from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import requests
def test_bs():
#设置url
url='https://www.maoyan.com/films?showType=3'
#设置请求头
headers={'User-Agent': UserAgent().chrome}
#发送请求
response=requests.get(url, headers=headers)
print('-----aaa-----')
# print(response.text)
#解析响应
soup=BeautifulSoup(response.text,'lxml')
#提取名称
names=[name.text for name in soup.select('span[class="name"]')]
#提取评分
grades=[grade.text for grade in soup.select('div[class~="channel-detail"][class~="channel-detail-orange"]')]
#打印结果
print('----bbb---')
for i,j in zip(names,grades):
print(f'name={i}, grade={j}')
if __name__ == '__main__':
test_bs()
2.pyquery
from fake_useragent import UserAgent
from pyquery import PyQuery as pq
import requests
def test_bs():
#设置url
url='https://www.maoyan.com/films?showType=3'
#设置请求头
headers={'User-Agent': UserAgent().chrome}
#发送请求
response=requests.get(url, headers=headers)
#解析响应
#构建一个pyquery对象
doc=pq(response.text)
print(response.text)
#提取名称
name_divs=doc('div.channel-detail.movie-item-title')
names=[name_divs.eq(i).text() for i in range(len(name_divs))]
#提取评分
grade_divs=doc('div.channel-detail.channel-detail-orange')
grades=[grade_divs.eq(j).text() for j in range(len(grade_divs))]
#打印结果
for m,n in zip(names,grades):
print(f'name={m}, grade={n}')
if __name__ == '__main__':
test_bs()
3.xpath
from fake_useragent import UserAgent
from pyquery import PyQuery as pq
import requests
from lxml import etree
def test_xpath():
#设置url
url='https://www.maoyan.com/films?showType=3'
#设置请求头
headers={'User-Agent': UserAgent().chrome}
#发送请求
response=requests.get(url, headers=headers)
# print(response.text)
#解析响应
#构建一个etree对象
e=etree.HTML(response.text)
#提取名称
names=e.xpath('//div[@class="channel-detail movie-item-title"]/@title')
# print(names)
#提取评分
grades=[div.xpath('string(.)') for div in e.xpath('//div[@class="channel-detail channel-detail-orange"]')]
#打印结果
for m,n in zip(names,grades):
print(f'name={m}, grade={n}')
if __name__ == '__main__':
test_xpath()
4.re,findall
from fake_useragent import UserAgent
import requests
import re
def test_bs():
#设置url
url='https://www.maoyan.com/films?showType=3'
#设置请求头
headers={'User-Agent': UserAgent().chrome}
#发送请求
response=requests.get(url, headers=headers)
#解析响应
#提取名称
names=re.findall('<div class="channel-detail movie-item-title" title="(.+?)">',response.text)
#提取评分
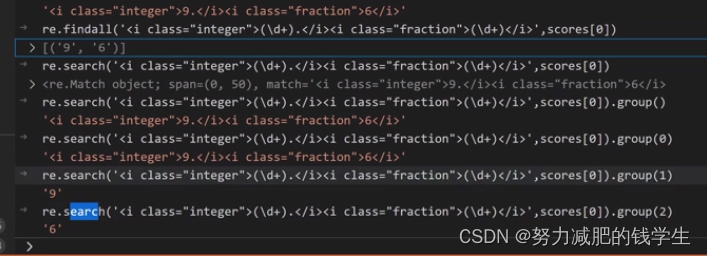
grades=[get_score(data) for data in re.findall('<div class="channel-detail channel-detail-orange">(.+?)</div>',response.text)]
#打印结果
for m,n in zip(names,grades):
print(f'name={m}, grade={n}')
def get_score(data):
if data!='暂无评分':
data='.'.join(re.findall('\d+',data))
return data
if __name__ == '__main__':
test_bs()






















 1145
1145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









