







一、技术背景
近年来,大型语言模型(LLMs)如GPT系列、Qwen2.5、DeepSeek R1、Gemini2.5 pro等,在自然语言处理及更广泛的人工智能领域展现出革命性的能力。这些模型通常拥有数百亿甚至数万亿的参数,其训练和推理过程对计算资源提出了前所未有的要求。单个计算设备(如GPU)的内存容量和计算能力远不足以支撑如此庞大的模型,因此,分布式计算成为训练和部署LLM的必然选择。
在分布式LLM系统中,横跨数千甚至数万个GPU的高效通信至关重要。网络互连作为分布式系统的“神经系统”,其性能直接决定了整个集群的计算效率、训练时间和推理延迟。模型并行(特别是张量并行)、流水线并行和数据并行等分布式策略都依赖于节点间频繁的数据交换,如梯度聚合(All-Reduce)、参数同步(AllGather/ReduceScatter)以及中间结果传递(Send/Recv)。网络带宽不足、延迟过高或拓扑结构不合理都可能导致GPU计算单元长时间闲置,严重影响训练效率和推理服务质量(SLO)。
本综述旨在深入探讨用于支持大规模LLM分布式训练和推理的高性能网络技术。内容将涵盖LLM对网络性能的具体需求与挑战,分析主流网络技术(InfiniBand, RoCE, NVLink/NVSwitch)的特性与局限,研究不同网络拓扑(Fat-Tree, Torus, Dragonfly, Rail-only, HammingMesh)的适用性,探索通信优化软件库与技术(NCCL, MPI, ZeRO, 通信调度),总结关键性能评估指标与方法,比较不同解决方案的实际性能与成本效益,并展望未来发展趋势(光互连, 网络内计算, 软硬件协同设计)。
1.1 LLM训练的网络需求
LLM训练通常结合数据并行(DP)、张量并行(TP)和流水线并行(PP)等多种并行策略(统称为3D并行或4D并行,以应对巨大的计算量和模型参数存储需求。这些并行策略产生了复杂的通信模式,对网络性能提出了极高的要求:
-
高带宽: 训练过程中涉及大量的集体通信操作。数据并行需要在每一步梯度计算后进行全局梯度同步(通常使用All-Reduce操作)。张量并行则需要在模型层的计算过程中交换激活值或部分结果(如All-Reduce、AllGather、ReduceScatter)。流水线并行涉及在不同流水线阶段之间传递激活值和梯度(点对点通信)。特别是对于包含数十亿甚至上万亿参数的模型,这些通信操作传输的数据量巨大,要求网络提供极高的聚合带宽(数百Gbps甚至Tbps级别)以避免成为瓶颈 。
-
低延迟: 训练过程通常是同步进行的,网络延迟直接影响到节点间的同步效率和总训练时间。高延迟会导致GPU等待通信完成而空闲,降低计算资源的利用率 。对于流水线并行,延迟还会加剧“流水线气泡”(pipeline bubble),即流水线启动和排空阶段的空闲时间。因此,实现微秒级的低网络延迟对于高效训练至关重要 。
-
可靠性与稳定性: LLM训练任务通常持续数周甚至数月。在此期间,网络必须保持高度的可靠性和稳定性。任何网络中断或性能波动都可能导致训练中断、模型状态丢失或训练时间延长,造成巨大的计算资源浪费。因此,网络需要具备良好的容错能力和快速故障恢复机制。
-
可扩展性: 随着模型规模的持续增长,训练所需的GPU集群规模也在不断扩大,从数千扩展到数万甚至更多。网络架构必须能够经济高效地扩展到如此大的规模,同时保持高性能。
-
特定通信模式支持:
-
ZeRO优化器: ZeRO系列优化器通过分片存储优化器状态、梯度和模型参数来大幅降低单GPU内存消耗,但代价是引入了更频繁的AllGather和ReduceScatter/Reduce通信。这使得网络对这些特定集体通信操作的效率要求更高。
-
混合专家模型 (MoE): MoE模型引入了专家并行,其中一种常见的策略是将不同的专家网络分布到不同的GPU上。这会导致在模型层之间产生密集的All-to-All通信模式,因为每个Token需要根据路由结果从对应的专家GPU获取计算结果。这种All-to-All通信对网络的全局带宽和拓扑结构提出了更高的要求,与标准LLM的稀疏通信模式形成对比。
-
1.2 LLM推理的网络需求
