







经过两天的摸索,终于写出了一个小小小爬虫。这其中的波折是这样的,听我娓娓道来。
我的电脑是没有配置python环境的,所以首先要上官网
下载python的环境文件。
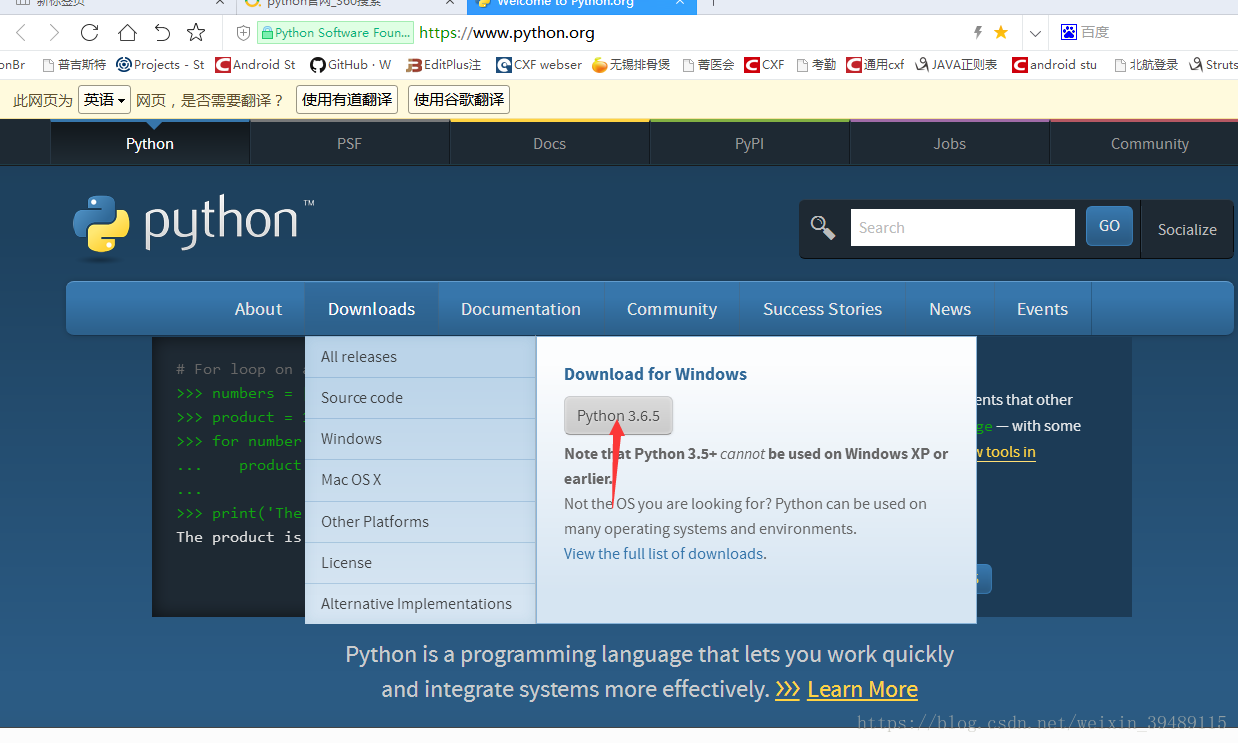
点击点头指向的按钮,下载到桌面,它是一个这样的文件“python-3.6.5.exe”,下载成功后直接点击安装
,安装成功后,那接下来就是
配置环境变量啦。
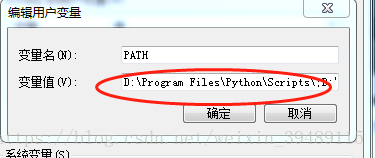
用“;”分号隔开,点击确认。
接下来就测试一下python是否安装成功,如图:
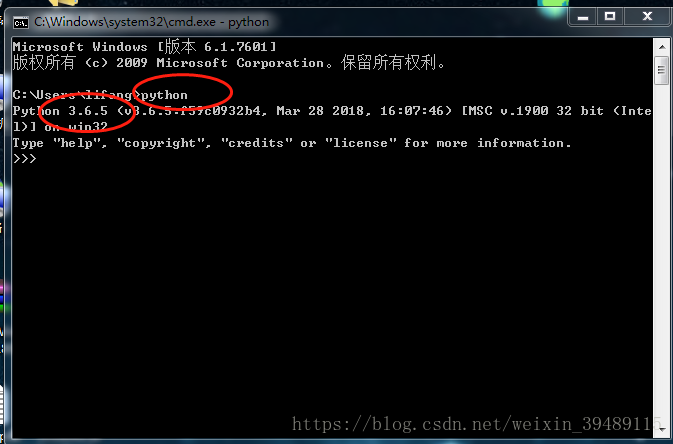
哈哈,没错这就是装成功了!
