






对于KMeans算法聚类数k的选取非常重要,下面介绍两种常用的选择方法。
手肘法
手肘法的核心指标是SSE(sum of the squared errors,误差平方和):
其中,Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。 随着聚类数K的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和(SSE)自然会逐渐变小。但K增大到一定程度时,K增大对SSE减小的作用越来越小,因此K—SSE曲线呈现手肘状,拐点附近的K值通常为适当的分群数量。
如下的聚类数——SSE曲线,我们可以考虑使用4-6的聚类数,建模后观察结果,并最终根据业务需求确定分群。
#创建空列表,依次创建k=1~15的模型并 保存SSE结果
sse_list = [ ]
K = range(1, 15)
for k in range(1,15):
kmeans=KMeans(n_clusters=k, n_jobs = 6)
kmeans.fit(Zdata)
sse_list.append(kmeans.inertia_) #model.inertia_返回模型的误差平方和,保存进入列表
print(sse_list)
#折线图展示聚类数——SSE曲线
plt.figure()
plt.plot(np.array(K), sse_list, 'bx-')
plt.rcParams['figure.figsize'] = [12,8]
plt.xlabel('分群数量',fontsize=18)
plt.ylabel('SSE',fontsize=18)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()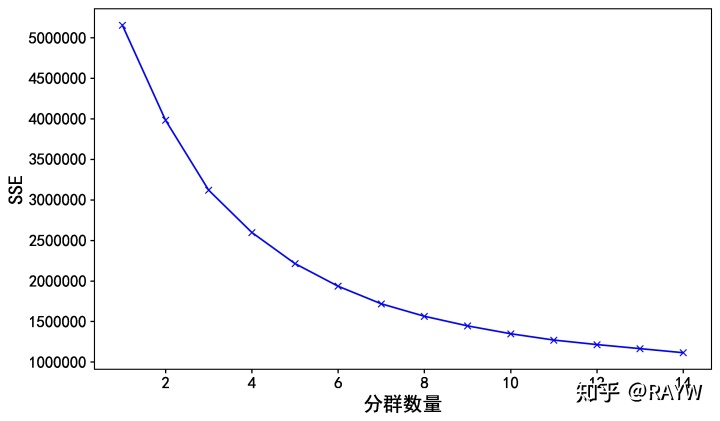
轮廓系数法
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],且簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。
那么,很自然地,平均轮廓系数(silhouette_score)最大的k便是最佳聚类数。
在python中,使用sklearn库的metrics.silhouette_score()方法可以很容易作出K—平均轮廓系数曲线。
需要注意的是,轮廓系数计算非常耗费资源,通常可以设置sample_size使用抽样计算平均轮廓系数。
#分别创建分群2-15的KMeans模型
clusters = range(2,15)
sc_scores = []
for k in clusters:
kmeans_model = KMeans(n_clusters=k, n_jobs = 6).fit(Zdata)
sc_score = metrics.silhouette_score(Zdata, kmeans_model.labels_
,sample_size=10000, metric='euclidean')
sc_scores.append(sc_score)
print(sc_scores)
#作出K—平均轮廓系数曲线
plt.figure()
plt.plot(clusters, sc_scores, 'bx-')
plt.rcParams['figure.figsize'] = [12,8]
plt.xlabel('分群数量',fontsize=18)
plt.ylabel('Silhouette Coefficient Score',fontsize=18) #样本平均轮廓系数
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
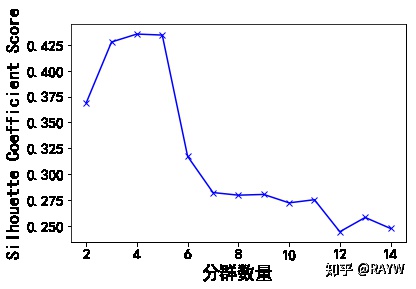














 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