LLM推理(Inference)旨在根据用户输入(Prompt)生成响应,其网络需求与训练有所不同,更侧重于满足服务等级目标(SLOs),如低延迟和高吞吐量。推理过程通常分为两个阶段:
-
预填充(Prefill)阶段: 处理输入的Prompt,计算初始的Key-Value (KV) Cache。此阶段计算密集,类似于训练的前向传播,对计算能力(FLOPS)和节点间的互连带宽(Interconnect Bandwidth)要求较高,特别是对于长输入序列。
-
解码(Decode)阶段: 自回归地逐个生成输出Token。此阶段通常受限于内存带宽(Memory Bandwidth),因为需要频繁读写KV Cache。对于分布式推理(如使用张量并行),解码阶段对节点间的互连链路延迟(Interconnect Link Latency)非常敏感,因为每次生成Token都需要进行通信(如All-Reduce)。
具体需求包括:
-
低延迟:
-
首Token延迟 (Time-to-First-Token, TTFT): 用户感知到的首次响应时间,主要受Prefill阶段计算时间和网络延迟影响。目标通常在亚秒级(如200-500ms)。
-
Token间延迟 (Inter-Token Latency, ITL / Time-Between-Tokens, TBT / Time Per Output Token, TPOT): 生成后续Token之间的时间间隔,主要受Decode阶段的内存带宽和网络通信延迟影响。目标通常在几十毫秒内(如10-20ms)。
-
-
高吞吐量: 系统在单位时间内能够处理的请求数(Requests per second, RPS)或生成的总Token数(Tokens per second, TPS)。高吞吐量对于降低服务成本、提高系统容量至关重要。批处理(Batching)是提高吞吐量的常用技术。
-
变化的带宽和延迟敏感性: Prefill阶段对互连带宽更敏感,而Decode阶段对互连延迟更敏感。优化推理网络需要同时考虑这两个方面。
-
边缘推理的挑战: 在资源受限的边缘设备上进行分布式推理面临额外的挑战,如设备异构性、无线网络的不稳定性以及更严格的隐私和延迟要求。频繁的All-Reduce操作成为主要通信瓶颈。
1.3 主要挑战
满足LLM分布式计算的网络需求面临诸多挑战:
-
通信瓶颈: 集体通信操作(尤其是All-Reduce和All-to-All)是主要的性能瓶颈,尤其是在规模扩大或网络带宽/延迟受限时。ZeRO等内存优化技术会加剧通信压力。
-
成本与功耗: 构建大规模、高带宽、低延迟的网络(如基于InfiniBand的全对分带宽Clos网络)成本高昂,且功耗巨大。例如,一个连接3万个GPU的400Gbps全对分网络成本可达2亿美元,功耗达兆瓦级。
-
资源利用率: 尽管GPU计算和内存利用率可能很高,但网络资源(带宽)和CPU、主机内存等辅助资源常常被低效利用。例如,在一个LLM集群中,InfiniBand网卡空闲时间可能超过60%。优化资源利用率,避免过度配置,是降低成本的关键。
-
可靠性与故障处理: 在长达数月的训练过程中,硬件故障(包括网络设备和链路故障)难以避免。需要高效的故障检测、诊断和恢复机制(如异步检查点)来减少故障对训练进度的影响。
-
异构性: 边缘设备或跨数据中心训练场景中,网络条件和计算能力可能存在显著差异,需要自适应的通信策略和负载均衡。
-
网络拥塞管理: 在大规模集群中,多对多的通信模式(如All-Reduce, All-to-All)容易引发网络拥塞,导致丢包和延迟增加,进而影响训练/推理性能。需要有效的拥塞控制机制。
-
主流网络技术分析
为了满足LLM分布式计算对高性能通信的需求,业界采用了多种先进的网络技术。本节将分析几种主流技术:InfiniBand (IB)、RDMA over Converged Ethernet (RoCE)以及NVIDIA的NVLink/NVSwitch。
二、相关技术介绍
2.1 RDMA (InfiniBand / RoCE)
核心概念: RDMA 是一种允许网络中的一台计算机直接访问另一台计算机内存的技术,无需 涉及双方操作系统的内核,也 无需 CPU 的介入(数据传输过程)。它旨在通过 低延迟、高吞吐量 和 低 CPU 使用率 来加速网络通信。
