)
x = residual + self.concat_linear2(x_concat)
else:
x = residual + self.dropout2(self.src_attn(x, memory, memory, memory_mask))
if not self.normalize_before:
x = self.norm2(x)
residual = x
if self.normalize_before:
x = self.norm3(x)
x = residual + self.dropout3(self.feed_forward(x))
if not self.normalize_before:
x = self.norm3(x)
return x, tgt_mask
def get_dec_seq_mask(targets, targets_length=None):
steps = targets.size(-1)
padding_mask = targets.ne(PAD).unsqueeze(-2).bool()
seq_mask = torch.ones([steps, steps], device=targets.device)
seq_mask = torch.tril(seq_mask).bool()
seq_mask = seq_mask.unsqueeze(0)
return seq_mask & padding_mask当decoder层全部执行完毕后,怎么把得到的向量映射为我们需要的词呢,很简单,只需要在结尾再添加一个全连接层和softmax层,假如我们的词典是5000个词,那最终softmax会输入5000个词的概率,概率值最大的对应的词就是我们最终的结果。
其他设置:损失函数交叉熵损失函数,梯度优化器adam
三、环境配置
pytorch=1.2.0
torchaudio=0.3.0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