终于终于可以写代码,激动~~~但似乎我高兴的太早了,因为我的电脑IntelliJ IDEA版本太老了,导入python插件有点问题。详情如下:
我怀着极好的心情要给本机IDEA配置python.先上website 找到了配置python插件的步骤,
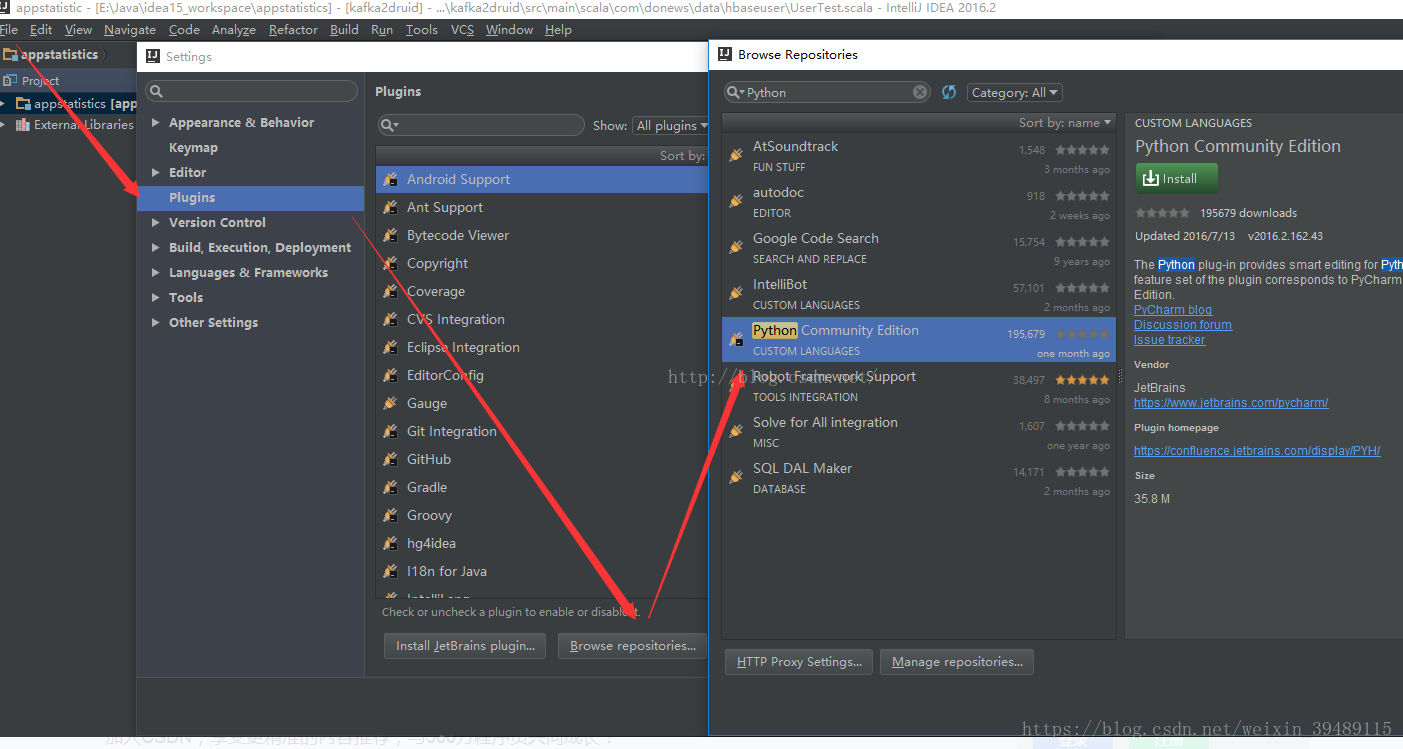
嘻嘻~那我也跟着尝试一下,去发现我IDEA竟然这样..