工作原理: 传统的网络通信(如 TCP/IP)需要数据在用户空间和内核空间之间多次复制,并由 CPU 负责处理网络协议栈。RDMA 通过网络接口卡(NIC)直接读写应用程序指定的内存区域,绕过了内核和 CPU,极大地减少了数据复制和处理开销。
主要实现:
InfiniBand (IB): 是一种专为高性能计算设计的网络技术,从一开始就内置了 RDMA 支持。它提供非常高的带宽(如 HDR 200Gbps, NDR 400Gbps, XDR 800Gbps+)和极低的延迟(通常在微秒级)。它需要专用的 InfiniBand 交换机和 HCA(Host Channel Adapter,即 IB 网卡)。由于其性能和成熟度,在大型 HPC 和 AI 集群中广泛使用。
RoCE (RDMA over Converged Ethernet): 是一种允许在标准以太网上传输 RDMA 流量的协议。它利用了以太网的广泛部署和成本效益。RoCE 有两个主要版本:
RoCE v1: 工作在以太网链路层(Layer 2),要求网络环境是无损的(Lossless Ethernet),通常需要配置 PFC (Priority Flow Control) 等技术,限制在同一个二层广播域内。
RoCE v2: 工作在 UDP/IP 层(Layer 3),可以跨路由器进行路由,扩展性更好。但同样强烈依赖无损网络配置以获得最佳性能和稳定性。
大模型相关性: 在大规模分布式训练中,模型参数、梯度、激活值等需要在大量计算节点(通常是 GPU 服务器)之间频繁交换。RDMA 提供的低延迟和高带宽对于缩短通信时间、提高整体训练效率至关重要。无论是 InfiniBand 还是 RoCE,都是构建大型 AI 训练集群网络底座的关键技术。
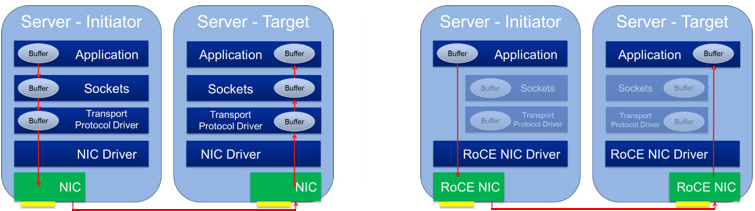
2.2 NVLink / NVSwitch
核心概念: NVLink 是 NVIDIA 开发的一种 GPU 间高速互连 技术,旨在提供比传统 PCIe 总线高得多的带宽和更低的延迟。NVSwitch 是基于 NVLink 技术构建的交换芯片/系统,允许多个 GPU 以全连接(All-to-All)或接近全连接的方式高速通信。
工作原理:
NVLink: 提供点对点的 GPU 直接连接通道。每一代 NVLink 都在提升单通道带宽和通道数量。例如,NVLink 4.0(用于 H100 GPU)可以提供高达 900 GB/s 的双向总带宽。
NVSwitch: 类似于网络交换机,但用于连接 NVLink 端口。它允许多个(例如 8 个、16 个或更多)GPU 组成一个高速互联域。NVSwitch 内部包含大量 NVLink 端口和交叉开关结构,使得任意两个连接到 Switch 的 GPU 之间都能以极高的 NVLink 速度通信,避免了像 PCIe 那样需要通过 CPU 或 PCIe Switch 转发的瓶颈。
大模型相关性:
单节点内扩展: 对于包含多个 GPU 的单个服务器(如 NVIDIA DGX/HGX 系统),NVLink 和 NVSwitch 是实现 模型并行(如张量并行、流水线并行)的关键。这些并行策略需要 GPU 之间频繁、低延迟地交换大量数据(如权重、激活、梯度片段)。NVLink/NVSwitch 的超高带宽(远超 RDMA 的跨节点带宽)使得这种节点内的并行非常高效。
多节点扩展(NVLink Network / NVSwitch Fabric): NVIDIA 也在将 NVSwitch 的能力扩展到节点之间,构建更大规模的 GPU 计算域,进一步模糊节点内外的界限,提供更统一的高速互联。这对于训练参数量极其庞大的模型尤其重要。
| 特性 | InfiniBand (IB) | RDMA over Converged Ethernet (RoCEv2) | NVLink / NVSwitch |
| 主要应用场景 | HPC, AI训练集群 (节点间) | 数据中心, AI集群 (节点间), 存储网络 | GPU节点内/机柜内互连 |
