







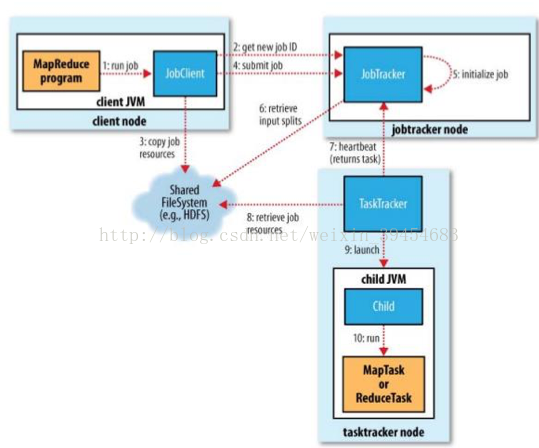
一、MapReduce实现架构(Hadoop 1.0)
两个重要的进程:JobTracker和TaskTracker
JobTracker是主进程,负责接收客户作业提交,调度任务到作节点上运行,并提供诸如监控工作节点状态及任务进度等 管理功能,一个MapReduce集群有一个jobtracker,一般运行在可靠的硬件上。
TaskTracker由JobTracker指派任务,实例化用户程序,在本地执行任务并周期性地向JobTracker汇报状态。在每一个工作节点上永远只会有一个TaskTracker。TaskTracker是通过周期性(默认3s)的心跳来通知jobtracker其当前的健康状态,每一次心跳包含了可用的map和reduce任务数目、占用的数目以及运行中的任务详细信息。Jobtracker利用一个线程池来同时处理心跳和客户请求。
二、MapReduce执行流程
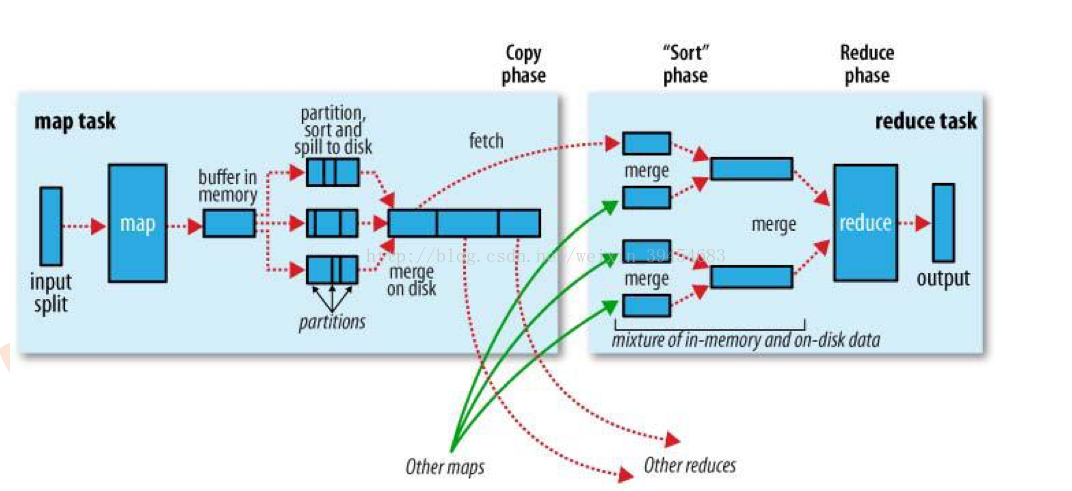
map阶段:
数据来源于HDFS,分片(input split)后输入到不同的map。map处理完数据后不会直接写到磁盘上,而是先写到内存(buffer in memory)。内存大小默认为100M。随着map处理的数据越来越多,内存中的数据就会增大,一旦超过一个阀值(80%,即80M),数据会从内存中落地到磁盘上(即溢写,spill)。但是数据并不是随意写的,要符合一定规则。首先,根据key进行partition,将不同数据分配到不同的分区,默认的方法是:先对key取哈希值,然后对reduce的个数取模。接下来在每个分区中先按照key排序(sort),默认快排,第一关键字是分区号,第二关键字是key。排序后才溢写到磁盘上。最后对磁盘上的各个小文件进行合并(merge)。
问题:为什么不直接写成一个大文件?
