








一.Spark SQL执行计划概述
1.1 4个计划
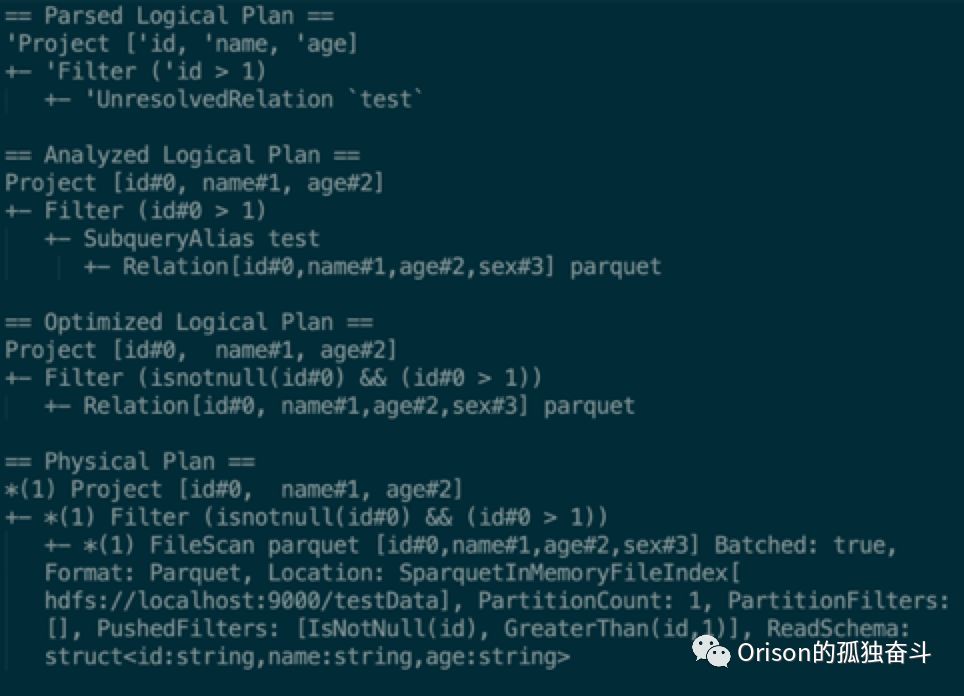
Parsed Logical Plan
Spark使用 ANTLR4来将SQL字符串解析为最初的LogicalPlan。
Analyzed Logical Plan
调用Spark的Analyzer将最初的Parsed Plan转化成分析后的LogicalPlan。
Optimized Logical Plan
将Analyzed Logical Plan调用catalyst内置的优化策略,生成优化后的LogicalPlan。
Physical Plan
使用Spark的物理策略处理优化后的LogicalPlan的每个节点。
1.2 一个例子
SELECT id, name, age FROM test
WHERE id > 1
1.3 Spark SQL目前所做的优化
Databricks以及众多Spark代码贡献者为Spark做了许多优化,最著名的,有SQL优化引擎Catalyst,有针对内存、CPU和I/O的Tungsten计划,还有正在逐步完善的CBO。在其中产生了Code Generation技术和Vectorization技术。参考[SPARK-12795]和[SPARK-12992]。
CodeGen
全称是Whole-Stage Code Generation技术,会在运行时动态生成Java代码,避免虚函数调用。
Vectorization
每次调用next()返回一个batch的数据,减少虚函数调用次数。
CBO
基于代价的优化,主要用来减少join的shuffle。
首先还是说一下基本的火山模型。
1.3.1 Volcano
火山模型是一般SQL引擎经常使用的一种模型,还是用上文的例子:
SELECT id, name, age FROM test
WHERE id > 1

其语法树的火山模型如上图,project节点传next()方法给filter节点,filter节点传next()给全表扫描节点,然后全表扫描节点返回元组给tuple,以此类推。可以发现调用了非常多的next()方法。而next()函数又是虚函数,那么什么是虚函数?给出以下几个定义:
虚函数的存在是为了多态和继承。
编译器会创建虚函数表,虚函数表的作用就是保存自己类中虚函数的地址。
虚函数会调用多个CPU指令。
Java中其实没有虚函数的概念,它的普通函数就相当于C++的虚函数。
可以看到,如果是这种传统的火山模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