| 核心技术 | 专用协议, 原生RDMA, 信用流控 | RDMA over UDP/IP, 需无损以太网 (PFC/ECN) | 高速串行互连, 交换结构 |
| 典型带宽 | HDR (200G), NDR (400G), XDR (800G) per port | 100G, 200G, 400G, 800G per port | 3.6 - 7.2 Tbps per GPU (聚合) |
| 典型延迟 | 极低 (100-150ns 交换延迟) | 低 (约500ns 交换延迟) | 极低 (节点内) |
| 可扩展性 | 良好 | 非常好 (基于以太网) | 有限 (主要用于节点/机柜内) |
| 成本因素 | 高 (专用硬件, 单一供应商) | 中/低 (利用以太网硬件, 多供应商) | 非常高 (集成在NVIDIA平台) |
| 生态/互操作 | 较封闭 (NVIDIA主导) | 开放 (基于以太网标准) | 封闭 (NVIDIA专有) |
| 管理复杂度 | 较高 (需专门技能) | 中 (需配置无损以太网) | 集成在平台内,相对简单 |
2.3 RDMA-GPU (GPUDirect RDMA / GPUDirect Storage)
核心概念: 这类技术旨在进一步优化 GPU 与其他设备(主要是网络接口卡 NIC 和存储设备)之间的数据传输,允许数据直接在 GPU 内存和这些设备之间移动,而无需先拷贝到 CPU 主内存。
工作原理与实现:
GPUDirect RDMA: 允许支持 RDMA 的 NIC 直接从远程节点的 GPU 内存读取数据,或将数据直接写入远程节点的 GPU 内存,整个过程无需 CPU 主内存作为中转站。这需要 NIC 驱动、GPU 驱动和 RDMA 协议栈的协同支持。它极大地降低了跨节点 GPU 通信的延迟,并进一步减少了 CPU 的负载。
GPUDirect Storage: 允许 GPU 直接访问本地或远程(通过 NVMe-oF 等)的 NVMe SSD 存储设备。当需要从磁盘加载数据(如训练样本、模型检查点)到 GPU 内存,或者将 GPU 内存中的数据(如模型检查点)保存到磁盘时,GDS 可以绕过 CPU 主内存,直接进行数据传输。这显著加速了 I/O 密集型操作。
大模型相关性:
GPUDirect RDMA: 对于大规模分布式训练至关重要。在节点间传输梯度、参数等数据时,直接在 GPU 内存和 NIC 之间传输,避免了 GPU Memory -> CPU Memory -> NIC 的低效路径,显著降低了通信延迟,提高了端到端的训练性能。
GPUDirect Storage: 对于处理海量数据集和巨大模型的场景非常有用。它可以加速训练数据的加载(尤其是在数据集无法完全放入内存时),并大幅缩短保存和加载模型检查点(Checkpointing)的时间。快速 Checkpointing 对于需要长时间运行的大模型训练任务的容错和稳定性至关重要。
2.4 NVMe-oF
核心概念: NVMe (Non-Volatile Memory Express) 是专为 SSD(尤其是基于 PCIe 的 SSD)设计的高性能存储接口协议,旨在充分发挥闪存的低延迟和高并发优势。NVMe-oF 则是将 NVMe 协议扩展到 网络结构 (Fabrics) 上,允许服务器通过网络(如以太网、InfiniBand、Fibre Channel)访问 远程 的 NVMe SSD,并尽可能保持接近本地 NVMe 的性能(低延迟、高 IOPS、高带宽)。
工作原理: NVMe-oF 将 NVMe 命令和数据封装在底层网络传输协议(Transport Binding)中。常见的传输绑定包括:
NVMe over RDMA (InfiniBand or RoCE): 利用 RDMA 的低延迟特性,提供非常接近本地 NVMe 的性能。
NVMe over TCP: 利用广泛部署的 TCP/IP 网络,易于部署,但性能相比 RDMA 会有损耗。
NVMe over Fibre Channel: 在现有的 FC SAN 环境中扩展 NVMe。
大模型相关性:
高性能共享存储: 大模型训练通常需要访问庞大的数据集(TB 甚至 PB 级别)。NVMe-oF 可以构建一个高性能、低延迟的共享存储池,供所有计算节点访问。这比传统的 NAS 或基于 iSCSI 的 SAN 能提供更好的性能,更适合数据密集型的 AI 工作负载。
