







进行算法设计的时候,时常有这样的体会:如果已经知道一道题目可以用动态规划求解,那么很容易找到相应的动态规划算法并实现;动态规划算法的难度不在于实现,而在于分析和设计—— 首先你得知道这道题目需要用动态规划来求解。本文,我们主要在分析动态规划在算法分析设计和实现中的应用,讲解动态规划的原理、设计和实现。在很多情况下,可能我们能直观地想到动态规划的算法;但是有些情况下动态规划算法却比较隐蔽,难以发现。本文,主要为你解答这个最大的疑惑:什么类型的问题可以使用动态规划算法?应该如何设计动态规划算法?
例一:有一段楼梯有10级台阶,规定每一步只能跨一级或两级,要登上第10级台阶有几种不同的走法?
分析:很显然,这道题的对应的数学表达式是F(n)=F(n-1) + F(n-2);其中F(1)=1, F(2)=2。很自然的状况是,采用递归函数来求解:
def solution( n ):
if(n>=0 and n<2):
return n
else:
return solution(n-1) + solution(n-2)如果我们计算F(10), 先需要计算F(9) F(8); 但是我们计算F(9)的时候,又需要计算F(8),很明显,F(8)被计算了多次,存在重复计算;同理F(3)被重复计算的次数就更多了。算法分析与设计的核心在于 根据题目特点,减少重复计算。 在不改变算法结构的情况下,我们可以做如下改进:
import numpy as np
def solution( n ):
dp = np.zeros(n)
if(n>=0 and n<2):
return n
elif(dp[n-1]!= 0):
return dp[n-1]
dp[n-1] = solution(n-1) + solution(n-2)
return dp[n-1]这是一种递归形似的写法,进一步,我们可以将递归去掉:
def fib(n):
dp = np.zeros(n)
dp[0]=1
dp[1]=1
for i in range(2,n):
dp[i] = dp [i-2]+dp[i-1]
return dp[n-1]当然,我们还可以进一步精简,仅仅用两个变量来保存前两次的计算结果;
def fib(n):
a,b = 0, 1
for i in range(1,n):
a, b = b, a+b
print(b)例二:01背包问题
有n个重量和价值分别为weight, value的物品;背包最大负重为W,求能用背包装下的物品的最大价值?
输入:n =4
weight=2, 1, 3, 2
value =3, 2, 4, 2
W=5
输出=7
思考二:上文中的记忆化搜索,如果可以将递归变为循环,这就是动态规划,对应的数学表达式如下:
def backpack(m,A):
n = len(A)
f = [[False] * (m + 1) for _ in range(n + 1)]#每一行代表一个物品,列代表背包容量
f[0][0] = True
for i in range(1,n+1):
f[i][0] = True
for j in range(1,m+1):
if j>=A[i-1]: #背包容量大于第i-1件物品
f[i][j] = f[i-1][j] or f[i-1][j-A[i-1]]
else:
f[i][j] = f[i-1][j]
for i in range(m,-1,-1):
if f[n][i]:
return[i]
return 0
思考三:递归形式的多样化
我们刚才的递归计算,在i这个维度是逆向的,同样我们可以采用正向的DP。规定dp[i][j]表示前i号物品中能选出重量在j之内的最大价值,则有递推式
dp[i][j] = max(dp[i-1][j] , dp[i-1][j-w[i]] + v[i]);
思考四:我们是如何想到递归算法的?
也许,DP算法的难度不在于告诉你这个题目需要用DP求解,然后让你来实现算法。而在于你首先得意识到这道题目需要用递归求解,这里我们通过分析上面的思考步骤来总结DP算法的典型特征:
1>DP算法起源于DC—— 一个问题的解,可以先分解为求解一系列子问题的解,同时包含重叠子问题:于是,我们得到DP算法的第一个黄金准则:某个问题具有独立而重叠的字问题;子问题不独立,没法进行分治;子问题不重叠,没有进行DP的必要,直接用普通的分治法就可以了。
2>DP算法黄金准则2: 最优子问题—— 子问题的最优解可以推出原问题的最优解。
我们还是来看上面的那个决策树,很明显,DP的本质就在于缓存。我们寻找DP结果的时候,往往是需要遍历这个树,从中找出最优解。但是有些情况下,我们需要寻找的不是最优解,而是可行解,这个时候往往使用DFS或者循环更为有效,后面,我们会给出例子。此时,我们仅仅需要记得,动态规划的第二个条件—— 最优子问题。
所以算法的设计思路不在于一下子就想到了某个问题可以使用DP算法,而在于先看能不能用穷举法,如果可以用问题可以分解,分治法+穷举可以解决;如果问题包含重叠字问题,并且是求解最优解,那么此时用动态规划。
最少的硬币找零问题
贪心算法:就是每次选择最优。
最优化问题的一个典型例子是用最少的硬币找零。
假设您是一家自动售货机制造商的程序员。您的公司希望通过为每笔交易提供尽可能少的零钱来简化工作。
假设一位顾客放入一张美元钞票,花37美分买了一件商品。你能用来找零的最小硬币数是多少?答案是六枚硬币:两个25美分、1个10美分和3个美分。
我们是如何得出六枚硬币的答案的?
