







吴恩达Deep Learning编程作业 Course2- 改善深层神经网络-第二周作业:优化方法
到目前为止我们一直使用梯度下降算法来进行参数更新,求得最小化成本。在这个作业中我们将学习优化算法,能够节省时间使得我们更快的得到好的结果。
在吴恩达老师的课程中将梯度下降比喻为在山壑中找到最低点,如下图所示:

本次练习需要使用的库函数(一些工具类代码放在文章最后,请自行创建对应文件)
import numpy as np
import matplotlib.pyplot as plt
import scipy.io
import math
import sklearn
import sklearn.datasets
from Week2.Utils.opt_utils import load_params_and_grads, initialize_parameters, forward_propagation, backward_propagation
from Week2.Utils.opt_utils import compute_cost, predict, predict_dec, plot_decision_boundary, load_dataset
from Week2.Utils.testCases_second import *
plt.rcParams['figure.figsize'] = (7.0, 4.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
1. 梯度下降
1.1 批量梯度下降(Batch Gradient Descent,BGD)
梯度下降是机器学习中一种简单的优化方法,是对所有样本进行计算处理,这也被称为批量梯度下降。
优点:
(1)一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
(1)当样本数目 m大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
练习:实现批量梯度下降更新规则。批量梯度下降规则是,对于$l = 1,…L $:
W
[
l
]
=
W
[
l
]
−
α
d
W
[
l
]
W^{[l]} = W^{[l]} - \alpha \text{ } dW^{[l]}
W[l]=W[l]−α dW[l]
b
[
l
]
=
b
[
l
]
−
α
d
b
[
l
]
b^{[l]} = b^{[l]} - \alpha \text{ } db^{[l]}
b[l]=b[l]−α db[l]
其中L是层数,
α
\alpha
α 是学习率。
代码:
def update_parameters_with_gd(parameters, grads, learning_rate):
"""
使用梯度下降算法一次性来更新参数
:param parameters:parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
:param grads:grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
:param learning_rate:学习率
:return:返回更新的参数
"""
L = len(parameters) // 2
for l in range(L):
parameters['W' + str(l + 1)] = parameters['W' + str(l + 1)] - learning_rate * grads['dW' + str(l + 1)]
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)]
return parameters
调用:
if __name__ == "__main__":
parameters, grads, learning_rate = update_parameters_with_gd_test_case()
parameters = update_parameters_with_gd(parameters, grads, learning_rate)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
运行结果:

1.2 随机梯度下降算法(Stochastic Gradient Descent,SGD)
随机梯度下降算法是由批量梯度下降算法演变而来的,只不过随机梯度下降算法每次只处理一个样本,因此随机指的也是用样本中的一个例子来近似所有的样本。
优点:
(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
当mini-batch = 1时就相当于是随机梯度下降算法,接下来实现批量梯度下降算法和随机梯度下降算法的主要代码比较以下(仅写了主要代码):
批量梯度下降算法
X = data_input
Y = labels
parameters = initialize_parameters(layer_dims)
for i in range(0, num_iterations):
#1.前向传播
a, cache = forward_propagation(X, parameters)
#2.计算代价
cost = compute_cost(a, Y)
#3.反向传播
grads = backward_propagation(a, caches, parameters)
#4.更新参数
parameters = update_parameters(parameters, grads)
随机梯度下降算法
X = data_input
Y = labels
parameters = initialize_parameters(layer_dims)
for i in range(0, num_iterations):
for j in range(0, m):
#1.前向传播
a, cache = forward_propagation(X[:, j], parameters)
#2.计算代价
cost = compute_cost(a, Y[:, j])
#3.反向传播
grads = backward_propagation(a, caches, parameters)
#4.更新参数
parameters = update_parameters(parameters, grads)
两个算法的比较示意图:与梯度下降算法相比,随机梯度下降算法一直在“振荡”,并不总是一直向最小值的方向收敛。