快速数据加载与 Checkpointing: 结合 GPUDirect Storage,计算节点可以通过 NVMe-oF 网络高速地从远程共享存储池直接加载数据到 GPU 内存,或者将模型检查点高速写入共享存储。这对于提高数据 I/O 效率、缩短训练启动时间和 Checkpointing 时间非常有帮助。
存储与计算解耦: NVMe-oF 使得存储资源可以独立于计算节点进行扩展和管理,提高了资源利用的灵活性和效率。
2.5 NCCL / MPI (集群通信库)
核心概念: 集群通信库是软件层面的接口和实现,它们为运行在分布式系统(集群)中的多个独立进程(通常分布在不同节点上)提供相互通信和同步的机制。它们构建在底层网络硬件(如 InfiniBand, RoCE, Ethernet)和协议(如 RDMA, TCP/IP)之上,为应用程序(如大模型训练框架)提供更易用、更高性能的通信原语。
主要实现:
NCCL (NVIDIA Collective Communications Library):
专注点: 专门为 NVIDIA GPU 优化的高性能 集体通信 (Collective Communication) 库。集体通信是指涉及一组进程(通常是所有参与训练的 GPU)的通信操作。
主要操作: 提供高度优化的 AllReduce, Broadcast, Reduce, AllGather, ReduceScatter 等集体操作实现。这些操作在大规模分布式训练中用于同步梯度、分发模型参数等。
优化: NCCL 深度感知 NVIDIA 硬件特性,能够自动选择最优的通信路径和算法。它能高效利用 NVLink/NVSwitch 进行节点内 GPU 通信,并结合 GPUDirect RDMA 实现跨节点 GPU 间的高速低延迟通信。
大模型相关性: NCCL 是当前进行大规模 GPU 分布式训练(尤其是数据并行、张量并行、流水线并行中涉及的集体通信)的 事实标准。深度学习框架如 PyTorch (DistributedDataParallel, FullyShardedDataParallel) 和 TensorFlow (MirroredStrategy, MultiWorkerMirroredStrategy) 等都深度集成并依赖 NCCL 来实现高效的多 GPU/多节点训练。其性能直接影响训练的扩展效率(Scalability)。
MPI (Message Passing Interface):
专注点: 一个 通用 的、标准化 的并行计算消息传递接口规范,历史悠久,广泛应用于各种 HPC 场景。它不仅支持集体通信,也提供丰富的 点对点通信 (Point-to-Point Communication) 功能(如 Send, Recv)。
通用性: MPI 被设计为可在多种硬件平台(CPU, GPU, 加速器)和网络环境(InfiniBand, Ethernet, 专有网络等)上运行。有多种流行的 MPI 实现(如 Open MPI, MPICH, Intel MPI)。
功能: 除了基本的 Send/Recv 和集体操作,MPI 还提供进程管理、拓扑感知、并行 I/O 等高级功能。
大模型相关性: 虽然 NCCL 在 GPU 集体通信方面通常性能更优,但 MPI 仍然在大模型相关的场景中扮演角色:
任务编排: 可以用于启动、管理和协调整个分布式训练任务中的不同进程。
CPU/异构计算: 如果训练流程中包含大量的 CPU 计算或者需要在 CPU 与 GPU 之间进行复杂的数据交互,MPI 可以提供通信支持。
非 NCCL 优化场景: 在某些特定的通信模式或非 NVIDIA 硬件环境中,MPI 可能是主要的通信库。
研究与原型: 有些研究项目或框架可能基于 MPI 构建其并行逻辑。
关系: 有时 MPI 和 NCCL 会一起使用,例如使用 MPI 进行任务管理和某些控制流通信,而将计算密集型的 GPU 集体通信交给 NCCL 处理。
2.6 关键性能指标评估
关键性能指标评估 (Key Performance Indicators - KPIs)
