






应用:客户价值判断模型RFM(Recency Frequency Monetary)常常和聚类算法一起使用,聚类可以用于降维和矢量化(vector quantization),可以将高维特征压缩到一列当中,常常用于图像、声音、视频等非结构化数据,可以大幅压缩数据量
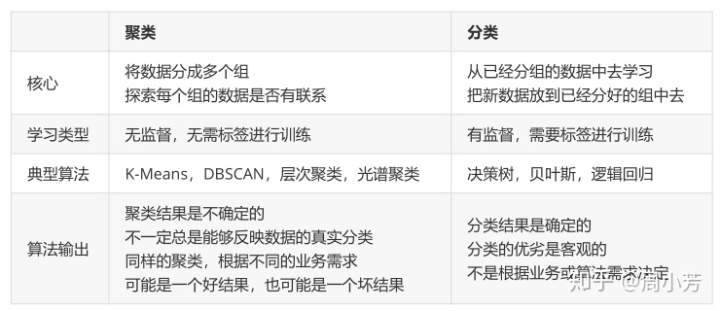
一、手写Kmeans算法
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
#导入数据集
iris = pd.read_csv('iris.txt',header = None)
iris.head()
iris.shape #(150,5)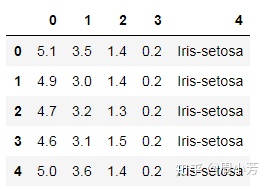
#构建距离的计算公式(注意量纲的统一)
def distEclud(arrA,arrB):
"""
函数功能:计算两个数据集之间的欧式距离
输入:两个array数据集
返回:两个数据集之间的欧氏距离(此处用距离平方和代替距离)
"""
d = arrA-arrB
distance = np.sum(np.power(d,2),axis = 1)
return distance#定义随机投放质心的函数
def randCent(dataSet, k):
"""
函数功能:随机生成k个质心
参数说明:
dataSet:包含标签的数据集
k:簇的个数
返回:
data_cent:K个质心
"""
n = dataSet.shape[1]
data_min = dataSet.iloc[:, :n-1].min()
data_max = dataSet.iloc[:, :n-1].max()
data_cent = np.random.uniform(data_min,data_max,(k, n-1))
return data_cent#定义K-means聚类函数
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
"""
函数功能:k-均值聚类算法
参数说明:
dataSet:带标签数据集
k:簇的个数
distMeas:距离计算函数
createCent:随机质心生成函数
返回:
centroids:质心
result_set:所有数据划分结果
"""
m,n = dataSet.shape #m是样本数,n是特征+标签数
centroids = createCent(dataSet, k) #生成 k个随机质心
clusterAssment = np.zeros((m,3)) #创建m行3列的容器
clusterAssment[:, 0] = np.inf #容器第一列放置最短距离,初始化设为最大值
clusterAssment[:, 1: 3] = -1 #容器第二列放置本次迭代完之后的簇的编号,第三列放置上次迭代的簇的编号
result_set = pd.concat([dataSet, pd.DataFrame(clusterAssment)], axis=1,ignore_index = True) #将容器拼接到原数据集上
clusterChanged = True #循环控制因子
while clusterChanged:
clusterChanged = False
for i in range(m): #对所有样本进行循环
dist = distMeas(dataSet.iloc[i, :n-1].values, centroids) #计算当前样本到质心之间的距离
result_set.iloc[i, n] = dist.min( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5084
5084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