答:因为数据是从内存中溢写的,内存有80M的限制,因此只能先写成小文件,后合并。
reduce阶段:
上面所说的仅仅是众多map中的一个。不同map的输出文件中有可能包括同一个partition的数据,那么这些数据将会进入同一个reduce(对应图中绿色的箭头)。比如,一个map的输出文件中有partition 0、1、2的数据,另一个map的输出中包括partition 0、1、2的数据,那么同是partition 0的进入到一个reduce,同是partition 1的进入到一个reduce,同是partition 2的进入一个相同的reduce。
由于这些数据来源于不同的map,所以先要对这些文件进行merge,才能输入到reduce中。
几点说明:
1.关于分片:每个文件切分成多个一定大小(Hadoop1.0默认64M,2.0默认128M,以下用64M)的Block
2.Block要通过InputFormat类的处理。其功能包括:数据分割(Data Split)、记录读取器(Record Reader)。所谓数据分割,是将Block中的数据分割为一条条的记录,比如按照“\n”区分不同记录。比如说有如下数据:I am a student.\nI am a student.\nI am a student.\n。理想状态是每一句话I am a student.\n都处在不同的Block(这里假设这句话能占64M),正好三句话三个Block。但是实际情况可能是I am a student.\nI a在才占满64M,或者I am a stude就占了64M,这样的数据就毫无意义了。为了保证切出一句完整的句子,应该切成比64M稍大或稍小的记录,这就是Record。实际上每个split包含后一个Block中开头部分的数据(解决记录跨Block问题)。Record是逻辑上的概念,而Block是物理上的。Record Reader每读取一条记录,就会调用一次map,也即map的个数就是Record的个数。
3.map阶段的时间主要损耗在IO上(数据落地)。
4.Shuffle是神奇发生的地方,涉及Partition, Sort, Spill, Merge, Combiner, Copy, Memery, Disk...... 其中Combiner是一种数据合并,若具有相同的key,其value值合并,减少输出传输量实际上是reducer函数,当combiner不影响最终结果时,可极大提升性能。但并不是所有情况都能够使用combiner。仅当reducer的计算逻辑满足交换律和结合律的时候才能使用,比如求和、求最值。而求平均数不满足结合律:比如有9个数,求平均数时应将这9个数相加再除以9,而不能将第1、2、3个数先求平均数a,将第4、5、6个数求平均数b,将第7、8、9个数求平均数c,再去求a、b、c的平均数。所以当性能允许时,尽量不使用combiner为好。
5.reduce个数可自行设置。但若设置得太少,会造成程序执行缓慢,设置得太多,会造成shuffle开销大、输出大量小文件。那么设置多少Reduce合适呢?我在Hadoop 1.2.1的官方文档中找到以下内容:
原文:
The right number of reduces seems to be 0.95 or 1.75 multiplied by (<no. of nodes> * mapred.tasktracker.reduce.tasks.maximum).
With 0.95 all of the reduces can launch immediately and start transfering map outputs as the maps finish. With 1.75 the faster nodes will finish their first round of reduces and launch a second wave of reduces doing a much better job of load balancing.
With 0.95 all of the reduces can launch immediately and start transfering map outputs as the maps finish. With 1.75 the faster nodes will finish their first round of reduces and launch a second wave of reduces doing a much better job of load balancing.
我翻译了一下:
Reduce的个数应设置为“节点数* 参数mapred.tasktracker.reduce.tasks.maximum”的0.95倍或1.75倍。当设为0.95倍时,所有reduce任务能立即开始读取map的输出;当设置为1.75倍时,运行更快的节点在运行完第一轮reduce后会开始第二波,对负载均衡有好处。















 3512
3512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









