







理论:
(一)参考大神视频:
(二)个人总结:
为什么要用BN(Batch Normalization ):
对图像进行标准化处理,使整个训练样本集所对应feature map的数据满足某一分布规律,加速网络收敛。
对于Conv1来说,输入的imageX就是满足某一分布的特征矩阵,但对于Conv2来说,输入的feature map不一定满足某一分布规律,BN就是为了使所有feature map都满足某一分布规律。
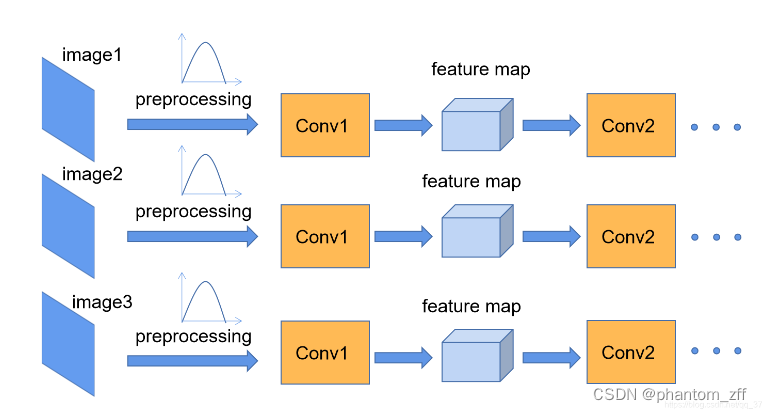
什么分布规律:
feature map满足均值为0,方差为1的分布规律
计算公式:
假设输入的x是RGB三通道的彩色图像,channel=3,那么d=3,x=(x(1),x(2),x(3)),其中x(1):R通道所对应的特征矩阵,x(2):G通道所对应的特征矩阵,x(3):B通道所对应的特征矩阵。

要计算出整个训练集的feature map然后再进行标准化处理,对于一个大型的数据集是不可能的,所以计算每一个Batch数据的feature map后,再进行标准化。
μ向量:feature map每个维度(channel)的均值,其每一个元素代表一个维度(channel)的均值;
σ向量:feature map每个维度(channel)的方差,其每一个元素代表一个维度(channel)的方差;
γ:用来调整数值分布的方差大小,默认值是1,在反向传播过程中学习得到;
β:用来调节数值均值的位置,默认值是0,在反向传播过程中学习得到;
ϵ:一个很小的常量,防止分母为零;