**总结:**SGD算法实现一共需要三次循环
1.迭代次数num_iterations
2.m个训练样本
3.更新
(
W
[
1
]
,
b
[
1
]
)
(W^{[1]},b^{[1]})
(W[1],b[1]) 到
(
W
[
L
]
,
b
[
L
]
)
(W^{[L]},b^{[L]})
(W[L],b[L])的参数。
在实践中既不使用一个训练样本来进行参数更新也不使用全部训练样本进行参数更新,通常我们会选一个折中的方法,这样效率会更高。
1.3 小批量梯度下降算法(Mini-Batch Gradient Descent, MBGD)
小批量梯度下降,每次更新时用b个样本,其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是1个样本可能不太准确,用64个128个样本就会比1个样本更准确一些,而且批量的话还是非常可以反映样本的一个分布情况的。
随机梯度下降算法和小样本提速下降算法收敛图比较:

- 梯度下降法、小批量梯度下降法和随机梯度下降法的区别在于执行一个更新步骤所使用的示例数量。
- 调整学习速率超参数 α \alpha α。
- 使用合适的mini-batch,通常它的性能优于梯度下降或随机梯度下降(特别是当训练集很大时)。
接下来我们就分两步实现用训练集(X, Y)构建小批量样本。
1.洗牌:将(X,Y)混合起来,但是要注意X的
i
t
h
i^{th}
ith列对应于y中的
i
t
h
i^{th}
ith标签。如图所示:

2.分区:将打乱的(X, Y)划分为大小为mini_batch_size(这里是64)的小批。注意,训练示例的数量并不总是能被mini_batch_size整除。最后一个迷你批处理可能更小,但是我们不必为此担心。当最后的迷你批处理小于完整的mini_batch_size时,它看起来是这样的:

练习:洗牌的部分吴恩达老师已经帮我们提供了相关代码,接下来我们就根据提示的代码实现分区的部分。
提示:
first_mini_batch_X = shuffled_X[:, 0 : mini_batch_size]
second_mini_batch_X = shuffled_X[:, mini_batch_size : 2 * mini_batch_size]
注意,最后一个迷你批处理的大小可能小于mini_batch_size=64。让 ⌊ s ⌋ \lfloor s \rfloor ⌊s⌋表示 s s s四舍五入到最接近的整数(这是Python中的math.floor(s))。如果总数不能被64整除: m i n i _ b a t c h _ s i z e = ⌊ m m i n i _ b a t c h _ s i z e ⌋ mini\_batch\_size = \lfloor \frac{m}{mini\_batch \_size} \rfloor mini_batch_size=⌊mini_batch_sizem⌋ ,剩下的最后一个 m i n i _ b a t c h _ s i z e = mini\_batch\_size = mini_batch_size=( m − m i n i _ b a t c h _ s i z e × ⌊ m m i n i _ b a t c h _ s i z e ⌋ m-mini_\_batch_\_size \times \lfloor \frac{m}{mini\_batch\_size}\rfloor m−mini_batch_size×⌊mini_batch_sizem⌋)
代码:
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
从(X, Y)创建一个随机的小批量列表
:param X:输入的数据,维数(特征数,样本数)
:param Y:1表示蓝色的点,0表示红色的点,(1,样本数)
:param mini_batch_size:mini_batch大小
:return:mini_batches -- (mini_batch_X, mini_batch_Y)
"""
np.random.seed(seed)
m = X.shape[1]
mini_batches = []
#1.洗牌 随机排列
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation]
#2. 分区
#先算出整数个mini_batch有几个
num_complete_minibatches = math.floor(m / mini_batch_size)
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:, k * mini_batch_size : (k + 1) * mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size : (k + 1) * mini_batch_size]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
#处理不被整除的样本
if m % mini_batch_size != 0:
end = m -mini_batch_size * math.floor(m / mini_batch_size)
mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size:]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches * mini_batch_size:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
调用:
X_assess, Y_assess, mini_batch_size = random_mini_batches_test_case()
mini_batches = random_mini_batches(X_assess, Y_assess, mini_batch_size)
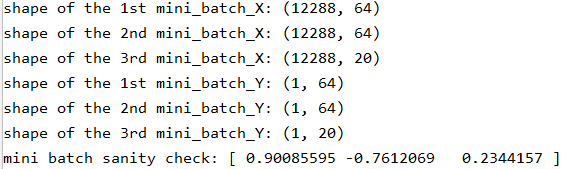
print("shape of the 1st mini_batch_X: " + str(mini_batches[0][0].shape))
print("shape of the 2nd mini_batch_X: " + str(mini_batches[1][0].shape))
print("shape of the 3rd mini_batch_X: " + str(mini_batches[2][0].shape))
print("shape of the 1st mini_batch_Y: " + str(mini_batches[0][1].shape))
print("shape of the 2nd mini_batch_Y: " + str(mini_batches[1][1].shape))
print("shape of the 3rd mini_batch_Y: " + str(mini_batches[2][1].shape))
print("mini batch sanity check: " + str(mini_batches[0][0][0][0:3]))
运行结果:
2. Momentum 动量梯度下降算法
mini_batch梯度下降算法是在计算完一个子集后进行参数更新,因此更新的方向会有一定的偏差,因此小批量梯度下降算法的路径是“振荡”着向收敛的方向,而动量可以减少这些“振荡”。
动量考虑了过去的梯度来平滑更新。我们将在变量
v
v
v中存储以前的梯度的“方向”。形式上,这将是前面步骤梯度的指数加权平均值。你也可以把
v
v
v看作是一个滚下山的球的“速度”,根据山坡的坡度方向来增加速度(和动量)。

