





1.几种梯度下降方法比较
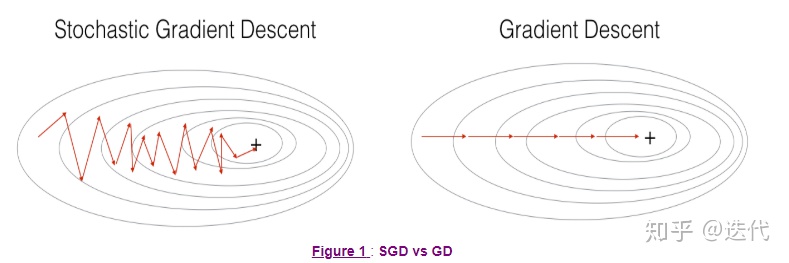
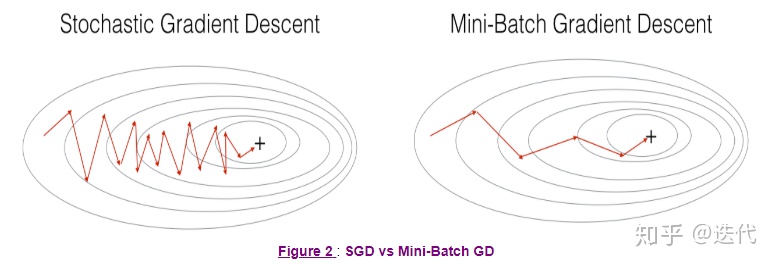
梯度下降、随机梯度下降、小批量梯度下降比较
梯度下降使用全部样本进行一次梯度计算
随机梯度下降使用单个样本进行一次梯度计算
小批量梯度下降使用部分样本进行一次梯度计算
需要设定参数:学习率、小批量梯度下降中的分多少批量m
2.Gradient Descent
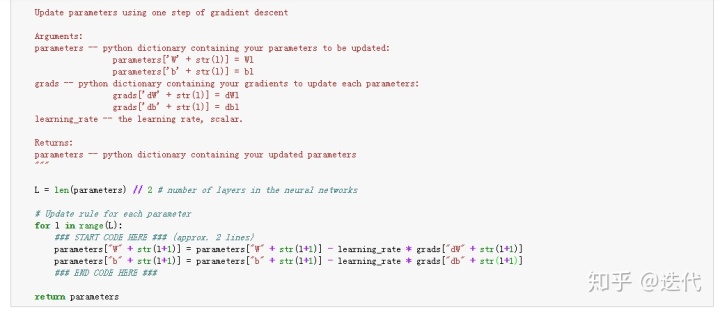
3.Mini-Batch Gradient descent
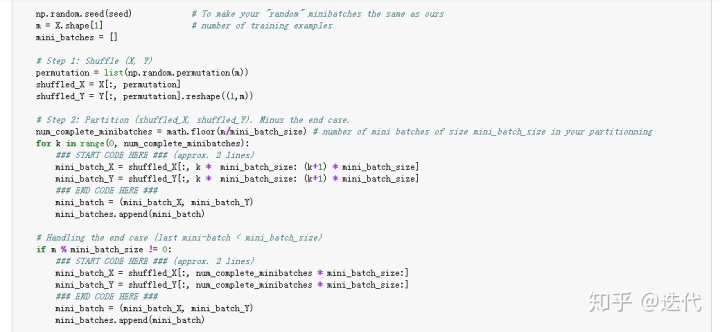
之前的batch都是完整的批量,最后一个batch会有所缺少,故两部分写。
4.Momentum动量
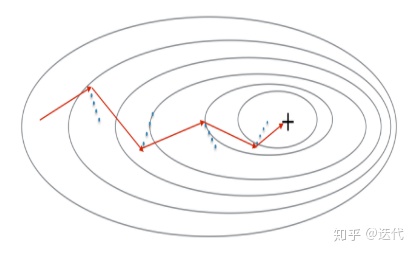
利用动量,减小mini-batch的震荡。
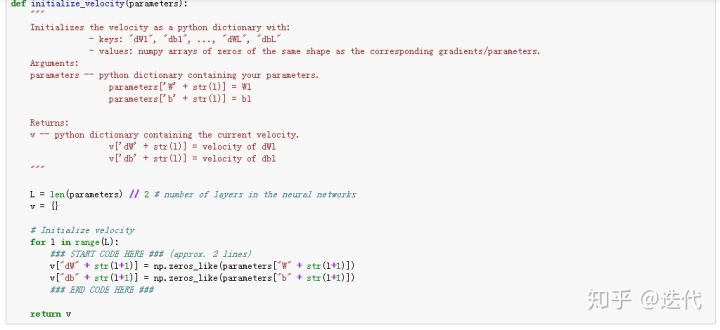
全零初始化速度,维度与w,b一样
更新公式:
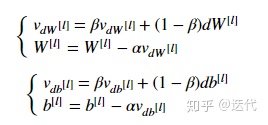
参数更新:
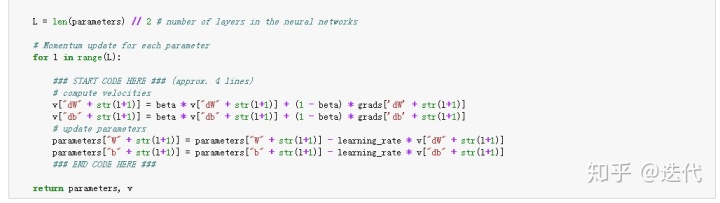
当参数beta=0时就是标准的梯度下降。
beta越大越平滑,越考虑之前的梯度,默认beta=0.9,一般可以考虑0.8-0.999之间。
Momentum考虑过去梯度,以平滑当前梯度,可与随机梯度下降,梯度下降,小批量梯度下降连用。
5.Adam
Adam是最有效的优化算法,结合了Momentum和RMSProp(动量+指数加权平均)。
具体公式:
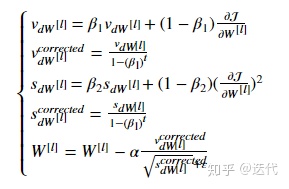
增加了超参数:
参数初始化:

参数更新:

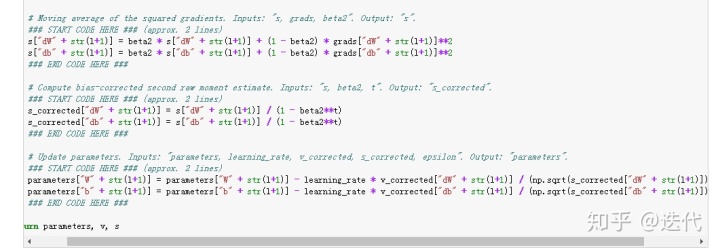
按照前处给的公式编写对应代码即可。
6.测试
梯度下降不需要初始化参数,Momentum和Adam都需要初始化参数。
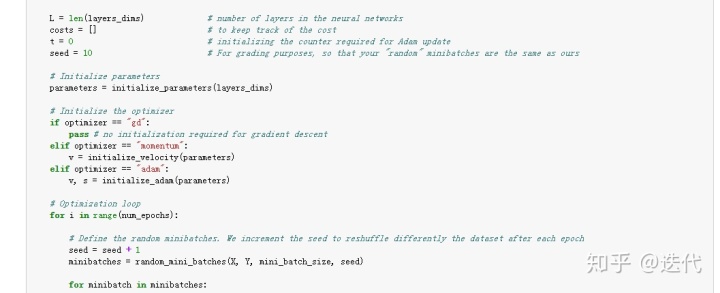


整个modle都是对之前完成函数的调用。
(1)小批量梯度下降
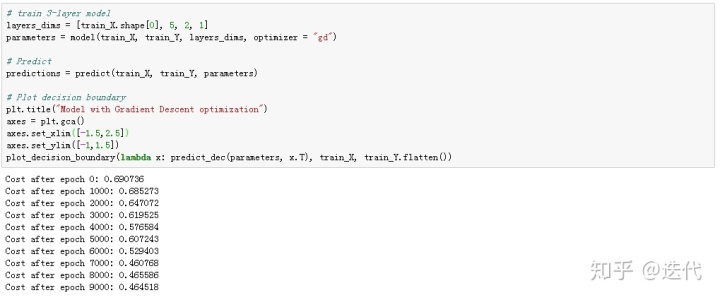
准确率0.797
(2)带动量的小批量梯度下降

准确率0.797
(3)带Adam模型的小批量梯度下降
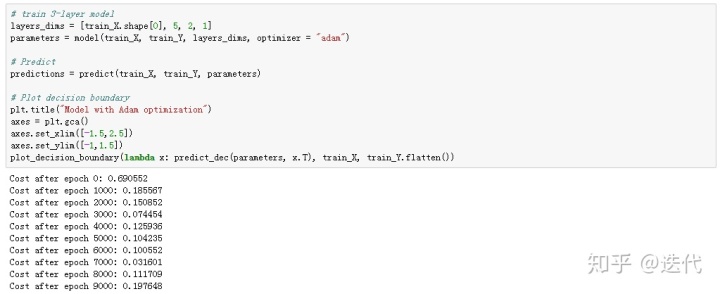
准确率0.94
小结:结果显示GD和Momentum准确率相同,Adam比前两者高很多,一般情况下Momentum的结果应当比GD的要好,但此处数据集过于简单,学习率也较低因此影响不大。Adam结果要远好于GD和Momentum,可能继续训练三者的结果会比较接近,但是也可以发现,Adam比GD、Momentum收敛的更快。















 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









