






点击上方蓝字关注我吧!
本篇文章大概8000字,阅读时间大约10分钟
Netty的高性能,不仅体现在使用了I/O多路复用模型,以及优化的线程模型的设计上(减少锁粒度,减少上下文切换,隔离线程池等),还在一些数据收发的设计细节上下足了功夫。
你可能会想,收发网络消息不就调用个Socket的read和write就完事儿了么?多大点儿事儿啊!但这样武断的结论就狭隘了,不妨学习一下Netty的设计思想,在项目里也可以借鉴。
本文先讨论Netty接收缓冲区的设计和优化思路,并且我联想到Java对synchronized关键字的优化,故最后也和synchronized的自适应自旋锁做了一个对比。
记得在以下系列文章里:
Netty是如何处理新连接接入事件的?
Netty服务端接收的新连接是如何绑定到worker线程池的?
Netty在接收完新连接后,默认为何要为其注册读事件,其处理I/O事件的优先级是什么?
总结Netty的新连接接入和数据读写相关的面试题
服务器间歇性的接收不到新连接,可能是什么原因,如何排查解决?
如何理解Netty的channelReadComplete和channelRead事件,使用有什么注意事项?
总结Netty处理新连接的接入或者处理SocketChannel的OP_READ事件时,都简单提了一下它的自适应缓冲区分配策略,本文就正式拆解一下这个策略的设计思想和源码实现,希望能开拓一下技术视野,并且在平时开发中有所借鉴。
再次以处理SocketChannel的OP_READ事件为例,想必你对整个流程已经非常熟悉,下面直接定位到关键源码,看NioByteUnsafe这个内部类的read方法,关于Netty的unsafe,可以参考文章:Netty为何在Channel里设计Unsafe,且针对不同类型的Channel设计了两大类实现?
NioByteUnsafe是客户端Channel内聚合的,用于处理SocketChannel上的I/O操作的工具类,本身位于Netty的pipeline结构里的头部节点,即本质是出站处理器。如下其读取数据的read方法源码,只看前面部分:
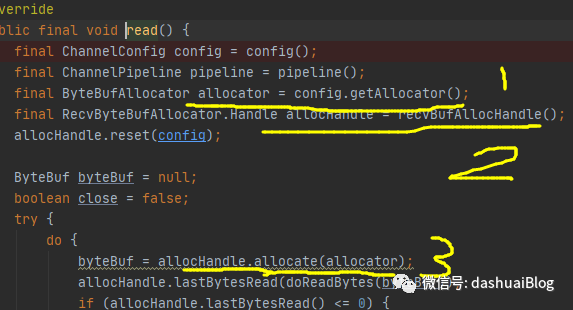
以上,在黄色1和2处,赫然发现两个内存分配相关的操作,这些操作有一些设计思想值得拆解,下面先看黄色1的内存分配器——allocator对象,它在Netty的NioSocketChannel聚合的配置对象里被自动初始化(即在Channel被初始化时,就完成了allocator的构造):

这里提前知道一个结论:【Netty自己分配的内存,默认都是池化的堆外内存,除非操作系统不支持,才分配池化的堆内存,另外用户也可以手动分配堆内存或者非池化的内存,这个分场景,比如非I/O操作手动分配堆内存即可】
如下是内存分配器——allocator的初始化逻辑,后续会专题总结,这里简单看:
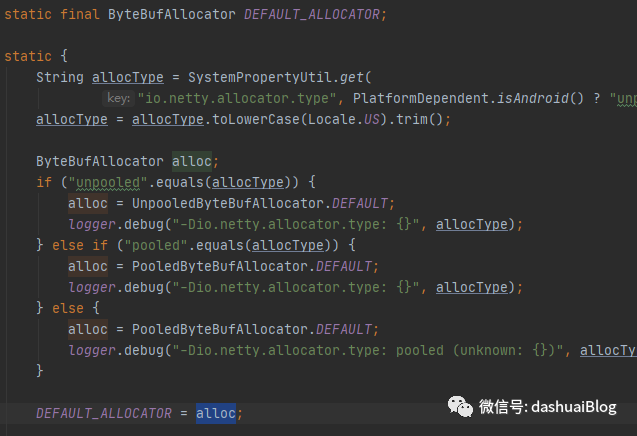
以上,先判断操作系统是不是安卓的,如果不是,那么就分配池化内存(一般服务器都在Linux部署,可以认为Netty默认就是池化内存分配,除非用户手动指定)。
接着看池化判断这条线,如果是池化分配,那么allocator获得的对象就是PooledByteBufAllocator.DEFAULT,从名字也能看出它是一个池化的内存分配器:

以上也能看出默认分配的是堆外(directBufferPreferred)内存,细节不再深究,后续在内存图像专题总结。
回到NioByteUnsafe的read方法:
以上,看黄色2处的allocHandle对象,这也是一个Netty的内存分配器,它也在SocketChannel聚合的配置对象里被自动初始化,鉴于【配置对象】一词的高频出现,下面先看下这个配置对象,比如在黄色1处,可以通过config方法获取:

关于这个config对象具体的创建时机可以参考如下文章,这里不多说:
Netty的I/O模型实例化的时候,都做了什么?
为何Netty创建服务端(客户端同)Channel用的是反射?
值得一提的是,Netty的config的设计和unsafe的设计如出一辙,Netty服务端Channel和客户端Channel分别聚合了自己的config对象,并以内部类形式存在。如下在实例化Netty封装的SocketChannel时,它自动被创建:

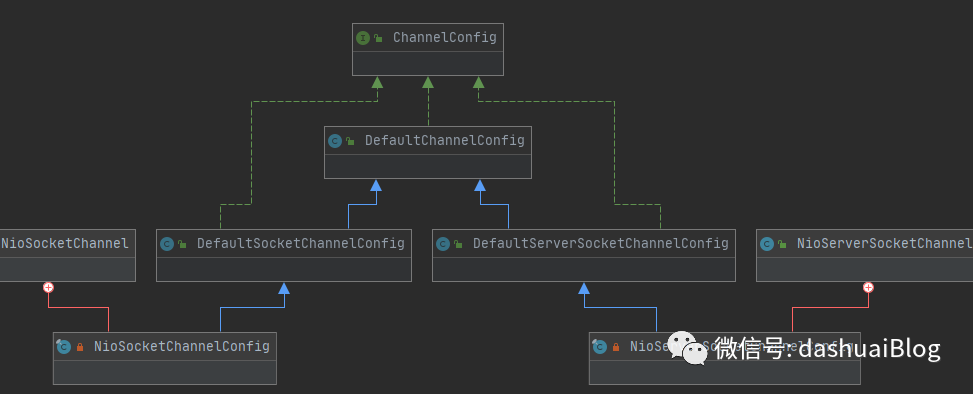
下面是整个config的类图,只关注NIO模型的TCP相关Channel的类图,可以清晰的看到它的整个面貌——全部来自于ChannelConfig接口,并且以内部类形式被聚合到Netty的两大类Channel内部:
下面进入这个NioSocketChannelConfig构造器(同理服务端Channel聚合的是NioServerSocketChannelConfig,看一个即可),它最终会调用到config的顶级父类——DefaultChannelConfig构造器:

以上,DefaultChannelConfig内部又调用了重载构造器,其中第二个参数非常重要,即默认创建了一个内存分配器——AdaptiveRecvByteBufAllocator,可以翻译为自适应的接收缓冲区分配器,顾名思义它就是Netty用来读数据的载体,它在这里被创建后,最终经过config构造器的层层调用,会赋值给NioSocketChannelConfig的一个属性——rcvBufAllocator,这样后续读数据时,可以直接拿到它,如下。
简单看下这个接收缓冲区分配器AdaptiveRecvByteBufAllocator的上下游的类图,如下:
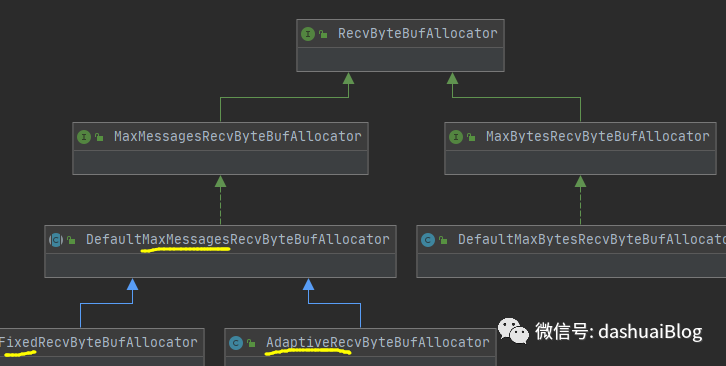
Netty通过接口RecvByteBufAllocator派生了两类接收缓冲区分配器:
1、一类是固定大小的
2、一类是下面要讨论的自适应分配的
通过AdaptiveRecvByteBufAllocator这个接收缓冲区分配器,可以保证有足够的内存去缓存入站(就是读到Netty内部)的数据,并且还能保证这些内存不会被浪费,这是Netty的一个优化点。
下面看接收缓冲区分配器的顶级接口——RecvByteBufAllocator:
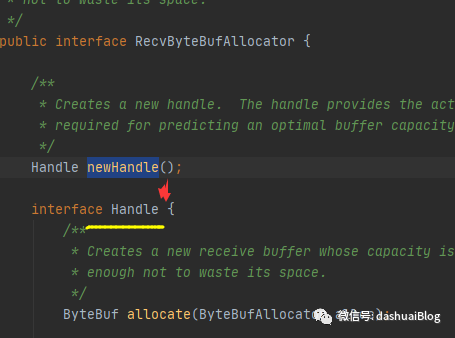
该接收缓冲区分配器的内部聚合了一个Handle接口,实际分配内存的操作都是这个接口来完成,子类的不同分配器会有不同的实现。
下面看这个AdaptiveRecvByteBufAllocator类:
它的设计思路是:先预测分配一块儿内存,后续会通过一种反馈机制来动态调节这块内存的大小,目的是不主观的浪费内存,且够用。
具体的,Netty读某个SocketChannel的数据,实际上不一定调用一次read就能读完,这和传输的数据量大小以及编码方法有关。如果上一次read后,预先分配的接收缓冲区已经被填满,那么AdaptiveRecvByteBufAllocator会逐渐的增大该缓冲区的大小,反之如果连续两次read操作,其接收的数据量都没有到达预先分配的缓冲区的某个阈值,那么说明分配的内存太大了,此时AdaptiveRecvByteBufAllocator会逐渐的减少该缓冲区的大小。
以上,可以说是比较先进的做法了,最先进应该谈不上,但是思路值得借鉴,算是一种视野的开拓吧,平时写类似代码可能都是先怼一个内存块儿,等不够的时候再动态扩容,一下子1.5倍,甚至2倍,这样会极大概率导致内存被浪费。所以绝对不能为了看细节而看细节,应该是从细节里读到一些设计思想和技术广度的提升点,否则容易陷入技术细节的陷阱,一脸懵逼还毫无乐趣可言。
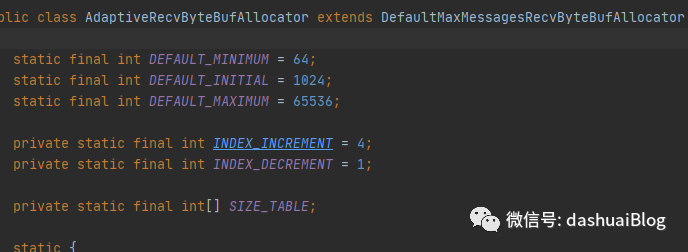
下面从源码中剖析它具体的实现策略,抓主要矛盾——仍然是从Netty读取SocketChannel的数据这条线入手。先看AdaptiveRecvByteBufAllocator的默认构造器,Netty就是直接用的默认构造器:

发现它有三个参数:
1、DEFAULT_MINIMUM=64
2、DEFAULT_INITIAL=1024=1M
3、DEFAULT_MAXIMUM=65536=64M
意思是说,自适应缓冲分配器默认分配的内存块儿,其初始大小总是1024个字节(=1MB),后续动态调整时,规格最小不会小于64字节,最大不会大于65536字节(=64MB)。也就是说Netty根据一些处理网络消息的经验,来预先分配一个1MB大小的缓冲区,去承载接收的数据。不过,用户可以根据自己项目的测试表现去单独配置。
我还看到该类有如下一个常量——SIZE_TABLE数组,该属性还是挺重要的,简单看下:

它的初始化在AdaptiveRecvByteBufAllocator的一个静态块儿,如下:
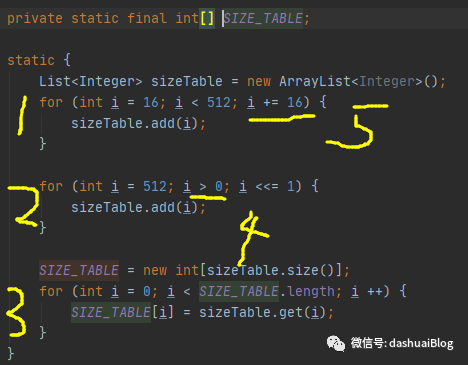
以上乍一看就能理解:Netty是按照从小到大的顺序,提前设定可分配的缓冲区大小,后续可以直接从该常量数组——SIZE_TABLE里取这些内存块的规格,这是一种提前规划规格的设计思想。
SIZE_TABLE设计的思路是:可以看上面黄色1和5处,最小的内存块是16字节,从16字节开始,然后是32,48。。。即步长是每次增加16字节,直到512字节规格后,步长改为2倍增长,即黄色2和4处。直到int类型数溢出(超过21亿多)结束。搞定后在黄色3处给SIZE_TABLE赋值。可以算一下,这个SIZE_TABLE的第38个元素是65536。
以上,有了这些基础后,再看AdaptiveRecvByteBufAllocator的构建过程,最终,它调用到核心构造器,如下:
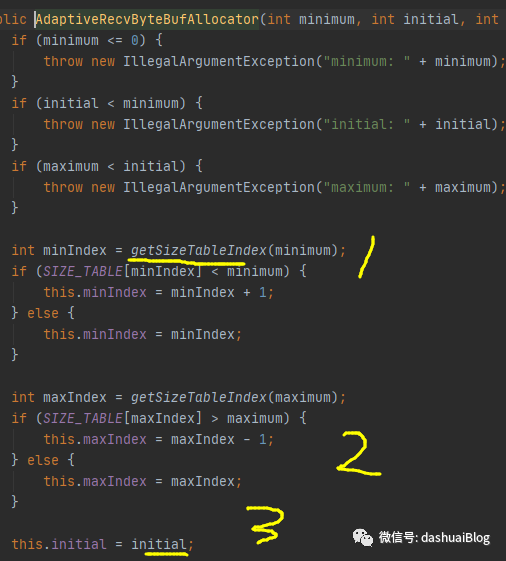
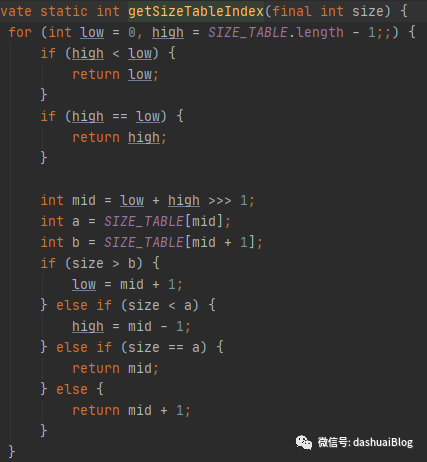
以上,看黄色1处,Netty先使用二分查找算法,即getSizeTableIndex(64),从SIZE_TABLE里找到64这个规格的数组元素的下标,如下,也能看到Netty是如何使用的二分查找算法,比如计算mid要考虑溢出问题,除以2可以用位运算代替,速度更快:
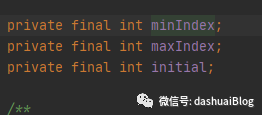
回到AdaptiveRecvByteBufAllocator核心构造器,接下来对65536元素的下标也是一样的获取套路,最后在黄色2和3处,分别为如下三个属性赋值(这些属性都是SIZE_TABLE的一些下标),后续动态调整内存块时,会用到:
以上,细节不在深究,抓主要矛盾,下面看看它究竟是怎么用起来的。再次回到NioByteUnsafe的read方法:
以上,看黄色2处的具体实现,如下调用了Netty的Unsafe的recvBufAllocHandle()方法,它会返回前面说的接收缓冲区分配器内部的Handle对象,这个handle对象负责真正的内存分配工作。不同的接收缓冲区分配器对Handle有不同的实现策略。在首次调用Unsafe的read,读SocketChannel的数据时,它会被初始化:
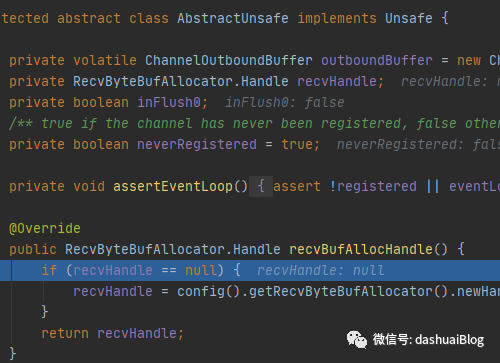
初始化Handle对象的核心方法是上面if语句块里的newHandle方法,下面看这个AdaptiveRecvByteBufAllocator的newHandle()方法:
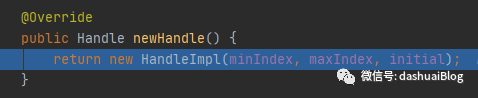
以上,它内部创建了一个Handle对象——HandleImpl,它的三个参数前面都分析过,都是内存规格数组SIZE_TABLE的下标,在构建AdaptiveRecvByteBufAllocator对象时已经被提前配置好,默认分别是:
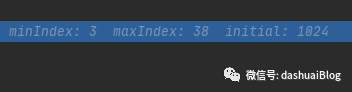