我们从硬币列表中最大的硬币(25美分)开始,并尽可能多地使用这些硬币,然后我们转到下一个最低的硬币价值,并尽可能多地使用这些硬币。
第一种方法被称为贪婪方法,因为我们试图立即解决尽可能大的问题。
当我们使用美国硬币时,贪婪的方法效果很好,但假设您的公司决定在下埃尔博尼亚部署自动售货机,在那里,除了通常的1、5、10和25美分硬币外,他们还有一枚21美分的硬币。在这种情况下,我们的贪婪方法无法找到63美分的最优解。加上21美分的硬币,贪婪的方法仍然能找到六枚硬币的解决办法。然而,最佳答案是三个21美分的部分
穷举算法:
为了避免上述情况的发生,我们可以走完所有的路径,然后选择一条最好的。这就是穷举。 对应到教材中,就是把所有可能找零的硬币数都列出来,然后挑最少的。 接下来就教材中的硬币例子,说明动态规划。
递归与动态规划:
让我们看一种方法,我们可以确定我们会找到这个问题的最佳答案。由于本节是关于递归的,您可能已经猜到我们将使用递归解决方案。让我们从识别大小写开始。如果我们试图改变与我们一个硬币的价值相同的数额,答案很简单,一枚硬币。
如果金额不匹配,我们有几个选项。我们想要的是一个便士加上原找零金额减去一个便士所需的硬币数量,或者一个五分硬币加上上原找零金额减去一个五分所需的硬币数量,或者一个10美分硬币加上加上上原找零金额减去一个10美分所需的硬币数量,以此类推。因此,改变原来数额所需的硬币数目可根据以下情况计算:
下面显示了执行我们刚才描述的操作的算法。在第3行中,我们正在检查我们的基本情况;也就是说,我们试图对我们的一个硬币的确切数量进行更改。如果我们没有一个等于变化量的硬币,我们会对每一个不同的硬币价值进行递归调用,而不是我们想要做的改变的数量。第6行显示了如何使用列表理解将硬币列表过滤为小于当前更改值的硬币列表。递归调用还减少了我们需要根据所选硬币的价值进行的更改的总量。递归调用在第7行中进行。注意,在同一行中,我们在硬币数量中添加1,以说明我们使用的是硬币。仅仅添加1就像我们进行了一个递归调用,询问我们在哪里立即满足基本情况条件。
def recMC(coinValueList,change):
minCoins = change
if change in coinValueList:
return 1
else:
for i in [c for c in coinValueList if c <= change]:
numCoins = 1 + recMC(coinValueList,change-i)
if numCoins < minCoins:
minCoins = numCoins
return minCoins
print(recMC([1,5,10,25],63))但是,这个就相当于穷举了,算法太低效。算法的问题是它的效率非常低。事实上,它需要67,716,925次递归调用才能找到4个硬币63美分问题的最优解!要了解我们的方法中的致命缺陷,请参见图5,其中演示了寻找26美分零钱的最佳硬币集所需的377个函数调用中的一小部分。
图中的每个节点对应于对recMC的调用。节点上的标签表示计算硬币数量的变化量。箭头上的标签表示我们刚才使用的硬币。通过这张图,我们可以看到硬币的组合,这些硬币把我们带到了图中的任意点。主要的问题是我们重新做了太多的计算。例如,图表显示,该算法将重新计算硬币的最佳数量,使15美分的变化至少三次。每一次计算,找出15美分硬币的最佳数量,本身需要52个函数调用。显然,我们在浪费大量的时间和精力重新计算旧的结果。
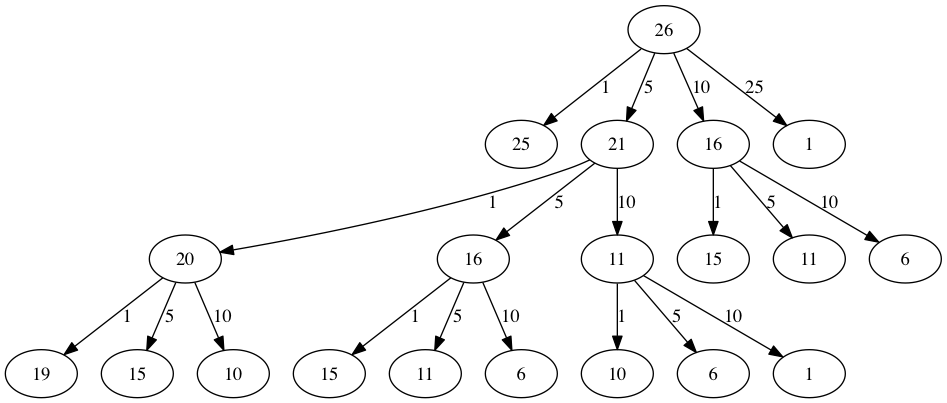
重点:
上面算法,有许多重复的路径,比如剩余面额为16的时候,就在不同的递归路径中出现了。所以,我们为了避免这种重复的面额还要被递归,可以将已经出现的面额所需要的最小找零 硬币个数存起来。比如将16的最小找零面额3存起来,等下次再递归遇到16时,直接判断出现过16,返回3即可。
