





Beyond User Embedding Matrix: Learning to Hash for Modeling Large-Scale Users in Recommendation (SIGIR 2020)
摘要:
处理大规模数据和冷启动用户是推荐系统的两大挑战。在真实场景(千万级别用户)下,很难利用用户的embedding矩阵储存个性化的用户偏好。许多研究者关注具有丰富历史信息的用户,然而,在真实的系统里,大多数用户都只有少量交互信息。在本文的工作中,作者提出了一种新的用户偏好表示方法PreHash,同时考虑到了大规模数据和冷启动用户。在该方法中,根据用户的历史交互信息生成了一系列篮子。具有相似偏好的用户自动被分在用一个篮子。之后将会学习每一个篮子的表示。在设计篮子时,只有有限的参数被储存,这样大大节省了内存。更重要的是,当用户进行新的交互行为后,他的篮子和表示会相应的更新,这样可以更有效得理解和建模用户。该算法还十分灵活,可以在很多推荐算法中替代其用户embedding矩阵。因此,我们在很多SOTA算法上进行了实验。实验结果展示该算法不仅取得了更好的效果,还减少了模型的参数。
1 Introduction:
个性化的用户偏好向量在推荐系统里非常重要。先前的工作为每个用户生成其偏好特征向量,并把他们当作特征矩阵储存。矩阵分解方法通常使用一个特定向量表示用户。一些深度模型也使用embedding层将用户映射为偏好向量。
然而,这些方法很难应用于实际的大规模数据上。原因之一是,储存这样一个用户embedding矩阵很困难(内存和计算时间)。同时,其无法考虑到冷启动用户。最后,这些算法无法做到增量学习,即在更新用户特征向量时只能重新训练模型。
构建用户偏好特征向量的简单方法就是将与之交互过的物品向量求和。然而对于冷启动用户,这样的方法不适用。
本文提出的PreHash方法是一种灵活的用户偏好表示模块,可以替代很多推荐方法中的用户embedding矩阵。PreHash有两个部分,历史部分和hash部分。历史部分使用一个注意力网络提取历史偏好向量。在hash部分,有许多篮子,每一个篮子包含偏好相似的用户。Hash部分最重要的功能是对于每一个用户,他都会找到一些与其行为类似的频繁用户。
3 用户偏好哈希:
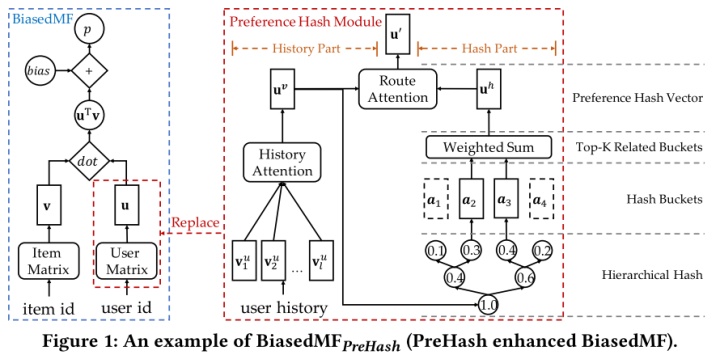
3.1核心思想
学习用户偏好向量通过两种方式:用户近期交互过的物品,与当前用户有相似偏好的其他用户。因此使用一个history part从用户的交互历史中学到用户的历史偏好。为了找到与当前用户偏好类似的用户,这里设计了一个hash part建模用户的hash偏好向量。最后用注意力网络将两个part混合。
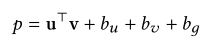
biasedMF,相对于普通的矩阵分解加上了biases项。PreHash将其用户表示部分u替换。
3.2历史部分