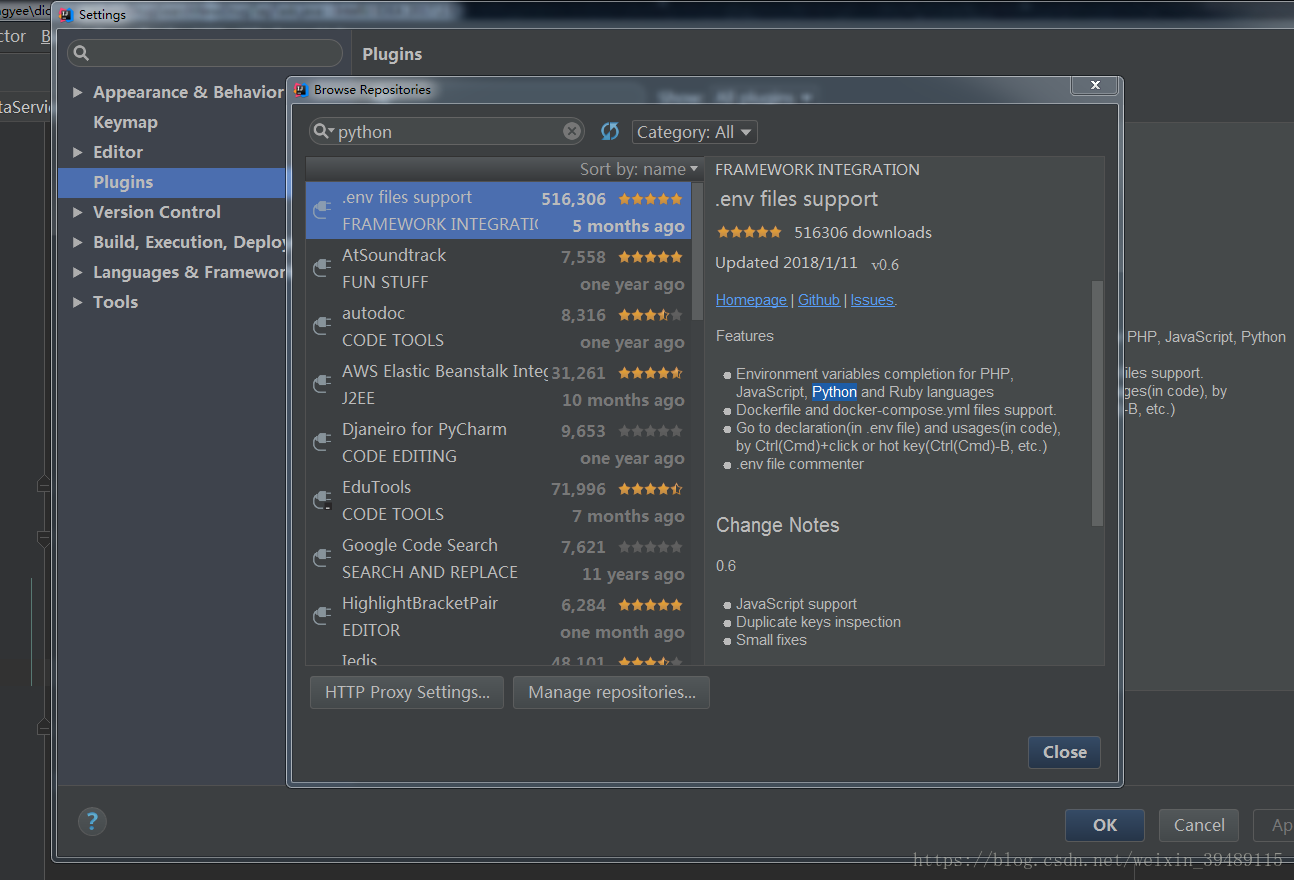
................................................................................................................尴尬...............................................................................................