代码:
def initialize_velocity(parameters):
"""
初始化velocity
:param parameters:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
:return:
v['dW' + str(l)] = dWl的速度
v['db' + str(l)] = dbl的速度
"""
L = len(parameters) // 2
v = {}
#初始化速度
for l in range(L):
v["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
v["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
return v
调用:
parameters = initialize_velocity_test_case()
v = initialize_velocity(parameters)
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"]))
运行结果:

练习:使用动量实现参数更新。动量更新规则是,对
l
=
1
,
…
L
l = 1,…L
l=1,…L:
{
v
d
W
[
l
]
=
β
v
d
W
[
l
]
+
(
1
−
β
)
d
W
[
l
]
W
[
l
]
=
W
[
l
]
−
α
v
d
W
[
l
]
\begin{cases} v_{dW^{[l]}} = \beta v_{dW^{[l]}} + (1 - \beta) dW^{[l]} \\ W^{[l]} = W^{[l]} - \alpha v_{dW^{[l]}} \end{cases}
{vdW[l]=βvdW[l]+(1−β)dW[l]W[l]=W[l]−αvdW[l]
{
v
d
b
[
l
]
=
β
v
d
b
[
l
]
+
(
1
−
β
)
d
b
[
l
]
b
[
l
]
=
b
[
l
]
−
α
v
d
b
[
l
]
\begin{cases} v_{db^{[l]}} = \beta v_{db^{[l]}} + (1 - \beta) db^{[l]} \\ b^{[l]} = b^{[l]} - \alpha v_{db^{[l]}} \end{cases}
{vdb[l]=βvdb[l]+(1−β)db[l]b[l]=b[l]−αvdb[l]
其中L为层数, β \beta β为动量, α \alpha α为学习率。所有参数都应该存储在参数字典中。注意,迭代器l在for循环中从0开始,第一个参数是 W [ 1 ] W^{[1]} W[1]和 b [ 1 ] b^{[1]} b[1](在上标上是“1”),所以需要在编码时把l移到l+1。
代码:
def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate):
"""
使用动量法更新参数
:param parameters:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
:param grads:
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
:param v:
v['dW' + str(l)] = ...
v['db' + str(l)] = ...
:param beta:动量超参数
:param learning_rate:学习率
:return:
parameters
v
"""
L = len(parameters) // 2
#使用动量方法更新每个参数
for l in range(L):
#1.计算速度
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
#2.更新参数
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return parameters, v
调用:
parameters, grads, v = update_parameters_with_momentum_test_case()
parameters, v = update_parameters_with_momentum(parameters, grads, v, beta=0.9, learning_rate=0.01)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"]))
运行结果:

