







我们尝试了许多不同的参数,并选择了在测试集上精度最高的那个,但这个精度不一定能推广到新数据上。
由于我们使用测试数据进行了调参,所以不能再用它来评估模型的好坏。我们最开始需要将数据划分为测试集和训练集也是这个原因,我们需要一个独立的数据集来进行评估,一个在创建模型时没有用到的数据集。
为了解决这个问题,有一种方法是再次划分数据集,这样我们就得到了3个数据集:用于构建模型的数据集、用于选择模型参数的验证集(开发集)、用于评估所选参数性能的测试集。
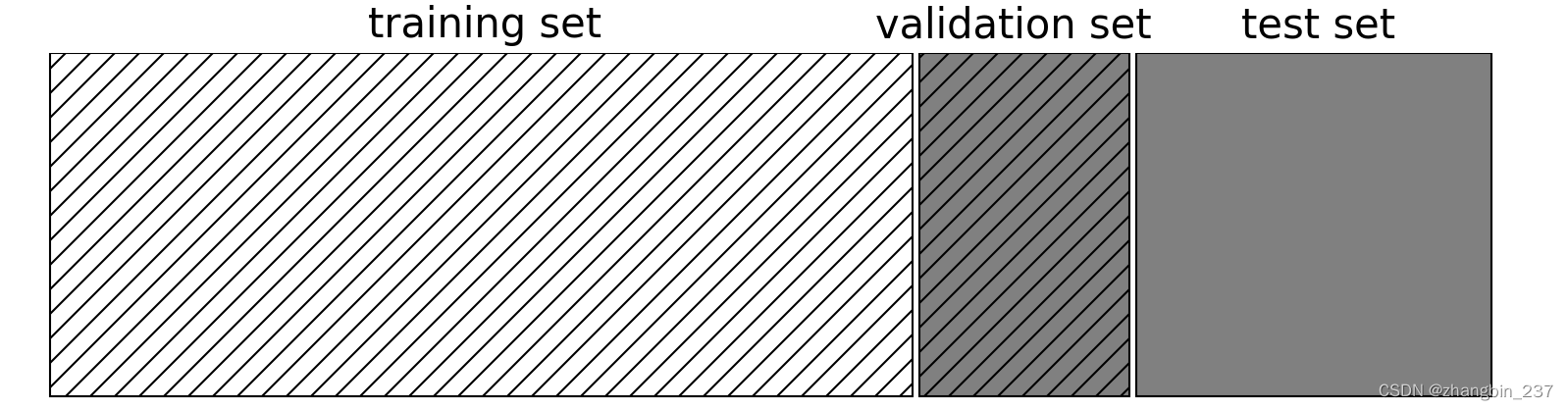
利用验证集选定最佳参数之后,我们可以利用找到的参数设置重新构建一个模型,但是要同时在训练数据和验证数据上进行训练。我们可以利用尽可能多的数据来构建模型。实现如下:
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris=load_iris()
X_trainval,X_test,y_trainval,y_test=train_test_split(iris.data,iris.target,random_state=0)
X_train,X_valid,y_train,y_valid=train_test_split(X_trainval,y_trainval,random_state=1)
print('训练集大小:{} 开发集大小:{} 测试集大小:{}'.format(X_train.shape[0],X_valid.shape[0],X_test.shape[0]))
best_score=0
for gamma in [0.001,0.01,0.1,1,10,100]:
for C in [0.001,0.01,0.1,1,10,100]:
#对每种参数组合都训练一个SVC
svm=SVC(gamma=gamma,C=C)
svm.fit(X_train,y_train)
score=svm.score(X_valid,y_valid)
if score>best_score:
best_score=score
best_parameters={'C':C,'gamma':gamma}
svm=SVC(**best_parameters)
svm.fit(X_trainval,y_trainval)
test_score=svm.score(X_test,y_test)
print('最高精度:{:.2f}'.format(best_score))
print('最好参数组合:{}'.format(best_parameters))
print('测试集在最好模型的参数:{:.2f}'.format(test_score))

可以看到,验证集上的最高分数是96%,这比之前略低,可能是因为我们使用了更少的数据来训练模型。但在测试集上的分数更低(92%),因此我们只能声称对92%的新数据正确分类。
训练集、验证集、测试集之间的区别对于在实践中应用机器学习方法至关重要。任何根据测试集精度所做的选择都会将测试集的信息“泄露”到模型中。因此,保留一个单独的测试集是很重要的,它仅用于最终评估。
好的做法是利用训练集和验证集的组合完成所有的探索性分析与模型选择,并保留测试集用于最终评估——即使对于探索性可视化也是如此。严格来说,在测试集上对不止一个模型进行评估并选择更好的那个,将会导致对模型精度过于乐观的分析。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