虽然尴尬但是依旧要保持理智,果断卸载了这个版本的IDEA,上官网下载最新版本的IDEA。
此处省略安装过程,直接看看能不能搜索python插件.
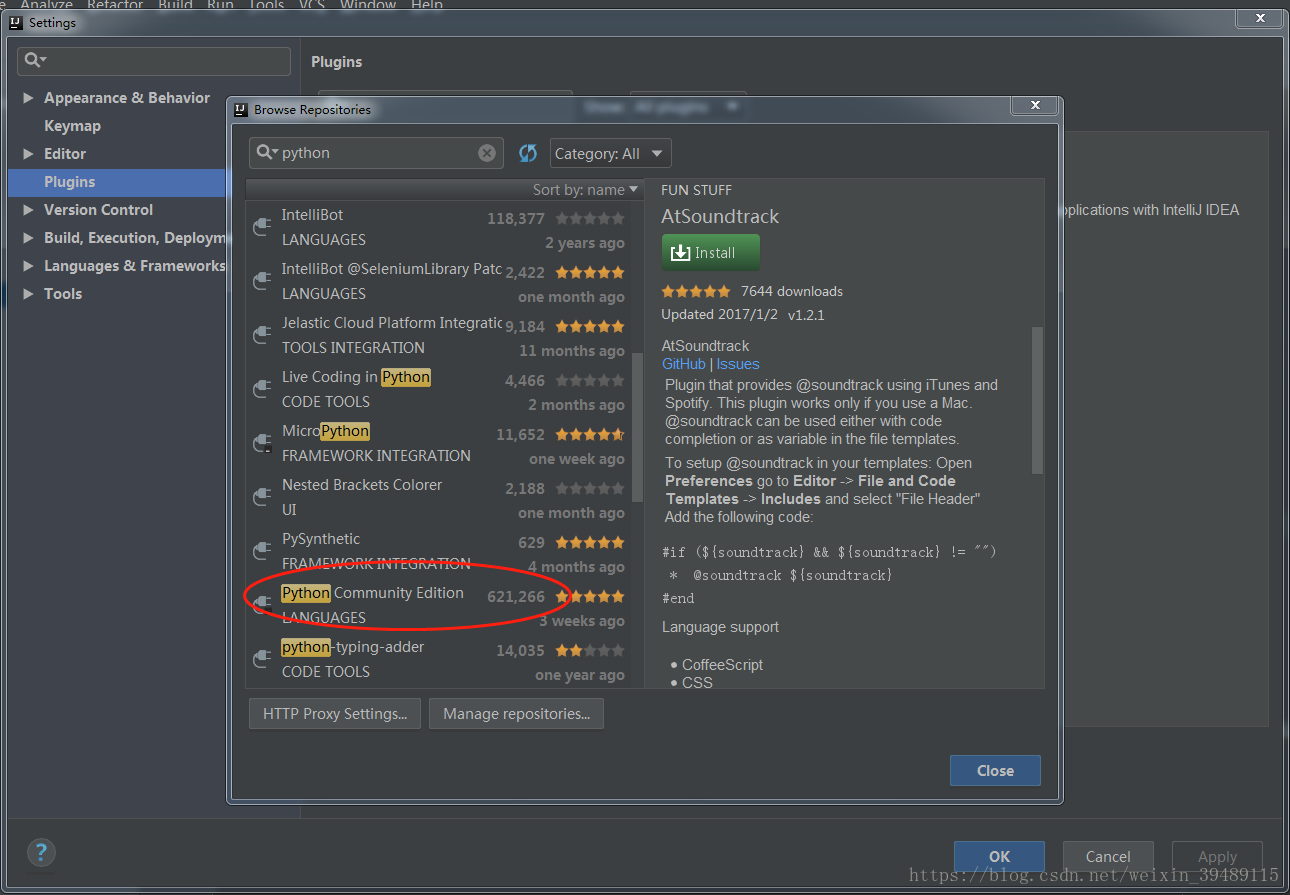
是的,下载了最新的idea就没问题了。既然没问题了直接点击install,稍后片刻就安装成功了。
铺垫了这么多,这回是真的可以编写代码了,让我先乐一会,嘻嘻!