在评估用于大模型的高性能网络和通信系统时,主要关注以下几类指标:
a) 带宽 (Bandwidth):
定义: 单位时间内可以传输的数据量,通常以 Gbps (Gigabits per second) 或 GB/s (Gigabytes per second) 表示。
重要性: 对于传输大块数据(如模型参数、梯度、数据集分片)至关重要。更高的带宽意味着更短的数据传输时间。
类型:
点对点带宽 (Point-to-Point Bandwidth): 两个特定节点之间的最大传输速率。
聚合带宽 (Aggregate Bandwidth): 系统中所有节点同时通信时能达到的总带宽。
剖分带宽 (Bisection Bandwidth): (如前述拓扑部分) 网络对半分割后,两半之间可用的总带宽,衡量全局通信能力的关键指标。
有效带宽 (Effective Bandwidth): 在特定通信模式(如 AllReduce)下,应用程序实际感受到的带宽,通常会低于理论峰值带宽,受算法、协议开销、拓扑等影响。
b) 延迟 (Latency):
定义: 消息从发送端开始发送到接收端开始接收所需的时间,通常测量单向延迟或更常用的往返时间 (Round-Trip Time, RTT),并用微秒 (µs) 表示。
重要性: 对需要频繁同步或传输小消息的操作(如分布式锁、某些控制信令、小批量梯度的同步)影响显著。低延迟可以减少等待时间,提高计算资源的利用率。
类型:
点对点延迟 (Point-to-Point Latency): 两个特定节点间的最短通信延迟。
集体操作延迟 (Collective Latency): 完成一次集体通信(如 AllReduce)所需的总时间。
c) 消息速率 (Message Rate):
定义: 单位时间内可以处理(发送和接收)的消息数量,通常以 MPPS (Millions of Packets Per Second) 或 MOPS (Millions of Operations Per Second) 表示。
重要性: 对于涉及大量小消息的通信模式很重要。
d) CPU/GPU 利用率 (CPU/GPU Utilization):
定义: 在进行网络通信时,CPU 或 GPU 被占用的程度。
重要性: RDMA、GPUDirect 等技术的主要优势之一就是降低 CPU 开销。低 CPU/GPU 通信开销意味着计算核心可以更专注于实际的计算任务。高通信开销可能成为瓶颈。
e) 计算通信重叠度 (Computation-Communication Overlap):
定义: 在执行计算任务的同时进行网络通信的能力和程度。
重要性: 高效的重叠可以隐藏通信延迟,提高整体吞吐量。这需要硬件(如独立的传输引擎)、软件(异步操作支持)和算法(流水线设计)的协同。
f) 应用级吞吐量 (Application-Level Throughput):
定义: 最终用户关心的性能指标,如大模型训练中的吞吐量(Tokens/second, Samples/second, Steps/second)或总训练时间 (Time-to-Train)。
重要性: 这是衡量整个系统(计算、通信、存储、软件栈)综合性能的最终标准。网络性能的提升最终要体现在应用性能的改善上。
g) 扩展效率 (Scaling Efficiency):
定义: 当增加计算资源(如 GPU 数量)时,性能提升的比例。理想情况下是线性扩展。
重要性: 衡量系统并行处理能力和网络支撑能力的关键。低扩展效率通常意味着通信瓶颈随着规模增大而日益严重。
类型: 强扩展 (Strong Scaling) 和弱扩展 (Weak Scaling)。
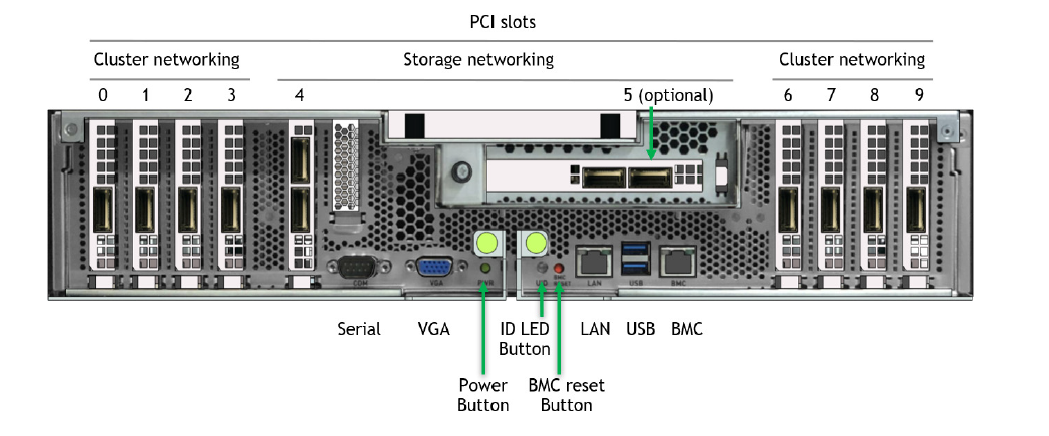
补充 1 A100 主板实物图


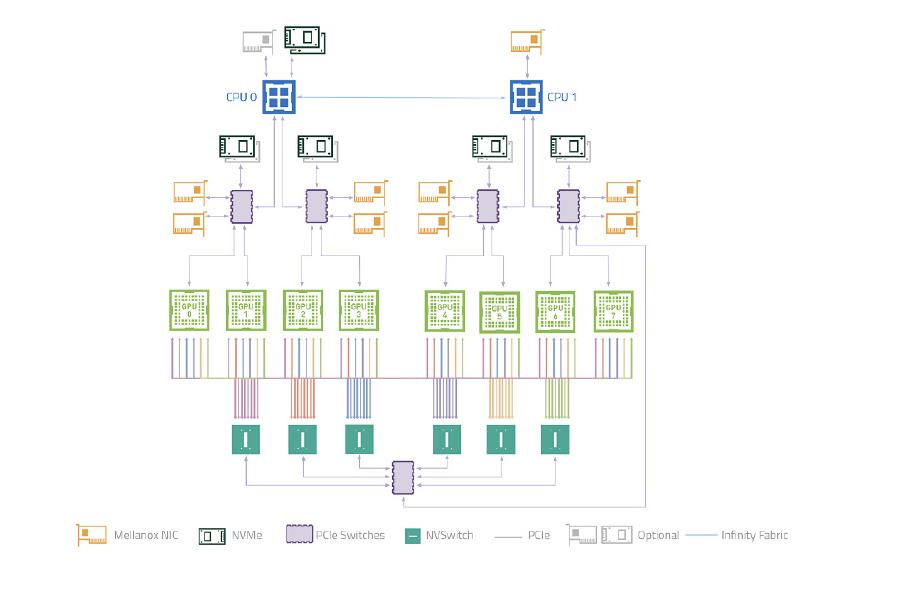
补充 2 A100 硬件拓扑图
三、相关的技术栈测试调试
3.1 服务器申请
RDMA (RoCE)和NVMe-oF 申请带 RDMA 的 ECS服务器
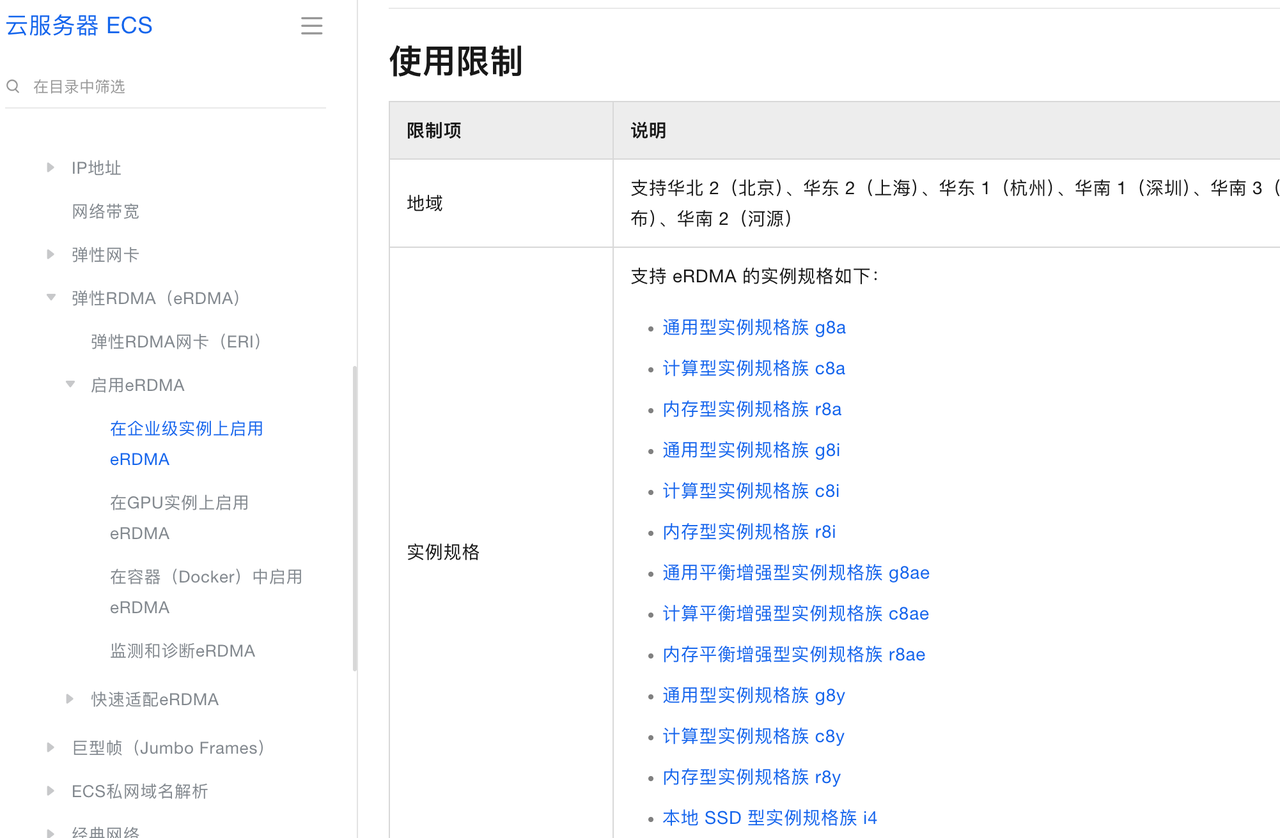