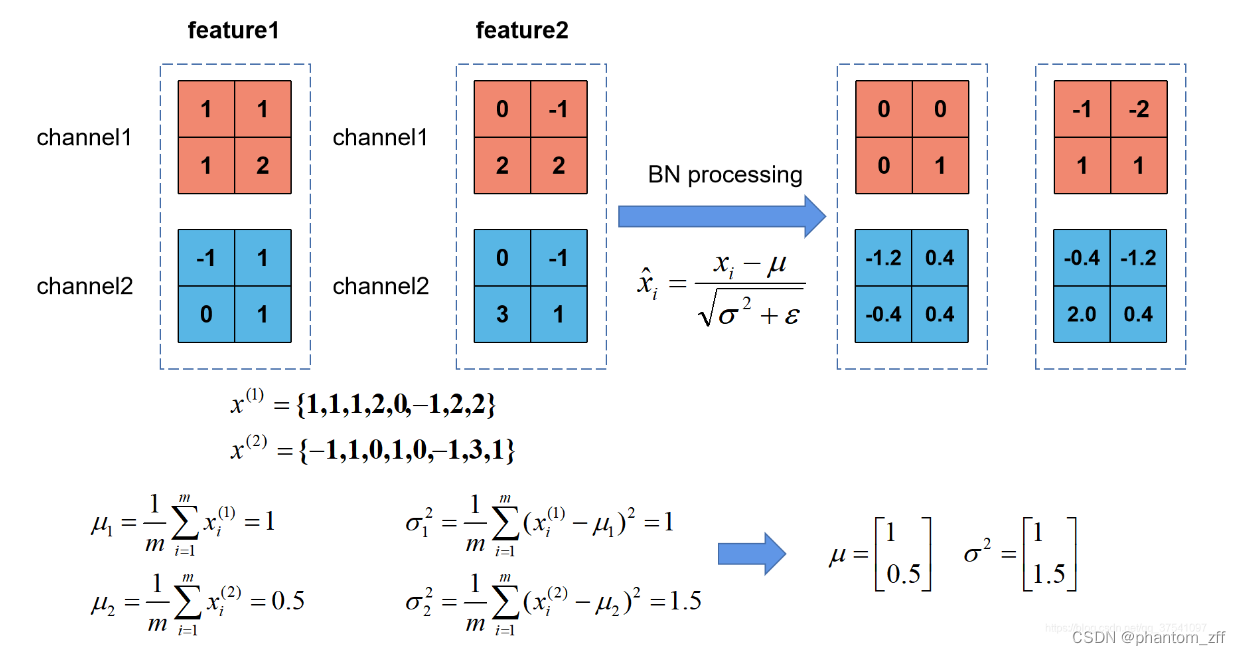
如图:Batch Size为2(一批次送入2张图片),
feature1:image1经过卷积池化得到的特征矩阵;
feature2:image2经过卷积池化得到的特征矩阵;
假设feature的channel是2,
x(1):表示该batch所有feature的channel1的数据,(feature1.channel1, (feature2.channel1);
x(2):表示该batch所有feature的channel2的数据,(feature1.channel2, (feature2.channel2);
对照公式简单算一个:
μ1:[(1-1)2+(1-1)2+(1-1)2+(2-1)2+(0-1)2+(-1-1)2+(2-1)2+(2-1)2]/8=8/8=1
get到意思就行了,剩下不算了嗷~
【大佬原话】在训练网络的过程中,我们是通过一个batch一个batch的数据进行训练的,但是我们在预测过程中通常都是输入一张图片进行预测,此时batch size为1,如果在通过上述方法计算均值和方差就没有意义了。所以我们在训练过程中要去不断的计算每个batch的均值和方差,并使用移动平均(moving average)的方法记录统计的均值和方差,在训练完后我们可以近似认为所统计的均值和方差就等于整个训练集的均值和方差。然后在我们验证以及预测过程中,就使用统计得到的均值和方差进行标准化处理。
这里“使用移动平均(moving average)的方法记录统计的均值和方差”不是很理解。。。应该不要紧吧?加个断点,慢慢理解。
代码:
(一)非函数部分
import numpy as np
import torch
import torch.nn as nn
# [batch, channel, height, width]
feature1 = torch.randn(2, 2, 2, 2)
# 默认:均值为0 方差为1
calculate_mean = [0.0, 0.0]
calculate_var = [1.0, 1.0]
batch_normalization(feature1.numpy().copy(), calculate_mean, calculate_var)
bn = nn.BatchNorm2d(2, eps=1e-5)
output = bn(feature1)
print(output)
1、torch.rand() 和 torch.randn()
torch.rand()返回一个在 [0-1)区间 内服从均匀分布的张量
torch.randn()返回一个服从标准正态分布的张量
torch.randn(2,2,2,2)和[batch, channel, height, width]怎么对应?请看下图:

2、为什么用copy()深拷贝?
确保在处理特征张量时不会修改原始的张量值。
如果直接将 feature1.numpy() 作为参数传递给 bn_process 函数,那么 feature1.numpy() 返回的是原始张量的视图,而不是副本。这意味着在 bn_process 函数中对特征张量的修改会直接影响到原始的张量值,为了避免这种情况,使用 copy() 方法进行深拷贝,以确保在 bn_process 函数中对特征张量的修改不会影响到原始张量的值。
(二)函数部分
根据公式计算bn
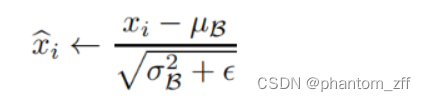
def batch_normalization(feature, mean, var):
feature_shape = feature.shape
for i in range(feature_shape[1]): # feature_shape[1]=2,range(2):0、1
feature_t = feature[:, i, :, :] # i是channel
# print(feature_t)
mean_t = feature_t.mean()
# 总体标准差
std_t1 = feature_t.std()
# 样本标准差
std_t2 = feature_t.std(ddof=1)
# normalize
# np.sqrt():计算数组各元素的平方根
(feature[:, i, :, :] - mean_t) / np.sqrt(std_t1 ** 2 + 1e-5) # 1e-5 是 1 * 10^(-5)
mean[i] = mean[i]*0.9 + mean_t*0.1
var[i] = var[i]*0.9 + (std_t2**2)*0.1
print(feature)
在训练过程中,均值μ和方差σ2是通过计算当前批次数据得到的,记为μnow和σ2now,
此时,pytorch中对当前批次feature进行bn处理时,所使用的σ2now是总体标准差,在代码中是std_t1;
而验证和预测过程中,使用的均值μ和方差σ2是统计量,需要更新,更新策略为:
μstatistic+1 = (1-momentum) * μstatistic + momentum * μnow
σ2statistic+1 = (1-momentum) * σ2statistic + momentum * σ2now
其中,momentum默认取0.1,
在更新统计量σ2statistic时用的σ2now是样本标准差,在代码中是std_t2
(三)结论
差不多

















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









