







交叉验证是一种评估泛化性能的统计学方法,它比单次划分训练集和测试集的方法更稳定、前面。在交叉验证中,数据被多次划分,并且需要训练多个模型。最常用的交叉验证是k折交叉验证,其中k是由用户指定的数字,通常取5或10,。在执行5折交叉验证时,首先将数据划分为大致相等的5部分,每一部分叫做折。接下来训练一系列模型。使用第1折作为测试集,其他折作为训练集来训练第一个模型。利用2~5折中的数据来构建模型,然后在1折上评估精度。之后构建另一个模型,这次使用2折作为测试集,1、3、4、5折中的数据作为训练集。利用3、4、5作为测试集继续重复这一过程。
对于将数据划分为训练集和测试集的这5次划分,每一次都要计算精度。
最后我们得到了5个精度值,整个过程如图所示:
import mglearn
import matplotlib.pyplot as plt
mglearn.plots.plot_cross_validation()
plt.show()
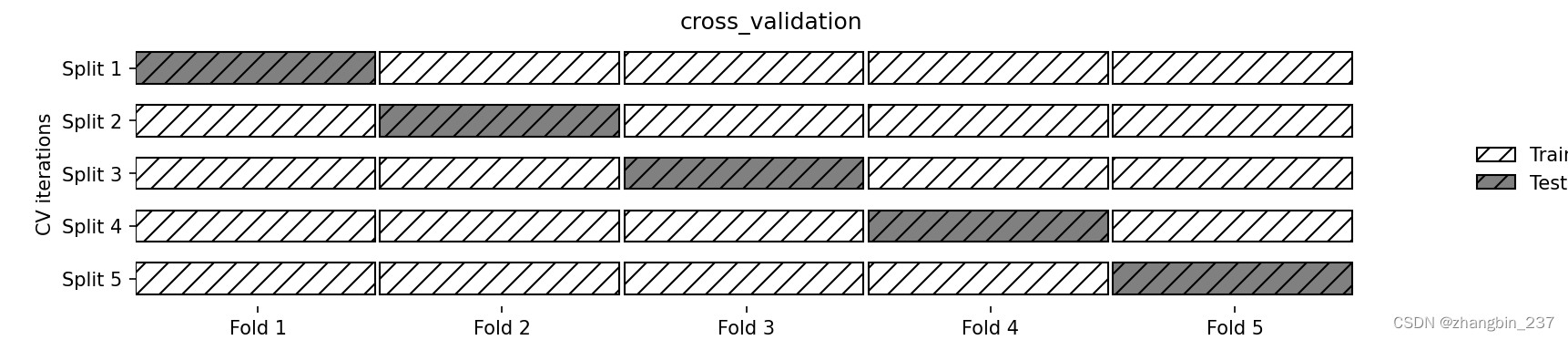
通常来说,数据的前五分之一是第一折,第二个五分之一是第二折,以此类推。
scikit-learn是利用model_selection模块中的cross_val_score函数来实现交叉验证的。
cross_val_score函数的参数是我们想要评估的模型、训练数据与真实标签。
我们在iris数据集上对LogisticRegression进行评估:
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris=load_iris()
logreg=LogisticRegression()
scores=cross_val_score(logreg,iris.data,iris.target,cv=5)
print('交叉验证精度:{}'.format(scores))

cv参数是用来设置折数的。
总结交叉验证精度的一种常用方法是计算平均值:
print('交叉验证精度平均数:{:.2f}'.format(scores.mean()))

我们可以从交叉验证平均值中得出结论,我们预计模型的平均精度约为96%。观察5折交叉验证得到的所有5个精度值,还可以发现,折与折之间的精度有较大的变化,范围从93%-100%。
这可能意味着模型强烈依赖于将某个折用于训练,但也可能只是因为数据集的数据里太小。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