NCCL 只要带 GPU 显卡基本都可以 我采用 A10 显卡
如果有的选当然选择最新的 GPU 服务器,啥都支持。
请ECS 服务器参考:
3.2 RDMA(RoCE) 调试示例
sudo apt-get update -y
sudo apt-get install -y rdma-core# 安装 rdma-core 工具包
sudo apt update
sudo apt install -y rdma-core
sudo apt install ibverbs-utils
apt install infiniband-diags -y
# 列出 RDMA 设备
ibv_devinfo
# 查看设备状态
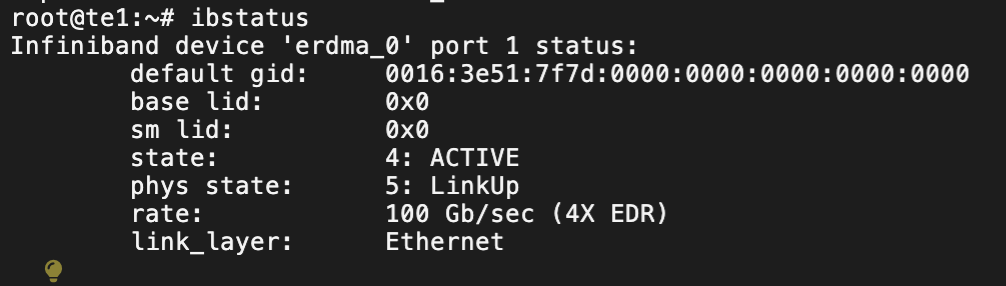
ibv_devices # 列出设备
ibstatus # 查看所有 RDMA 端口状态
# 查看网络接口 IP 地址 (找到与 RDMA 设备关联的那个)
ip addr show
eadm ver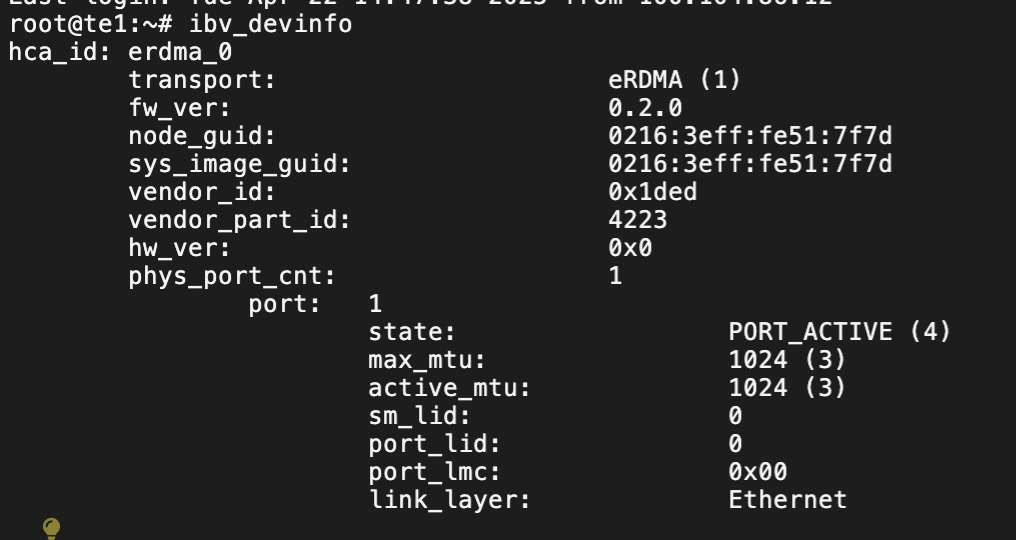

a) 基本连通性和延迟测试
## te1 作为 服务器端
rping -s -a te1 -v## te2 作为 客户端
rping -c -a te1 -C 10 -v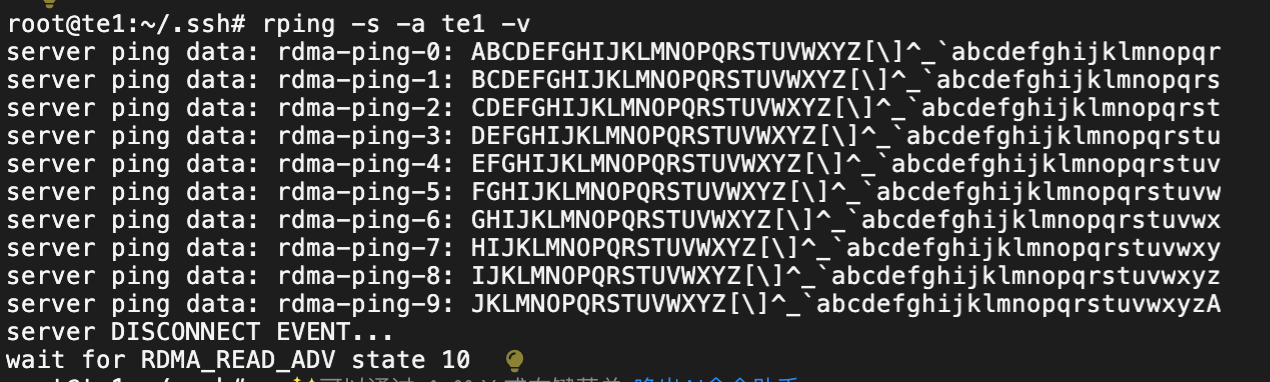

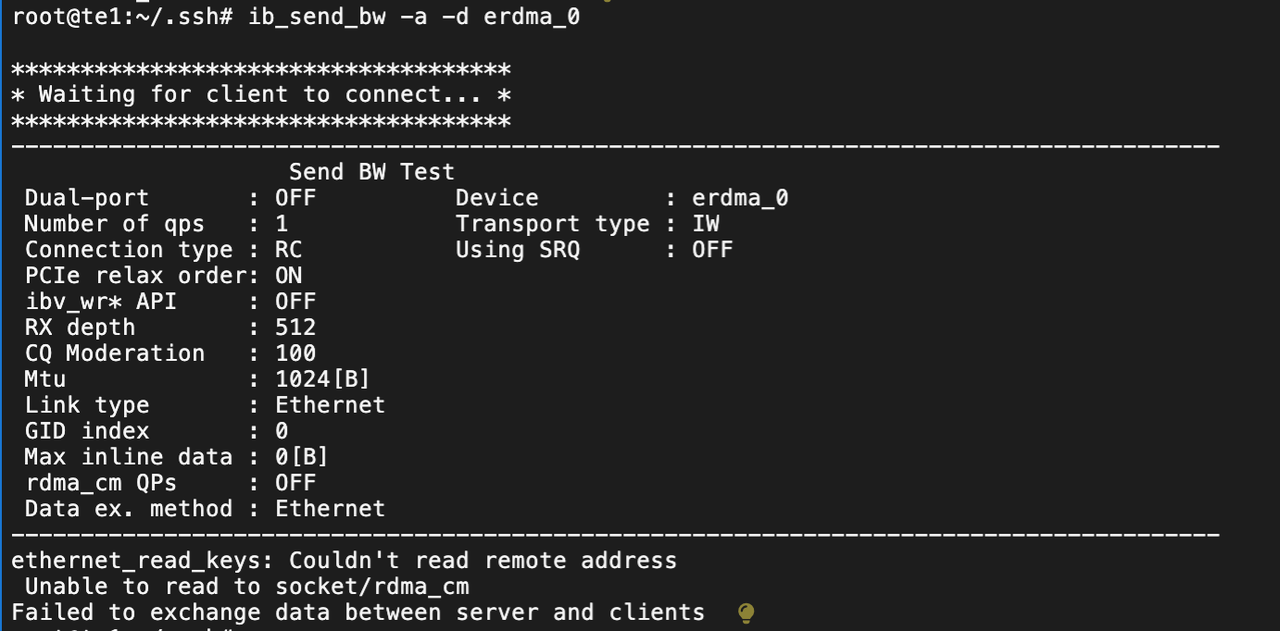
b) 带宽测试
# 安装 perftest 包
sudo apt install -y perftest
# 在服务器 te1 启动服务端
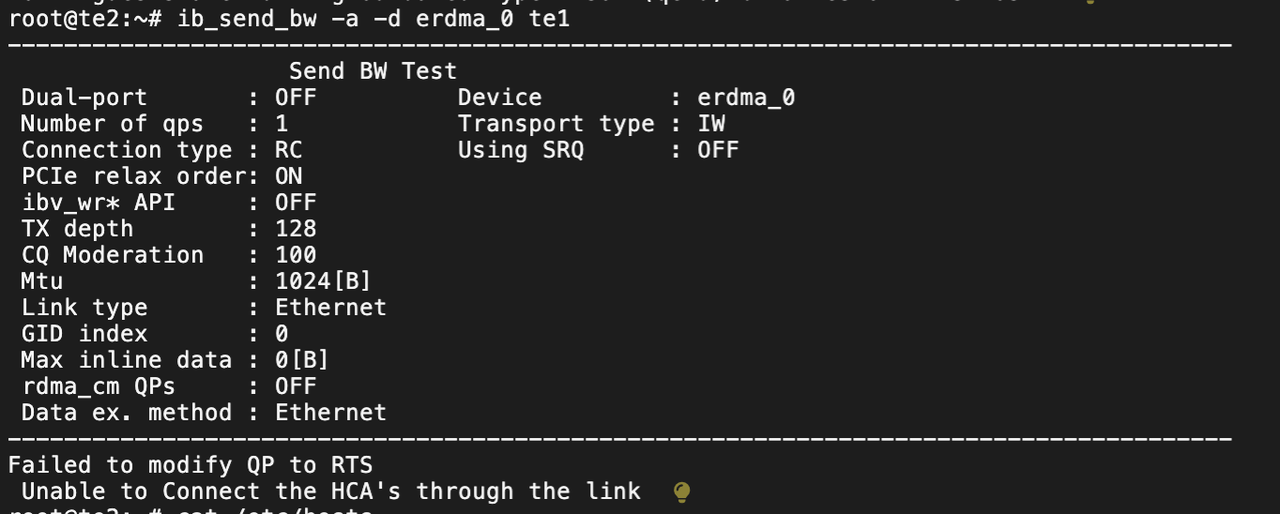
ib_send_bw -a -d erdma_0
# 在服务器 te2 启动客户端连接服务器 te1
ib_send_bw -a -d erdma_0 te1
这里ib_send_bw 测试失败了。不知道阿里云 ECS 有什么限制。先记录,等后续解决了再补充
3.3 NVMe-oF 示例
3.4 NCCL 示例
3.5 MPI 示例
3.6 GPU Direct RDMA 示例
搞不到设备,等有设备了补上
nvidia-smi topo -m 还是用perftest测试先留坑有设备有补实验结果
还是用perftest测试先留坑有设备有补实验结果
# 服务器端 (GPU 0 -> 网络)
perftest -d <rdma_device> --use_cuda=0
# 客户端 (网络 -> GPU 0)
perftest <server_ip> -d <rdma_device> --use_cuda=03.7 GPU Direct Storage 示例
搞不到设备,等有设备了补上
lsblk
nvme list
lspci | grep -i nvme
# 检查 GDS 相关内核模块是否加载
lsmod | grep nvfs
lsmod | grep nvidia_fs小结:
主要是对当前大模型训练和推理场景下,硬件网络,存储,内存,显卡的优化技术做了一个盘点综述。这个体系太庞大了,目前只是粗浅的大致归类总结了一下。
参考:
RDMA 架构与实践 | HouminRDMA,即 Remote Direct Memory Access,是一种绕过远程主机 OS kernel 访问其内存中数据的技术,概念源自于 DMA 技术。在 DMA 技术中,外部设备(PCIe 设备)能够绕过 CPU 直接访问 host memory;而 RDMA 则是指外部设备能够绕过 CPU,不仅可以访问本地主机的内存,还能够访问另一台主机上的用户态内存。由于不经过操作系统,不仅节省了大![]() https://houmin.cc/posts/454a90d3/Accelerated InfiniBand Solutions for HPC | NVIDIANVIDIA InfiniBand brings high-speed, low-latency, scalable solutions to supercomputers, AI and cloud data centers.