这一部分从用户以往的交互信息中捕获了偏好。考虑到每当对于一个新的物品,有一些物品能显著表达用户偏好,而一些物品则不行。所以这里采取了注意力网络对物品向量加权。v是目标物品的向量。权重可以看做当前物品和历史物品的关联程度。根号l是对交互次数做标准化。
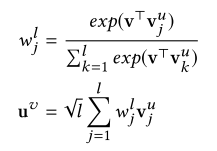
关于注意力网络的解释:是否购买iphone,与用户以前购买的book信息无关。
3.3哈希部分
仅仅利用历史向量不足以捕获用户偏好,因为很多新用户没有足够的交互信息。这里使用了一个哈希模块,根据与目标用户的相似性(根据历史物品交互),找到一些频繁用户来表示目标用户。哈希部分的功能就是用有限的空间储存和计算偏好。
在哈希部分,偏好类似的用户使用共同的桶来储存偏好。当有新的交互后,这一部分可以动态更新。
3.3.1 哈希桶
用来储存类似用户的偏好。首先将每个桶a与一个频繁用户u绑定。将其称作“锚用户”。他们最终的哈希向量直接来源于a:
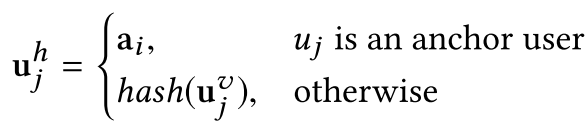
在这里的哈希函数可以看做输入用户历史向量,输出其哈希向量。
这里的频繁用户可以被预先定义。本文采取简单的策略,直接选取交互行为最多的用户。
对于其余用户,PreHash使用层级哈希找到最关联的篮子。然后将篮子向量加权求和得到当前用户的哈希向量。
3.3.2层级哈希
一个全连接树,历史向量u作为输入,每一个节点有一个决策向量n,从父节点继承权重。第i层第j个节点。假定其有c个子节点,其权重分配:
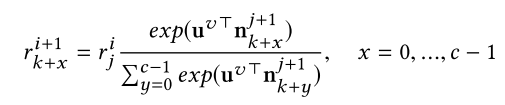
目的也是为了获得用户和桶的关联权重。
为什么采用哈希?提高计算效率。
3.3.3Top-k加权求和
为了得到用户哈希偏好,这里不对所有的篮子加权求和,只考虑关联最大的k个篮子
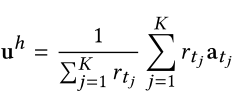
3.4模型输出
为了生成最终的用户偏好向量,PreHash使用一个注意力网络。将两个向量变成最终的用户表示。类似加权求和的效果。
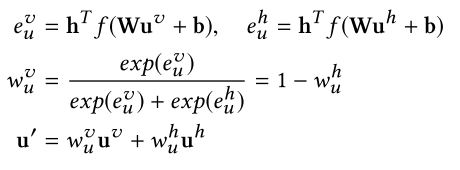
4 实验设置
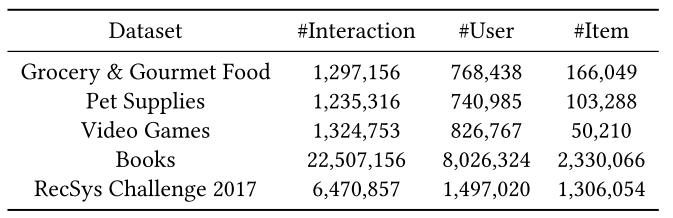
数据集:亚马逊电子商务数据集的四个子集,以及RecSys Challenge 2017数据集。
Baseline:矩阵分解的经典方法,以及深度的经典方法Wide&Deep等
训练:将任务视为top-n推荐。使用pair-wise训练策略(BPR那篇文章)训练所有的模型。对每一个正交互样本,随机采样其负样本。
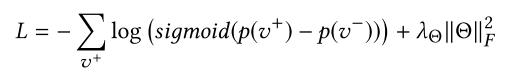
是相应的预测结果。损失函数鼓励对正样本的预测高于负样本。
5 实验结果分析
实验部分写的很清楚,首先提出了四个需要回答的问题,之后逐一验证。

5.1有效性
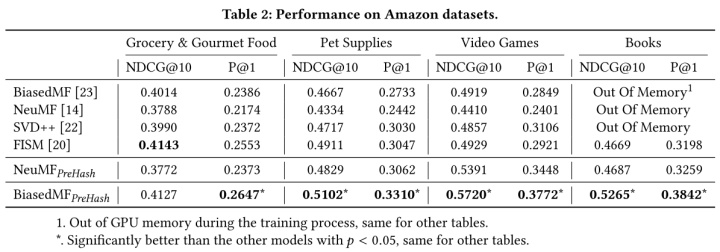