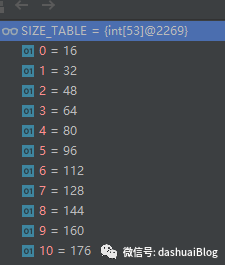
意思是从AdaptiveRecvByteBufAllocator内提前设计的内存块规格数组SIZE_TABLE里,取下标3——代表最小的内存块规格,大小为64字节,取下标38——代表是最大内存块规格,大小为65536字节(64MB),而初始化的内存块大小为1024字节(1MB),如下SIZE_TABLE的内部值:
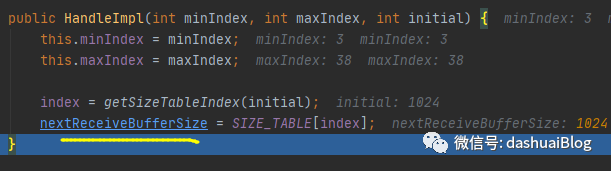
下面,进入这个Handle的构造器HandleImpl,前面说过Handle是Netty的Config体系里的内部接口,自然它的所有实现版本都是对应接收缓冲区的内部类,如下在自适应的接收缓冲区分配器AdaptiveRecvByteBufAllocator里,它就是简单的通过二分查找,计算出初次预测的接收缓冲区大小,确实为1024字节:
以上,有了这些基础后,再次回到NioByteUnsafe的read方法:
以上,看黄色代码2处的下一行,有一个allocHandle.reset(config)方法,如下:
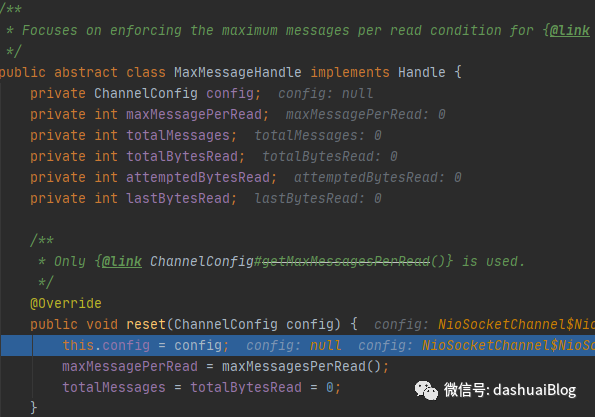
以上,这个reset方法是Handle接口提供的方法,此处调用的是其默认实现——MaxMessageHandle类里的reset,该类也是HandleImpl的父类,如下它们的继承关系:
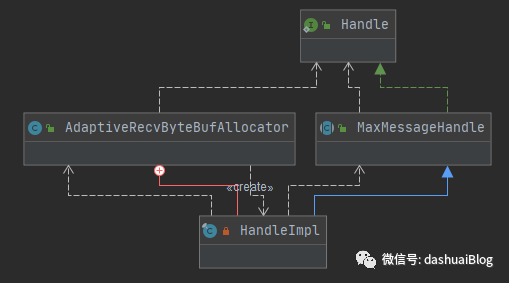
reset方法的具体作用:在每次新的一轮读数据的操作前,重置一些约束参数,比如totalBytesRead是记录读取的字节数,totalMessages记录读取的消息数,maxMessagePerRead在服务端代表一轮读数据时,对新连接接收的最大数量,在客户端代表是一次读取的最大消息数,默认都是16。
注意,这里的一轮是说在NIO线程的run里执行完select方法,轮询出有OP_READ事件就绪的Channel后,后续的处理I/O事件的过程,如果是服务端Channel绑定的NIO线程,那么就是针对的新连接接入过程,如是客户端Channel绑定的NIO线程,那么就是针对的后续的消息收发过程,可以参考文章:品Netty源码:体会高效轮询I/O事件的策略设计思想
下面,继续看NioByteUnsafe的read方法的黄色代码3处:
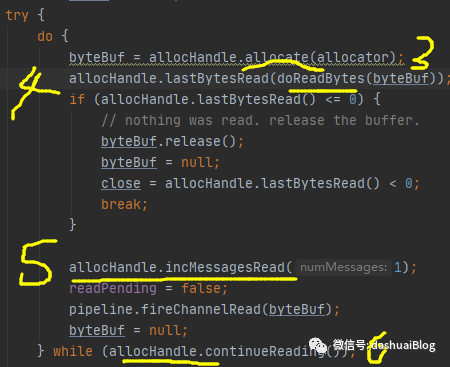
即在一个do-while循环里读对应的SocketChannel里的数据。可以结合文章如何理解Netty的channelReadComplete和channelRead事件,使用有什么注意事项?一起看。
下面,进入黄色3的allocHandle.allocate(allocator);方法。如下,前面也说了,内存分配的底层还是依赖的内存分配器allocator,关于这个分配器,后续拆解Netty内存图像的过程中会详细总结,透彻分析。这里一笔带过:
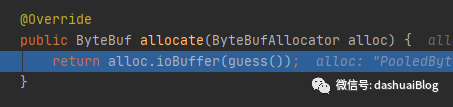
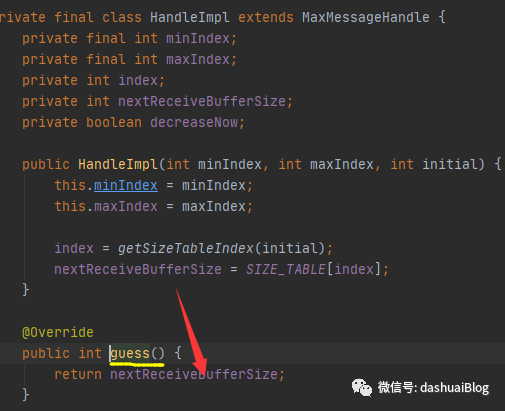
以上可以看到,Netty确实是默认分配I/O内存——即堆外内存专用于I/O事件处理,其大小通过HandleImpl的guess方法计算,计算方法很简单,如下,就是返回的AdaptiveRecvByteBufAllocator内部类HandleImpl的属性nextReceiveBufferSize,其值为预测的接收缓冲区初始值1024字节,也就是说ByteBuf变量初始化大小为1024字节,即1MB:
下面看read的黄色代码4处,即doReadBytes方法,如下该方法内部会真正的从SocketChannel里读数据,然后写入ByteBuf变量,这是JDK的API,我们不关心:

以上,很自然的,在写ByteBuf之前,Netty会通过前面的自适应接收缓冲区分配器AdaptiveRecvByteBufAllocator,去预测当前ByteBuf大小(初始是1024字节)是否合适,预测逻辑为:
1、先通过ByteBuf的容量和可写指针,拿到剩余的可写空间(这部分这里不细究,后续内存图像专题讨论)
2、然后通过这个剩余空间去预测,预测方法就是调用了
allocHandle.attemptedBytesRead(byteBuf.writableBytes())和allocHandle.attemptedBytesRead()两个重载方法,如下先调用带参数的,逻辑很简单,就是获取并且设置了剩余可写空间size,初始化时,使得attemptedBytesRead属性是1024:

接着,调用不含参的attemptedBytesRead:
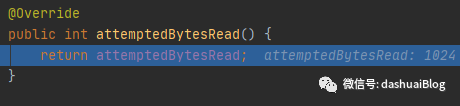
也很简单,就是拿到这个剩余可写空间的大小,初始时这里肯定是1024,接着就是读取SocketChannel的数据并写入ByteBuf,我的这个demo给服务器发送了一个大数据,这里一下子就将1024大小的ByteBuf填满了,如下byteBuf被填满(widx=1024,cap=1024,ridx=0代表还没被读过):