注意:
- 速度初始化为零,因此,该算法将需要几个迭代来“建立”速度,并开始采取更大的步骤。
- 如果 β = 0 \beta = 0 β=0,那么这就变成了没有动量的标准梯度下降。
如何选择 β \beta β:
- β \beta β的动量越大,更新就越平稳,因为我们对过去的渐变考虑得多。但是如果 β \beta β太大,它也会使更新变得太缓慢。
- β \beta β的通用值范围为0.8到0.999。如果不想调优它, β = 0.9 \beta = 0.9 β=0.9通常是一个合理的默认值。
- 为您的模型调整最佳的 β \beta β可能需要多尝试几个值,以了解在降低成本函数 J J J的值方面什么是最好的。
- 动量考虑过去的梯度来平滑梯度下降的步骤。它可以应用于批量梯度下降法、小批量梯度下降法或随机梯度下降法。
- 我们必须调整动量超参数 β \beta β和学习率 α \alpha α。
3. Adam优化算法
Adam是训练神经网络最有效的优化算法之一。它结合了来自RMSProp和Momentum的思想。
Adam的工作步骤:
1.它计算过去梯度的指数加权平均值,并将其存储在变量
v
v
v(偏差校正前)和
v
c
o
r
r
e
c
t
e
d
v^{corrected}
vcorrected(偏差校正后)中。
2.它计算过去梯度的平方的指数加权平均值,并将其存储在变量
s
s
s(偏差校正前)和
s
c
o
r
r
e
c
t
e
d
s^{corrected}
scorrected(偏差校正后)中。
3.它根据来自“1”和“2”的信息组合的方向更新参数。
更新规则是,对于
l
=
1
,
…
L
l = 1,…L
l=1,…L:
{
v
d
W
[
l
]
=
β
1
v
d
W
[
l
]
+
(
1
−
β
1
)
∂
J
∂
W
[
l
]
v
d
W
[
l
]
c
o
r
r
e
c
t
e
d
=
v
d
W
[
l
]
1
−
(
β
1
)
t
s
d
W
[
l
]
=
β
2
s
d
W
[
l
]
+
(
1
−
β
2
)
(
∂
J
∂
W
[
l
]
)
2
s
d
W
[
l
]
c
o
r
r
e
c
t
e
d
=
s
d
W
[
l
]
1
−
(
β
1
)
t
W
[
l
]
=
W
[
l
]
−
α
v
d
W
[
l
]
c
o
r
r
e
c
t
e
d
s
d
W
[
l
]
c
o
r
r
e
c
t
e
d
+
ε
\begin{cases} v_{dW^{[l]}} = \beta_1 v_{dW^{[l]}} + (1 - \beta_1) \frac{\partial \mathcal{J} }{ \partial W^{[l]} } \\ v^{corrected}_{dW^{[l]}} = \frac{v_{dW^{[l]}}}{1 - (\beta_1)^t} \\ s_{dW^{[l]}} = \beta_2 s_{dW^{[l]}} + (1 - \beta_2) (\frac{\partial \mathcal{J} }{\partial W^{[l]} })^2 \\ s^{corrected}_{dW^{[l]}} = \frac{s_{dW^{[l]}}}{1 - (\beta_1)^t} \\ W^{[l]} = W^{[l]} - \alpha \frac{v^{corrected}_{dW^{[l]}}}{\sqrt{s^{corrected}_{dW^{[l]}}} + \varepsilon} \end{cases}
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧vdW[l]=β1vdW[l]+(1−β1)∂W[l]∂JvdW[l]corrected=1−(β1)tvdW[l]sdW[l]=β2sdW[l]+(1−β2)(∂W[l]∂J)2sdW[l]corrected=1−(β1)tsdW[l]W[l]=W[l]−αsdW[l]corrected+εvdW[l]corrected
变量含义:
- t记录Adam走的步数
- L是层数。
- β 1 \beta_1 β1和 β 2 \beta_2 β2是控制两个指数加权平均数的超参数。
- α \alpha α是学习率。
- ε \varepsilon ε是一个很小的数字,可以避免除数是0。
- 在parameters中存储所有的参数。
练习:初始化Adam变量
v
,
s
v, s
v,s来跟踪过去的信息。
代码:
def initialize_adam(parameters):
"""
初始化v,s
:param parameters:
keys: "dW1", "db1", ..., "dWL", "dbL"
values:与相应的梯度/参数形状相同的零的numpy数组。
:return:v、s
"""
L = len(parameters) // 2
v = {}
s = {}
#初始化v s
for l in range(L):
v["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
v["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
s["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
s["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
return v, s
调用:
parameters = initialize_adam_test_case()
v, s = initialize_adam(parameters)
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"]))
print("s[\"dW1\"] = " + str(s["dW1"]))
print("s[\"db1\"] = " + str(s["db1"]))
print("s[\"dW2\"] = " + str(s["dW2"]))
print("s[\"db2\"] = " + str(s["db2"]))
运行结果:

练习:使用Adam实现参数更新。更新规则是,对于
l
=
1
,
…
L
l = 1,…L
l=1,…L
{
v
W
[
l
]
=
β
1
v
W
[
l
]
+
(
1
−
β
1
)
∂
J
∂
W
[
l
]
v
W
[
l
]
c
o
r
r
e
c
t
e
d
=
v
W
[
l
]
1
−
(
β
1
)
t
s
W
[
l
]
=
β
2
s
W
[
l
]
+
(
1
−
β
2
)
(
∂
J
∂
W
[
l
]
)
2
s
W
[
l
]
c
o
r
r
e
c
t
e
d
=
s
W
[
l
]
1
−
(
β
2
)
t
W
[
l
]
=
W
[
l
]
−
α
v
W
[
l
]
c
o
r
r
e
c
t
e
d
s
W
[
l
]
c
o
r
r
e
c
t
e
d
+
ε
\begin{cases} v_{W^{[l]}} = \beta_1 v_{W^{[l]}} + (1 - \beta_1) \frac{\partial J }{ \partial W^{[l]} } \\ v^{corrected}_{W^{[l]}} = \frac{v_{W^{[l]}}}{1 - (\beta_1)^t} \\ s_{W^{[l]}} = \beta_2 s_{W^{[l]}} + (1 - \beta_2) (\frac{\partial J }{\partial W^{[l]} })^2 \\ s^{corrected}_{W^{[l]}} = \frac{s_{W^{[l]}}}{1 - (\beta_2)^t} \\ W^{[l]} = W^{[l]} - \alpha \frac{v^{corrected}_{W^{[l]}}}{\sqrt{s^{corrected}_{W^{[l]}}}+\varepsilon} \end{cases}
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧vW[l]=β1vW[l]+(1−β1)∂W[l]∂JvW[l]corrected=1−(β1)tvW[l]sW[l]=β2sW[l]+(1−β2)(∂W[l]∂J)2sW[l]corrected=1−(β2)tsW[l]W[l]=W[l]−αsW[l]corrected+εvW[l]corrected
注意,迭代器l在for循环中从0开始,而第一个参数是
W
[
1
]
W^{[1]}
W[1]和
b
[
1
]
b^{[1]}
b[1]。你需要在编码时把l移到l+1。
代码:
def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01, beta1 = 0.9, beta2 = 0.999,epsilon = 1e-8):
"""
使用Adam更新参数
:param parameters:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
:param grads:
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
:param v:第一个梯度的平均移动
:param s:平方梯度的移动平均
:param t:
:param learning_rate:学习率
:param beta1:第一个矩估计的指数衰减超参数
:param beta2:第二个矩阵的指数衰减超参数估计
:param epsilon:防止除数为0
:return:v, s
"""
L = len(parameters) // 2
v_corrected = {}
s_corrected = {}
#对所有参数都更新
for l in range(L):
v["dW" + str(l + 1)] = beta1 * v["dW" + str(l + 1)] + (1 - beta1) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta1 * v["db" + str(l + 1)] + (1 - beta1) * grads['db' + str(l + 1)]
v_corrected["dW" + str(l + 1)] = v["dW" + str(l + 1)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l + 1)] = v["db" + str(l + 1)] / (1 - np.power(beta1, t))
s["dW" + str(l + 1)] = beta2 * s["dW" + str(l + 1)] + (1 - beta2) * np.power(grads['dW' + str(l + 1)], 2)
s["db" + str(l + 1)] = beta2 * s["db" + str(l + 1)] + (1 - beta2) * np.power(grads['db' + str(l + 1)], 2)
s_corrected["dW" + str(l + 1)] = s["dW" + str(l + 1)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l + 1)] = s["db" + str(l + 1)] / (1 - np.power(beta2, t))
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * v_corrected[
"dW" + str(l + 1)] / np.sqrt(s_corrected["dW" + str(l + 1)] + epsilon)
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * v_corrected[
"db" + str(l + 1)] / np.sqrt(s_corrected["db" + str(l + 1)] + epsilon)
return parameters, v, s
调用:
parameters, grads, v, s = update_parameters_with_adam_test_case()
parameters, v, s = update_parameters_with_adam(parameters, grads, v, s, t=2)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
print("v[\"dW1\"] = " + str(v["dW1"]))
print("v[\"db1\"] = " + str(v["db1"]))
print("v[\"dW2\"] = " + str(v["dW2"]))
print("v[\"db2\"] = " + str(v["db2"]))
print("s[\"dW1\"] = " + str(s["dW1"]))
print("s[\"db1\"] = " + str(s["db1"]))
print("s[\"dW2\"] = " + str(s["dW2"]))
print("s[\"db2\"] = " + str(s["db2"]))
运行结果:

