






全量复制
全量复制的原理
redis全量复制的原理是,首先将master本身的RDB文件同步给slave,而在同步期间,master写入的命令也会记录下来(master内部有一个复制缓冲区,会记录同步时master新增的写入),当slave将RDB加载完后,会通过偏移量的对比将这期间master写入的值同步给slave。
来看一张完整的复制流程图:
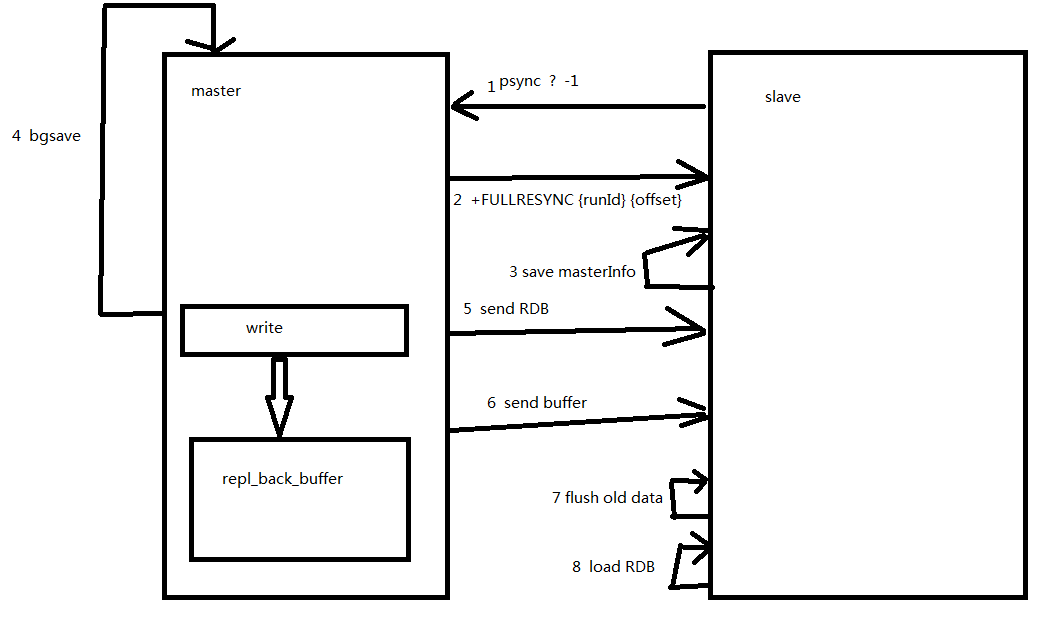
1. slave内部首先会发送一个psync的命令给master 这个命令第一个参数是runId,第二个参数是偏移量,而由于是第一次复制,slave不知道master的runId,也不知道自己偏移量,这时候会传一个问号和-1,告诉master节点是第一次同步。
2. 当master接受到psync ? -1 时,就知道slave是要全量复制,就会将自己的runID和offset告知slave
3.slave会将master信息保存
4.master这时会做一个RDB的生成(bgsave)
5.将RDB发送给slave
6.将复制缓冲区记录的操作也发送给slave
7.slave清空自己的所有老数据
8.slave这时就会加载RDB文件以及复制缓冲区数据,完成同步。
全量复制的开销
1.bgsave的开销,每次bgsave需要fork子进程,对内存和CPU的开销很大
2.RDB文件网络传输的时间(网络带宽)
3.从节点清空数据的时间
4.从节点加载RDB的时间
5.可能的AOF重写时间(如果我们的从节点开启了AOF,则加载完RDB后会对AOF进行一个重写,保证AOF是最新的)
部分复制
为什么要部分复制? 在redis2.8版本之前,如果master和slave之间的网络发生了抖动连接断开,就会导致slave完全不知道master的动作,同步就会出问题,而为了保证数据一致,等网络恢复后进行一次全量复制。而全量复制的开销是很大的,redis2.8版本就提个了一个部分复制的功能。
部分复制的实现原理:
当master和slave断开连接时,master会将期间所做的操作记录到复制缓存区当中(可以看成是一个队列,其大小默认1M)。待slave重连后,slave会向master发送psync命令并传入offset和runId,这时候,如果master发现slave传输的偏移量的值,在缓存区队列范围中,就会将从offset开始到队列结束的数据传给slave,从而达到同步,降低了使用全量复制的开销。















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