首先,两种常见的矩阵分解方法取得了最差的效果,这是由于数据的稀疏性。FISM远远好于其他方法。他没有用户偏好矩阵,而是直接根据物品相似性进行推荐。结果说明了矩阵分解方法在大型稀疏数据集上效果很差,必须采取新的方法来考虑用户偏好。FISM是基于物品相似度的方法,也表明了基于用户交互项进行用户表示的方法比使用user embedding矩阵的方法好。这也验证了最近发现的ItemKNN要比很多SOTA网络方法好。
为什么加上PreHash之后标准的矩阵分解方法效果变好了很多?原因在于在进行目标物品推荐的时候,获取了每名用户的历史信息。对于每名目标用户,hash部分帮助找到一些相关的篮子来储存类似用户的偏好。这些历史信息对为每位用户的推荐有帮助,特别是冷启动用户。除此以外的优点:省内存。
5.2高效性
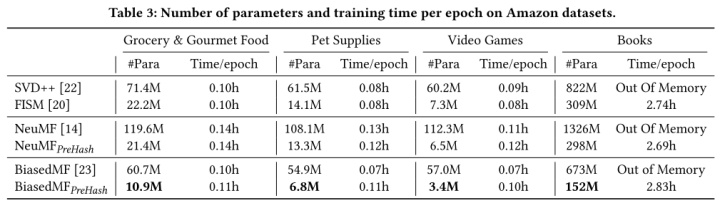
根据结果列表,可以看出PreHash的方法相比原始方法大大节省了参数。
5.3灵活性
验证是否可以在深度模型中使用:
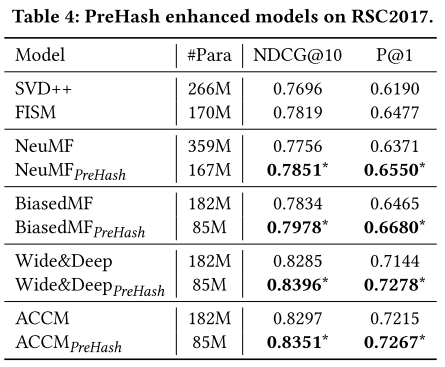
深度模型好的原因是其利用到了review信息。三个深度模型的参数相同原因是相比于用户物品embedding矩阵而言,其网络参数数量可忽略。
5.4在冷启动用户上
测试集上的用户被划分为了三个不同类别。以往少于三次交互的成为冷启动用户
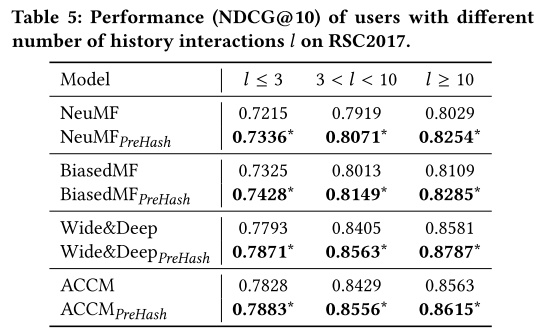
实验结果表明,效果在三个部分都有提升。PreHash好的原因是在hash部分显式得利用到了同组频繁用户(warm user)的偏好。
6.1剥离实验
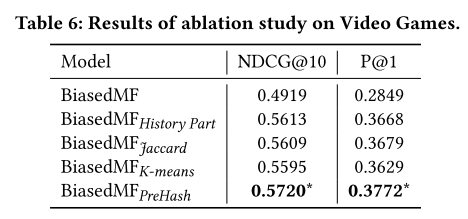
去除hash part,只包含history part的效果已经比较好。因为在矩阵过于稀疏时,矩阵分解中的潜向量很难捕捉到用户历史和偏好。但是history part可以捕捉到。
与一些聚类算法相对比(用聚类id用户)。展示了PreHash在建模相似用户偏好的有效性。
6.2参数敏感度
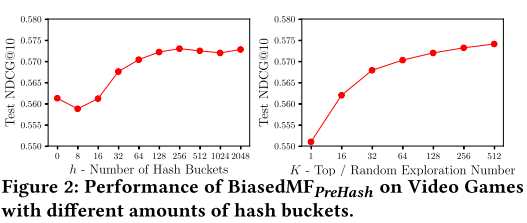
篮子的个数增加时,性能是先减小在增加,这说明可能当篮子数量小时反而会引起组内混乱。
6.3案例分析

为了观察PreHash在篮子中学到了什么。检索了每个篮子里出现次数最多物品。可以观察到,在层级hash后,两个篮子相关但是彼此不同。两个篮子分别是游戏软件和硬件。证明PreHash中算法的有效性。
对我们的启发:
- 用户建模部分一定要关注冷启动用户,可以将其与频繁用户关联。
- 在融合两方面的特征时,可以使用一些技巧代替直接concat。
本文已独家授权公众号浅梦的学习笔记发布在微信公众平台。















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