现在我们已经实现了三个优化算法了,接下来我们就分别用它们来实现模型,观察它们的不同。
4. 使用不同优化算法的模型
4.1 加载数据
本次使用“moon“数据集。
train_X, train_Y = load_dataset()

4.2 三层模型调用优化算法
我们使用的是前面作业实现的三层神经网络,我们将使用以下三个优化算法:
- Mini-batch Gradient Descent函数实现名:update_parameters_with_gd()
- Mini-batch Momentum函数实现名:initialize_velocity()和update_parameters_with_momentum()
- Mini-batch Adam函数实现名:initialize_adam()和update_parameters_with_adam()
调用优化算法模型代码:
def model(X, Y, layers_dims, optimizer, learning_rate = 0.0007, mini_batch_size = 64, beta = 0.9, beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8, num_epochs = 10000,print_cost = True):
"""
在三层神经网络模型中调用不同的优化算法
:param X:输入的数据集,维数(2, 样本数)
:param Y:真实标签,1表示蓝色,0表示红色
:param layers_dims:没层的特征数
:param optimizer:优化算法名
:param learning_rate:学习率
:param mini_batch_size:mini_batch的大小
:param beta:Momentum算法中使用的参数
:param beta1:Adam中的参数
:param beta2:Adam中的参数
:param epsilon:防止Adam算法中出现除数是0
:param num_epochs:循环次数
:param print_cost:是否每1000次打印代价
:return:parameters更新的参数
"""
#计算模型层数
L = len(layers_dims)
costs = []
t = 0 #Adam中的参数
seed = 10
#初始化参数
parameters = initialize_parameters(layers_dims)
#选择优化方法:
if optimizer == "gd":
pass
elif optimizer == "momentum":
v = initialize_velocity(parameters)
elif optimizer == "adam":
v, s = initialize_adam(parameters)
#优化循环
for i in range(num_epochs):
seed = seed + 1
minibatches = random_mini_batches(X, Y, mini_batch_size, seed)
for minibatch in minibatches:
#1.选择minibatch
minibatch_X, minibatch_Y = minibatch
#2.前向传播
a3, caches = forward_propagation(minibatch_X, parameters)
#3.计算代价
cost = compute_cost(a3, minibatch_Y)
#4.反向传播
grads = backward_propagation(minibatch_X, minibatch_Y, caches)
#更新参数
if optimizer == "gd":
parameters = update_parameters_with_gd(parameters, grads, learning_rate)
elif optimizer == "momentum":
parameters, v = update_parameters_with_momentum(parameters, grads, v, beta, learning_rate)
elif optimizer == "adam":
t = t + 1
parameters, v, s = update_parameters_with_adam(parameters, grads, v, s, t, learning_rate, beta1, beta2, epsilon)
if print_cost and i % 1000 == 0:
print("第%i次迭代后代价为: %f" % (i, cost))
if print_cost and i % 100 == 0:
costs.append(cost)
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('epochs (per 100)')
plt.title("学习率 = " + str(learning_rate))
plt.show()
return parameters
4.21 Mini-batch梯度下降
train_X, train_Y = load_dataset()
layers_dims = [train_X.shape[0], 5, 2, 1]
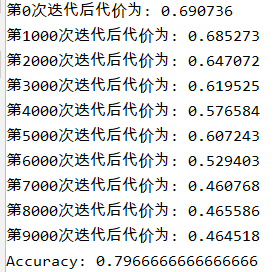
parameters = model(train_X, train_Y, layers_dims, optimizer="gd")
predictions = predict(train_X, train_Y, parameters)
plt.title("Model with Gradient Descent optimization")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1, 1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
运行结果:


4.22 momentum的Mini-batch梯度下降
因为下面的例子过于简单,所以得到的优化算法可能没有表现出很大的优势,在更复杂的问题中表现的更好。
代码:
train_X, train_Y = load_dataset()
layers_dims = [train_X.shape[0], 5, 2, 1]
parameters = model(train_X, train_Y, layers_dims, beta=0.9, optimizer="momentum")
predictions = predict(train_X, train_Y, parameters)
plt.title("Model with Momentum optimization")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1, 1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
运行结果:



4.23 Adam的Mini-batch梯度下降
代码:
layers_dims = [train_X.shape[0], 5, 2, 1]
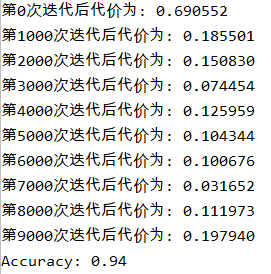
parameters = model(train_X, train_Y, layers_dims, optimizer="adam")
# Predict
predictions = predict(train_X, train_Y, parameters)
# Plot decision boundary
plt.title("Model with Adam optimization")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1, 1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
运行结果:


4.3 总结
| 优化方法 | 准确率 | 代价图形状 |
|---|---|---|
| Gradient method | 79% | 波段较大 |
| Momentum | 79% | 波段较大 |
| Adam | 94% | 波段较小 |
5. 工具代码:
1.opt_utils.py
import numpy as np
import matplotlib.pyplot as plt
import h5py
import scipy.io
import sklearn
import sklearn.datasets
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- sigmoid(x)
"""
s = 1/(1+np.exp(-x))
return s
def relu(x):
"""
Compute the relu of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- relu(x)
"""
s = np.maximum(0,x)
return s
def load_params_and_grads(seed=1):
np.random.seed(seed)
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
dW1 = np.random.randn(2,3)
db1 = np.random.randn(2,1)
dW2 = np.random.randn(3,3)
db2 = np.random.randn(3,1)
return W1, b1, W2, b2, dW1, db1, dW2, db2
def initialize_parameters(layer_dims):
"""
Arguments:
layer_dims -- python array (list) containing the dimensions of each layer in our network
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layer_dims[l], layer_dims[l-1])
b1 -- bias vector of shape (layer_dims[l], 1)
Wl -- weight matrix of shape (layer_dims[l-1], layer_dims[l])
bl -- bias vector of shape (1, layer_dims[l])
Tips:
- For example: the layer_dims for the "Planar Data classification model" would have been [2,2,1].
This means W1's shape was (2,2), b1 was (1,2), W2 was (2,1) and b2 was (1,1). Now you have to generalize it!
- In the for loop, use parameters['W' + str(l)] to access Wl, where l is the iterative integer.
"""
np.random.seed(3)
parameters = {}
L = len(layer_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1])*np.sqrt(2 / layer_dims[l-1])
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert(parameters['W' + str(l)].shape == layer_dims[l], layer_dims[l-1])
assert(parameters['b' + str(l)].shape == layer_dims[l], 1)
return parameters
def compute_cost(a3, Y):
"""
Implement the cost function
Arguments:
a3 -- post-activation, output of forward propagation
Y -- "true" labels vector, same shape as a3
Returns:
cost - value of the cost function
"""
m = Y.shape[1]
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
cost = 1./m * np.sum(logprobs)
return cost
def forward_propagation(X, parameters):
"""
Implements the forward propagation (and computes the loss) presented in Figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape ()
b1 -- bias vector of shape ()
W2 -- weight matrix of shape ()
b2 -- bias vector of shape ()
W3 -- weight matrix of shape ()
b3 -- bias vector of shape ()
Returns:
loss -- the loss function (vanilla logistic loss)
"""
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
z1 = np.dot(W1, X) + b1
a1 = relu(z1)
z2 = np.dot(W2, a1) + b2
a2 = relu(z2)
z3 = np.dot(W3, a2) + b3
a3 = sigmoid(z3)
cache = (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3)
return a3, cache
def backward_propagation(X, Y, cache):
"""
Implement the backward propagation presented in figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
cache -- cache output from forward_propagation()
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) = cache
dz3 = 1./m * (a3 - Y)
dW3 = np.dot(dz3, a2.T)
db3 = np.sum(dz3, axis=1, keepdims = True)
da2 = np.dot(W3.T, dz3)
dz2 = np.multiply(da2, np.int64(a2 > 0))