减少工作量的关键是记住一些过去的结果,这样我们就可以避免重新计算我们已经知道的结果。一个简单的解决方案是,当我们找到硬币时,将最小数量的硬币存储在一个表中。然后,在计算新的最小值之前,我们首先检查表,看看是否已经知道了结果。如果表中已有结果,则使用表中的值,而不是重新计算。
这次,算法就比较高效了。里面已经有了动态规划的思想:把已经知道的最好的路径存起来,下次遇到可以直接用。
def recDC(coinValueList,originalamount,knownResults):
minCoins = originalamount #最小银币个数
if originalamount in coinValueList:
knownResults[originalamount] = 1
return 1
#遇到了已经出现了的面额,而我们又已经计算出了需要的最少硬币数,可以直接调出来返回该数就行了。
elif knownResults[originalamount] > 0:
return knownResults[originalamount]
else:
for i in [coin for coin in coinValueList if coin <= originalamount]:
numCoins = 1 + recDC(coinValueList, originalamount-i,
knownResults)
if numCoins < originalamount:#银币个数<金额
minCoins = numCoins #最小银币个数=银币个数
knownResults[originalamount] =numCoins #当前金额的硬币个数
return minCoins
print(recDC([1,5,10,25],63,[0]*64))请注意,在第6行中,我们添加了一个测试,以查看我们的表中是否包含一定数量更改的最小硬币数。如果没有,我们递归地计算最小值,并将计算出来的最小值存储在表中。使用这种改进的算法减少了我们需要对四枚硬币进行递归调用的次数,将63美分的问题减少到221次调用!
事实上,我们所做的事情并不是动态编程,而是通过使用一种称为“回忆录”的技术(更常见的称为“缓存”)来提高程序的性能。
真正的动态规划:
真正的动态规划会采用更系统化的方法来解决问题。
动态规划的解决方法是从为1分钱找零的最优解开始,逐步递加上去,直到我们需要的找零钱数。这就保证了在算法的每一步过程中,我们已经知道了兑换任何更小数值的零钱时所需的硬币数量的最小值。
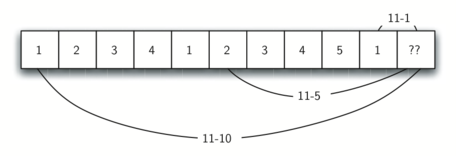
让我们来看看我们如何填写一张最少找零硬币的表格,以便在11美分的零钱中使用。图4说明了这个过程。我们从一分开始。唯一可能的解决办法是一枚硬币(一便士)。下一行显示二美分的最少找零硬币数量。同样,唯一的解决办法是两便士。第五排是事情变得有趣的地方。现在我们有两种选择,五便士或一美分。我们如何决定哪一个是最好的?我们在表格上查一下,四分钱兑换的硬币数是四枚,再加一便士,再加五枚硬币,等于五枚硬币。或者我们可以看一下零美分再加一个5美分硬币就能得到5美分。因为最小的1,所以我们把1存储在表中。快进到表格的尽头,再考虑11美分。图5显示了我们必须考虑的三个选项:
- 一便士加上min{(11-1 = 10美分)的找零数量}
- 一枚五分硬币加上min{(11 - 5 = 6美分)的找零数量}
- 一10美分硬币加min{(11 - 10 = 1美分)的找零数量}
选择1或3将给我们总共两个硬币,这是11美分硬币的最小数量。

下面是一个动态规划算法,用于解决我们的更改问题。
dpMakeChange接受三个参数:一个有效的硬币值列表coinValueList[1,5,10,25],我们想要做的找零金额change,以及每个找零金额所需的最小硬币数量的列表minCoins。函数完成后,minCoins将包含从0到change值的所有值的解决方案。
def dpMakeChange (coinValueList,change,minCoins): # 动态规划解法
'''
动态规划:其所求的最优解是由子问题的最优解构成的.