---------------------------------------------------------------------------------------------------------------------------------
在此先展示一下代码的效果
pic1:输入您想要的的图片的关键词
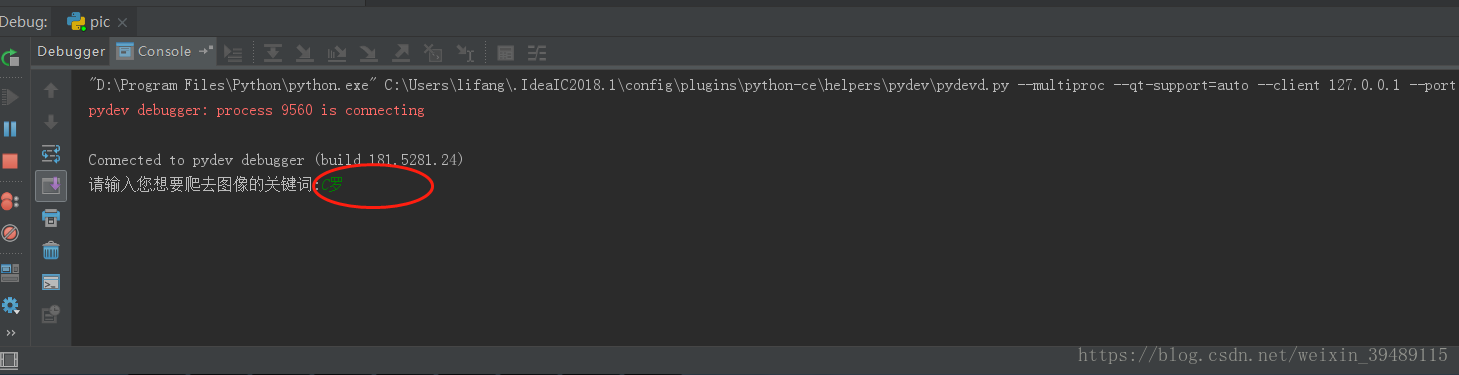
pic2:抓取中....
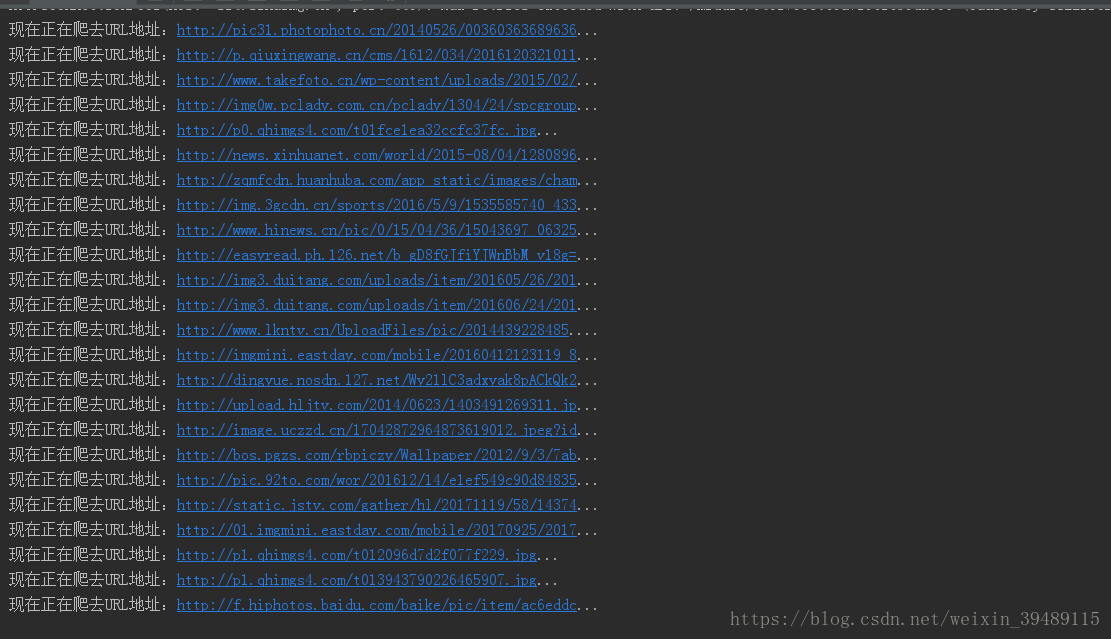
pic3:成果
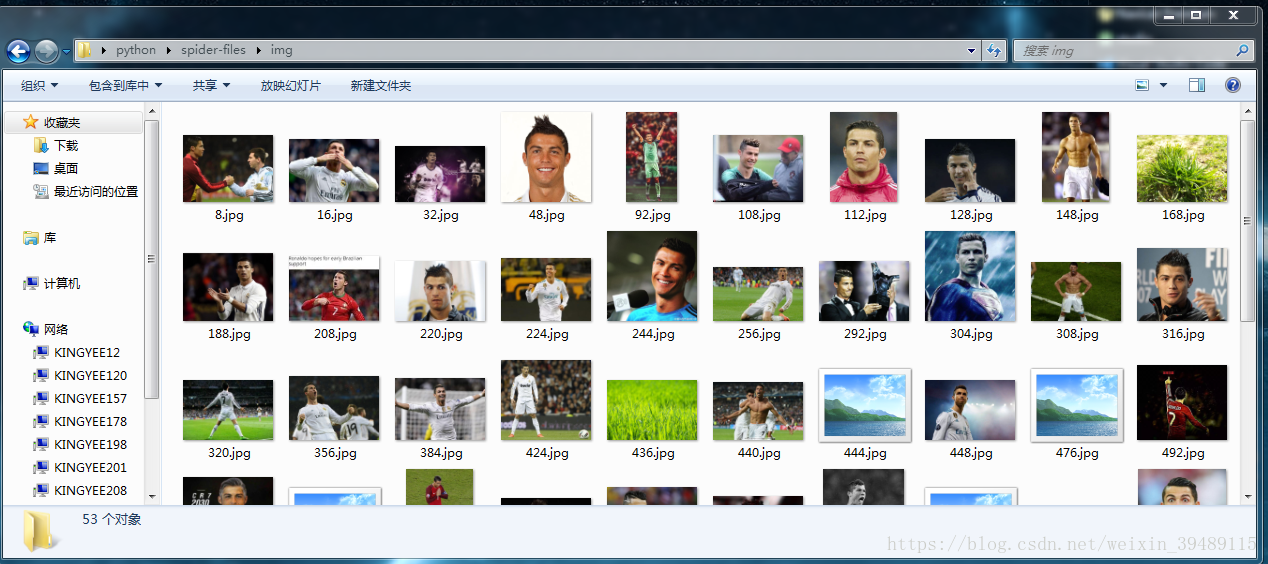
哈哈,作为一个伪球迷,我还是非常喜欢C罗的。
那么直接贴上代码吧。
-------------------------------------------图片爬取代码------------------------------------------------------------------------
# -*- coding:UTF-8 -*- # Python Http客户端库,编写爬虫和测试服务器响应数据. # 文件名:pic.py # 作者:lifang # 日期:2018/06/27 :15:36 import requests import re import random def spiderPic(html, keyword): print('正在查找:' + keyword + '对应图像信息,正在百度图像库下载文件......') pattern_pic = '"objURL":"(.*?)",' for addr in re.findall(pattern_pic, html, re.S): print('现在正在爬去URL地址:' + str(addr)[0:50] + "...") try: pics = requests.get(addr) pic_url='C:/Users/lifang/Desktop/python/spider-files/img/'+ str(random.randrange(0, 1000, 4)) +'.jpg' fq = open(pic_url,'wb') fq.write(pics.content) fq.close() except Exception as e: print(e) continue # Python主函数 if __name__ == '__main__': word = input('请输入您想要爬去图像的关键词:') #http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word=keyword result = requests.get('http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word) #print(result.text) spiderPic(result.text,word)
扫码关注我,和我一起成长,做一个终身学习
者!!!!















 3519
3519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