https://houmin.cc/posts/454a90d3/Accelerated InfiniBand Solutions for HPC | NVIDIANVIDIA InfiniBand brings high-speed, low-latency, scalable solutions to supercomputers, AI and cloud data centers.![]() https://www.nvidia.com/en-us/networking/products/infiniband/https://zhuanlan.zhihu.com/p/394352476
https://www.nvidia.com/en-us/networking/products/infiniband/https://zhuanlan.zhihu.com/p/394352476![]() https://zhuanlan.zhihu.com/p/394352476Introduction to NVIDIA DGX B200 Systems — NVIDIA DGX B200 User Guide
https://zhuanlan.zhihu.com/p/394352476Introduction to NVIDIA DGX B200 Systems — NVIDIA DGX B200 User Guide![]() https://docs.nvidia.com/dgx/dgxb200-user-guide/introduction-to-dgxb200.htmlIntroduction to NVIDIA DGX H100/H200 Systems — NVIDIA DGX H100/H200 User Guide
https://docs.nvidia.com/dgx/dgxb200-user-guide/introduction-to-dgxb200.htmlIntroduction to NVIDIA DGX H100/H200 Systems — NVIDIA DGX H100/H200 User Guide![]() https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.htmlDGX A100 System User Guide — NVIDIA DGX A100 User GuideDGX A100 User Guide
https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.htmlDGX A100 System User Guide — NVIDIA DGX A100 User GuideDGX A100 User Guide![]() https://docs.nvidia.com/dgx/dgxa100-user-guide/NVIDIA DGX Systems - NVIDIA DocsSystem documentation for the DGX AI supercomputers that deliver world-class performance for large generative AI and mainstream AI workloads.
https://docs.nvidia.com/dgx/dgxa100-user-guide/NVIDIA DGX Systems - NVIDIA DocsSystem documentation for the DGX AI supercomputers that deliver world-class performance for large generative AI and mainstream AI workloads.![]() https://docs.nvidia.com/dgx-systems/在GPU实例上启用eRDMA实现高效数据传输_云服务器 ECS(ECS)-阿里云帮助中心GPU实例绑定弹性RDMA网卡(ERI)后,各GPU实例间在VPC网络下可以实现RDMA直通加速互连,相比传统的RDMA,eRDMA可以提供更高效的数据传输服务,有效提升GPU实例之间的通信效率并缩短任务处理时间。本文介绍如何在GPU实例上启用eRDMA。
https://docs.nvidia.com/dgx-systems/在GPU实例上启用eRDMA实现高效数据传输_云服务器 ECS(ECS)-阿里云帮助中心GPU实例绑定弹性RDMA网卡(ERI)后,各GPU实例间在VPC网络下可以实现RDMA直通加速互连,相比传统的RDMA,eRDMA可以提供更高效的数据传输服务,有效提升GPU实例之间的通信效率并缩短任务处理时间。本文介绍如何在GPU实例上启用eRDMA。![]() https://help.aliyun.com/zh/ecs/user-guide/on-the-gpu-instance-configuration-erdma?spm=a2c4g.11186623.0.0.351c5bc7Y2XSbn#565f747ef7898在企业级ECS实例上使用eRDMA提升网络性能_云服务器 ECS(ECS)-阿里云帮助中心部分企业级ECS实例支持配置eRDMA,可以实现在不需要修改现有网络架构的情况下,体验超低延迟、大吞吐、高弹性的高性能RDMA网络服务。
https://help.aliyun.com/zh/ecs/user-guide/on-the-gpu-instance-configuration-erdma?spm=a2c4g.11186623.0.0.351c5bc7Y2XSbn#565f747ef7898在企业级ECS实例上使用eRDMA提升网络性能_云服务器 ECS(ECS)-阿里云帮助中心部分企业级ECS实例支持配置eRDMA,可以实现在不需要修改现有网络架构的情况下,体验超低延迟、大吞吐、高弹性的高性能RDMA网络服务。![]() https://help.aliyun.com/zh/ecs/user-guide/configure-erdma-on-a-cpu-instance?spm=a2c4g.11186623.0.0.17375bc7uvr9U6#26c9e9c4f6nhk
https://help.aliyun.com/zh/ecs/user-guide/configure-erdma-on-a-cpu-instance?spm=a2c4g.11186623.0.0.17375bc7uvr9U6#26c9e9c4f6nhk


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