动态规划是自底向上的计算.
在找零递加的过程中,设法保持每一分钱的递加都是最优解,一直加到求解找零钱
数,自然得到最优解
'''
for coin in range(1,change+1):#从1分到63美分挨个计算
coinCount = coin #先初始化找零的硬币数,假设都用1美分找零
for i in [ c for c in coinValueList if c <=coin]: #硬币数值小于当前金额
if minCoins[coin-i] + 1 < coinCount:#最优列表的数值<初始化找零的硬币数
coinCount = minCoins[coin-i]+1 #最小找零数=最优列表的数值
minCoins[coin] = coinCount #当前金额的最优列表填充
return minCoins[change]#返回最优列表的最后一个值
print(dpMakeChange([1,5,10,25],63,[0]*64))注意,dpMakeChange不是递归函数,尽管我们从递归解决方案开始。重要的是要认识到,仅仅因为您可以编写一个问题的递归解决方案并不意味着它是最好或最有效的解决方案。这个函数中的大部分工作是由第4行开始的循环完成的。在这个循环中,我们考虑使用所有可能的硬币来改变由美分指定的数量。就像我们对上面的11美分示例所做的那样,我们记住最小值并将其存储在我们的minCoins列表中。
虽然我们的算法在计算硬币的最小数量方面做得很好,但它并不能帮助我们做出改变,因为我们没有跟踪我们使用的硬币。我们可以轻松地扩展dpMakeChange来跟踪使用的硬币,只需记住我们为minCoins表中的每个条目添加的最后一个硬币。如果我们知道最后一枚硬币是加起来的,我们可以简单地减去硬币的价值,从而找到表中先前的一项,它告诉我们为了达到这个数量我们添加的最后一枚硬币。我们可以一直追溯到开始。
下面显示修改后的dpMakeChange算法,以跟踪所使用的硬币,以及一个函数printCoins,它向后遍历表,打印出所使用的每枚硬币的价值。main的前两行设置要转换的金额并创建使用的硬币列表。接下来的两行创建存储结果所需的列表。coinsUsed是用于进行找零的硬币的列表,coinCount是用于找零与列表中相应位置的数量的硬币的最小数量。
注意,我们打印出来的硬币直接来自coinsUse数组。对于第一个调用,我们从数组位置63开始,然后打印21。然后我们取63−21=42,并查看列表中的第42元素。我们再一次发现一个21颗藏在那里。最后,数组的元素21也包含了21,给出了三个21美分的部分。
def dpMakeChange(coinValueList,change,minCoins,coinsUsed):
for cents in range(change+1):
coinCount = cents
newCoin = 1
for j in [c for c in coinValueList if c <= cents]:
if minCoins[cents-j] + 1 < coinCount:
coinCount = minCoins[cents-j]+1
newCoin = j
minCoins[cents] = coinCount
coinsUsed[cents] = newCoin
return minCoins[change]
def printCoins(coinsUsed,change):
coin = change
while coin > 0:
thisCoin = coinsUsed[coin]
print(thisCoin)
coin = coin - thisCoin
def main():
amnt = 63
clist = [1,5,10,21,25]
coinsUsed = [0]*(amnt+1)
coinCount = [0]*(amnt+1)
print("Making change for",amnt,"requires")
print(dpMakeChange(clist,amnt,coinCount,coinsUsed),"coins")
print("They are:")
printCoins(coinsUsed,amnt)
print("The used list is as follows:")
print(coinsUsed)
main()














 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