dW2 = np.dot(dz2, a1.T)
db2 = np.sum(dz2, axis=1, keepdims = True)
da1 = np.dot(W2.T, dz2)
dz1 = np.multiply(da1, np.int64(a1 > 0))
dW1 = np.dot(dz1, X.T)
db1 = np.sum(dz1, axis=1, keepdims = True)
gradients = {"dz3": dz3, "dW3": dW3, "db3": db3,
"da2": da2, "dz2": dz2, "dW2": dW2, "db2": db2,
"da1": da1, "dz1": dz1, "dW1": dW1, "db1": db1}
return gradients
def predict(X, y, parameters):
"""
This function is used to predict the results of a n-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
p = np.zeros((1,m), dtype = np.int)
# Forward propagation
a3, caches = forward_propagation(X, parameters)
# convert probas to 0/1 predictions
for i in range(0, a3.shape[1]):
if a3[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
# print results
#print ("predictions: " + str(p[0,:]))
#print ("true labels: " + str(y[0,:]))
print("Accuracy: " + str(np.mean((p[0,:] == y[0,:]))))
return p
def load_2D_dataset():
data = scipy.io.loadmat('datasets/data.mat')
train_X = data['X'].T
train_Y = data['y'].T
test_X = data['Xval'].T
test_Y = data['yval'].T
plt.scatter(train_X[0, :], train_X[1, :], c=train_Y, s=40, cmap=plt.cm.Spectral);
return train_X, train_Y, test_X, test_Y
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=np.squeeze(y), cmap=plt.cm.Spectral)
plt.show()
def predict_dec(parameters, X):
"""
Used for plotting decision boundary.
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (m, K)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Predict using forward propagation and a classification threshold of 0.5
a3, cache = forward_propagation(X, parameters)
predictions = (a3 > 0.5)
return predictions
def load_dataset():
np.random.seed(3)
train_X, train_Y = sklearn.datasets.make_moons(n_samples=300, noise=.2) #300 #0.2
# Visualize the data
plt.scatter(train_X[:, 0], train_X[:, 1], c=train_Y, s=40, cmap=plt.cm.Spectral)
train_X = train_X.T
train_Y = train_Y.reshape((1, train_Y.shape[0]))
return train_X, train_Y
2.testCases_second.py
import numpy as np
def update_parameters_with_gd_test_case():
np.random.seed(1)
learning_rate = 0.01
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
dW1 = np.random.randn(2,3)
db1 = np.random.randn(2,1)
dW2 = np.random.randn(3,3)
db2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
return parameters, grads, learning_rate
"""
def update_parameters_with_sgd_checker(function, inputs, outputs):
if function(inputs) == outputs:
print("Correct")
else:
print("Incorrect")
"""
def random_mini_batches_test_case():
np.random.seed(1)
mini_batch_size = 64
X = np.random.randn(12288, 148)
Y = np.random.randn(1, 148) < 0.5
return X, Y, mini_batch_size
def initialize_velocity_test_case():
np.random.seed(1)
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
def update_parameters_with_momentum_test_case():
np.random.seed(1)
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
dW1 = np.random.randn(2,3)
db1 = np.random.randn(2,1)
dW2 = np.random.randn(3,3)
db2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
v = {'dW1': np.array([[ 0., 0., 0.],
[ 0., 0., 0.]]), 'dW2': np.array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]]), 'db1': np.array([[ 0.],
[ 0.]]), 'db2': np.array([[ 0.],
[ 0.],
[ 0.]])}
return parameters, grads, v
def initialize_adam_test_case():
np.random.seed(1)
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
def update_parameters_with_adam_test_case():
np.random.seed(1)
v, s = ({'dW1': np.array([[ 0., 0., 0.],
[ 0., 0., 0.]]), 'dW2': np.array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]]), 'db1': np.array([[ 0.],
[ 0.]]), 'db2': np.array([[ 0.],
[ 0.],
[ 0.]])}, {'dW1': np.array([[ 0., 0., 0.],
[ 0., 0., 0.]]), 'dW2': np.array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]]), 'db1': np.array([[ 0.],
[ 0.]]), 'db2': np.array([[ 0.],
[ 0.],
[ 0.]])})
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
dW1 = np.random.randn(2,3)
db1 = np.random.randn(2,1)
dW2 = np.random.randn(3,3)
db2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
return parameters, grads, v, s















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