然后调用黄色4的lastBytesRead方法,如下:
以上,主要是在父类的lastBytesRead里记录本次读取的字节数lastBytesRead=bytes=1024和本轮总共读取的字节数totalBytesRead,如下是lastBytesRead(xxx)方法源码:
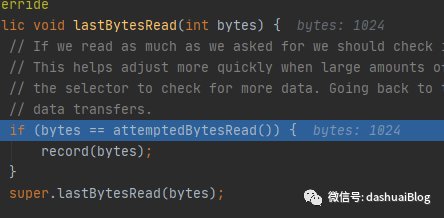
以上,发现super父类的lastBytesRead(xxx)之前,会先做一次接收缓冲区大小的预测,这里我的demo上一次读取了1024字节,和读取之前的接收缓冲区大小一样,故会调用record方法调整。
调整的大概逻辑是:如果上一次读取的数据量和预测的一样多,那么此时就应该检查是否需要增加接收缓冲区大小,这里有操作系统局部性原理的体现,因为一次没读完,Netty认为下次读大概率还是很大的量!毕竟为了权衡低延迟,Netty不会一直让NIO的线程在这里处理新数据(新连接),别忘了各个I/O线程是串行的在运转run,所以Netty限制了一次读取的消息(新连接)数最大不能超过16个,显然如果不及时动态调整接收缓冲区大小,那么很容易导致本轮的I/O数据读不完(已经读了16次)就返回了,这样后续的业务流程就会变慢,因为完整的数据要等到下次轮询Channel后才能继续获取。。。这是非常垃圾的设计,为此Netty就对这里设计了预测分配和动态调整接收缓冲区的策略。
以上这段话是精髓,揭示了为何这样设计的真正目的,以前说的什么怕浪费内存,其实并不是核心原因,它只是次要原因,我搞个大内存的机器又如何?
下面看调整过程的实现,有两种调整策略:
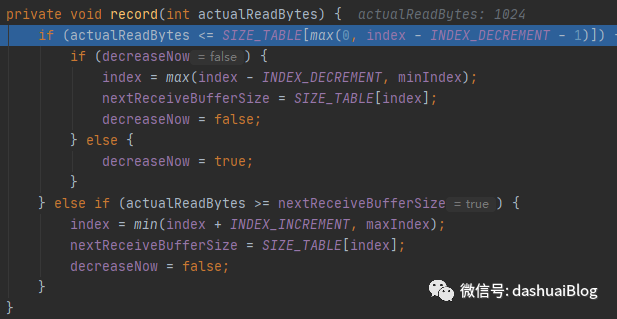
1、缩减缓冲区大小
首先做一个判断——当上次实际读取的字节数比内存规格表SIZE_TABLE的上一次分配的规格小,这里就使用第一种调整策略——如果连续两次读操作接收的数据量(连续两次通过变量decreaseNow判断,逻辑不难,不多说)都没达到预先分配的缓冲区的某个阈值,那么说明之前分配的内存大了,此时AdaptiveRecvByteBufAllocator会逐渐减少缓冲区规格。如下是增加的内存和减少的内存的步长,简单了解,这里缩减为SIZE_TABLE[index]内存规格的上一个大小:

2、扩大缓冲区大小
我的demo会走这里,即上一次实际读取的字节数如果不小于上一次分配的接收缓冲区大小,那么就递增缓冲区,递增原则是不能超过65536字节(64MB),下限是上一次的SIZE_TABLE[index]的下4个元素的内存规格(初次是32,第二次变为36),而且随着次数推移,这个规则是变化的:
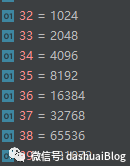
可以回忆前面对内存规格表SIZE_TABLE的拆解。这里也加深了理解——即Netty之所以使用提前规划内存规格表SIZE_TABLE的策略,目的就是为了能迅速的动态调整内存的缩放规则,这样编码好写,逻辑很清晰,不需要再实时计算,加快了速度,典型的空间换时间。
以上,Netty整个的接收缓冲区的预测和动态调整过程就拆解完毕,拆解细节不是目的,目的是从中吸取经验和开拓视野,见识一些多样性的编码策略和设计方案。
收个尾,如下read:
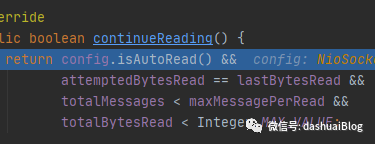
每次读一次数据,都会调用黄色6处,即do-while的判断条件,allocHandle.continueReading():
前面也总结过,参考文章:
Netty在接收完新连接后,默认为何要为其注册读事件,其处理I/O事件的优先级是什么?
如何理解Netty的channelReadComplete和channelRead事件,使用有什么注意事项?
即,上一次读的字节数等于预先分配的接收缓冲区大小(说明此时没有读完Channel的数据),且总的读取字节数和次数都不超过限制,那么会继续读。
01
—
做个小结
1、Netty的接收缓冲区会对当前缓冲区大小做步进的缩减或者扩容
上次读取的字节数比内存规格表SIZE_TABLE的上一次分配的规格小,且如果是连续两次都没达到预先分配的缓冲区的某个阈值,那么说明之前分配的内存大了,此时AdaptiveRecvByteBufAllocator会逐渐减少缓冲区规格。缩减为SIZE_TABLE[index]内存规格的上一个大小
上次读取的字节数如果不小于上一次分配的接收缓冲区大小,那么就递增缓冲区,递增原则是不能超过65536字节(64MB),下限是上一次的SIZE_TABLE[index]的下4个元素的内存规格(初次是32,第二次变为36),而且随着次数推移,这个规则是变化的
细节不深究,体会这种套路,必要的时候回头看即可,以上,通过上述分析得知AdaptiveReevByteBufAllocator根据本次读取的实际字节数对下次接收缓冲区的容量进行预测和调整。
2、Netty动态缓冲区分配器优点如下:
更具备通用性:Netty作为一个通用的NIO框架,不能对用户的应用场景进行假设,可以使用它做流式计算,也可以用它做RCP框架,不同的应用场景传输的数据流大小千差万别。因此Netty根据上次实际读取的数据流大小对下次的接收缓冲区进行预测和调整,能够最大限度地满足不同行业的应用场景的需要
性能更高:分配容量过大会导致内存开销增加,容量过小需要频繁地内存扩张来接收大的请求消息,两种场景都会导致性能下降。万幸的是Netty都帮我们考虑到了,假如是聊天服务,一些聊天消息的数据流大小一般不会超过1MB,假如突然某个用户发了一个大的消息,size为2MB,此时接收缓冲区扩张为2MB,后续如果缓冲区不能收缩,则每次缓冲区创建都会分配2MB内存,但后续消息大部分又恢复为1MB以内大小了。。。如果有大量的并发连接,那么可能会导致内存溢出
3、提前规划内存规格表SIZE_TABLE的优点:
目的就是为了能迅速的动态调整内存的缩放规则,这样编码好写,逻辑很清晰,不需要再实时计算,加快了速度,典型的空间换时间
4、掌握二分查找算法的写法和原理:O(logn)
计算mid要考虑int溢出问题,除以2可以用位运算代替,速度更快
5、为何这样设计?
以前说的什么怕浪费内存,其实并不是核心原因,它只是表象,我搞个大内存的机器又如何?为了权衡低延迟,Netty不会一直让NIO的线程在这里处理新数据(新连接),别忘了各个I/O线程是串行的在运转run,所以Netty限制了一次读取的消息(新连接)数最大不能超过16个,显然如果不及时动态调整接收缓冲区大小,那么很容易导致本轮的I/O数据读不完(已经读了16次)就返回了,这样后续的业务流程就会变慢,因为完整的数据要等到下次轮询Channel后才能继续获取。。。这是非常垃圾的设计,为此Netty就对这里设计了预测分配和动态调整接收缓冲区的策略,降低一次收不完的概率。
关于synchronized的自适应自旋锁
关于这个关键字的用法和注意事项不多总结,对应两个字节码指令monitorenter和monitorexit,同步方法是对应一个标记位,本质上这些指令会被JVM的解释器识别和执行,映射到对应的C++函数,如下是HotSpot虚拟机的源码结构,其中的vm下的interpreter包是实现的字节码解释器:

其中有一个函数cppinterpreter_zero.cpp,这是解释器的主要实现函数,里面有一个入口方法,即在一个主循环里依次执行Java线程(c++的JavaThread类)获取的线程栈帧里的字节码指令:
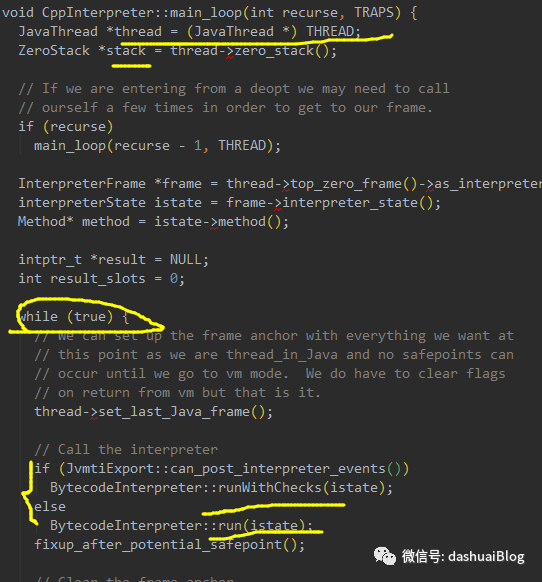
核心就是这个BytecodeInterpreter的run方法:
这个函数非常长。。。函数里会识别synchronized的关键字指令,会写一些所谓的加锁,解锁的业务逻辑,本质和Java层面写加锁、解锁的逻辑没啥区别,并且最终透传到操作系统:
1、要么是原子指令,比如CMPXCHG 汇编指令(就是所谓的Java的CAS算法),作用是比较并交换操作数,比如【CMPXCHG 目的操作数,源操作数】,意思是将累加器的值与首操作数(目的操作数,在左边)比较并交换。。。
2、要么是对应一些实现互斥的汇编指令:mutex lock
其中和synchronized关键字相关的代码片段如下:
想了想,代码量巨多。。。本文不讨论了。。。
下面是一些老掉牙的结论:
1、synchronized可以保证同一时刻只有一个线程进入临界区
2、可以保证共享变量的内存可见性
3、Java中每个对象都可以作为锁,这是synchronized实现同步的基础
4、普通同步方法,锁是当前实例对象
5、静态同步方法,锁是当前类的Class对象
6、同步方法块,锁是括号里面的对象
7、当一个线程访问同步代码块时,它首先需要得到锁才能执行同步代码,当退出或者抛出异常时必须要释放锁
8、非公平,不可中断,悲观,读写共享,可重入
9、如果线程竞争不激烈,synchronized比JUC的锁性能好,否则在高并发环境下还是建议使用Lock实现锁,或者关闭自旋,偏向锁等参数进行调优
直接总结它在JDK6以后的优化过程:
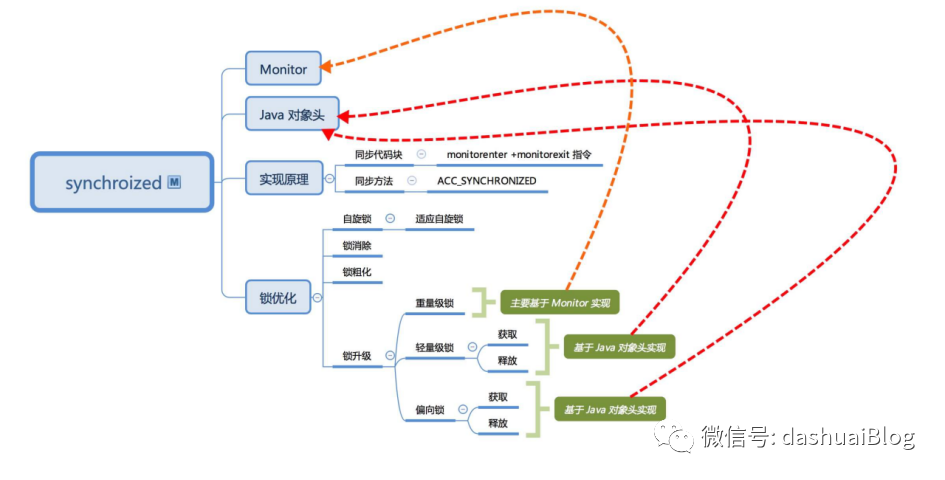
在从偏向锁升级为轻量级锁时,会用CAS进行自旋,即线程的阻塞和唤醒需要CPU从用户态进入内核态,频繁的阻塞和唤醒对CPU来说是一件负担重的工作。同时许多应用里对象锁的锁状态只会持续很短一段时间,JDK的研发组认为,就为了这一段很短的时间,去频繁地阻塞和唤醒线程是非常不值得的。所以为Java的synchronized关键字实现引入了自旋锁机制。
所谓自旋,就是让获取不到锁的线程(假设是A)等待一段时间,不会被操作系统立即挂起,看持有锁的线程(假设是B)是否会很快释放锁。A怎么等待呢?让A执行一段无意义的循环即可——所谓的自旋。自旋不能替代阻塞,虽然它可以避免线程频繁切换带来的开销,但是占用了CPU时间。如果持有锁的线程B很快就释放了锁,那么自旋的效率会非常好,反之自旋的线程A会白白消耗CPU资源,反而带来浪费。所以说自旋的次数必须有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,那么A仍然要被挂起。
自旋锁在JDK1.4中引入,默认关闭。JDK7开始,自旋锁默认启用,自旋次数由JVM设置,不建议设置的重试次数过多,因为自旋意味着长时间占用CPU。自旋锁重试后如果依然失败,会升级至重量级锁,在这个状态下未抢到锁的线程都会进入Monitor,之后会被阻塞在ContentionList队列中。对于轻量级锁,其性能提升的依据是“对绝大部分锁,在整个生命周期内都不会存在激烈的竞争,且线程持有锁的时间都很短”。如果打破这个依据则除了互斥的开销外,还有额外的自旋(废CPU),因此在有多线程竞争的情况下,轻量级锁比重量级锁更慢。即在锁竞争不激烈且锁占用时间非常短的场景下,自旋锁可以提高系统性能。一旦锁竞争激烈或锁占用的时间过长,自旋锁将会导致大量的线程一直处于CAS重试状态,占用CPU资源,反而会增加系统性能开销。所以自旋锁和重量级锁的使用都要结合实际场景。在高负载、高并发的场景下,可以通过设置JVM参数来关闭自旋锁,优化系统性能,示例代码如下:
-XX:-UseSpinning//关闭自旋锁优化(Java7后默认打开)
-XX:PreBlockSpin//修改默认的自旋次数。JDK7后,去掉此参数,由JVM控制,自旋的默认次数为10
以上只是调整自旋锁的自旋次数,还是不给力。假如将参数调整为8,但极有可能很多持有锁的线程都是等刚刚竞争线程退出自旋时就释放了锁(即多自旋一两次就可以大概率的获取锁),这就很尴尬了。于是JDK6以后还引入自适应自旋锁——让JVM去自动判断,预测自旋此时。所谓自适应就意味着自旋次数不固定,它由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果线程A自旋成功,那么下次自旋的次数会更加多,因为JVM认为上次成功了,那么此次自旋也很有可能会再次成功(依然是操作系统局部性原理)。反之,如果对于某个锁很少有自旋能成功获取,那么以后要获取这个锁时,自旋的次数会减少甚至省略自旋,以免浪费CPU资源。
以上,可以从理论上宏观了解JVM背后都为我们做了哪些付出——基于历史经验来预测未来,这和应用软件的设计和优化方向一脉相承!都可以借鉴。
END
点亮在看,你最好看
点击此处写留言~


点















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









