





2020/07/29

最先进的(SOTA)深度学习模型具有大量的内存占用空间。许多GPU没有足够的VRAM来训练它们。在本文中,我们确定了哪些GPU可以训练最新的网络而不会引发内存错误。我们还将基准每个GPU的训练性能。
TLDR:
截至2020年2月,以下GPU可以训练所有SOTA语言和图像模型:
- RTX 8000:48 GB VRAM,约5500美元。
- RTX 6000:24 GB VRAM,〜$ 4,000。
- Titan RTX:24 GB VRAM,约2,500美元。
以下GPU可以训练大多数(但不是全部)SOTA模型:
- RTX 2080 Ti:11 GB VRAM,约1,150美元。*
- GTX 1080 Ti:11 GB VRAM,约$ 800翻新。*
- RTX 2080:8 GB VRAM,约720美元。*
- RTX 2070:8 GB VRAM,约500美元。*
以下GPU不适合用于训练SOTA模型:
- RTX 2060:6 GB VRAM,约359美元。
*在这些GPU上进行训练需要小批量,因此期望模型精度较低,因为模型的能量分布近似会受到影响。
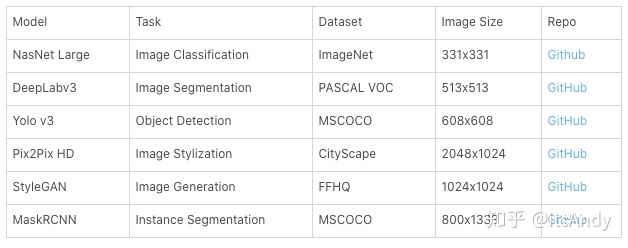
Image models
Maximum batch size before running out of memory

*The GPU does not have enough memory to run the model.
Performance, measured in images processed per second

*The GPU does not have enough memory to run the model.
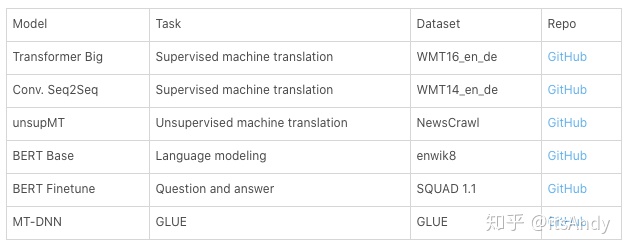
Language models
Maximum batch size before running out of memory

*The GPU does not have enough memory to run the model.
Performance

*The GPU does not have enough memory to run the model.
结果由Quadro RTX 8000标准化
Results normalized by Quadro RTX 8000
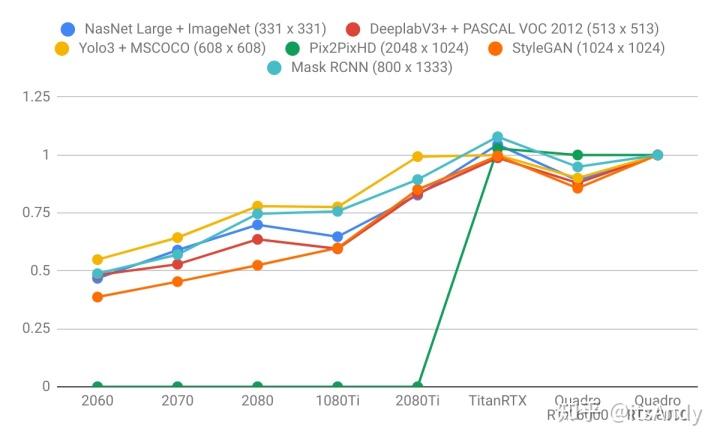
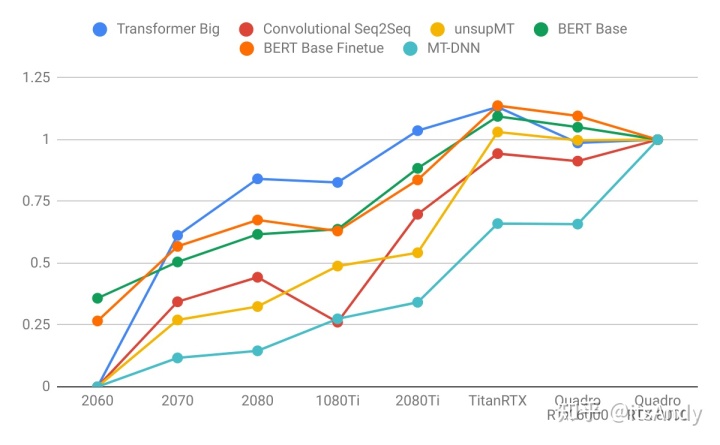
图2.针对Quadro RTX 8000标准化的训练吞吐量。
上:image models。下:Language models.。
结论
- 语言模型比图像模型受益于更大的GPU内存。注意右图比左图陡。这表明语言模型受内存限制更大,而图像模型受计算限制更大。
- 具有较高VRAM的GPU具有更好的性能,因为使用较大的批处理大小有助于使CUDA内核饱和。
- 具有更高VRAM的GPU可按比例实现更大的批处理大小。信封后的计算得出合理的结果:具有24 GB VRAM的GPU可以比具有8 GB VRAM的GPU容纳大约3倍的批处理。
- 对于长序列,语言模型不成比例地占用大量内存,因为注意力集中在序列长度上。
GPU建议
- RTX 2060(6 GB):如果您想在业余时间探索深度学习。
- RTX 2070或2080(8 GB):如果您认真研究深度学习,但GPU预算为$ 600-800。八GB的VRAM可适合大多数型号。
- RTX 2080 Ti(11 GB):如果您认真研究深度学习并且您的GPU预算约为1200美元。RTX 2080 Ti比RTX 2080快40%。
- Titan RTX和Quadro RTX 6000(24 GB):如果您正在广泛使用SOTA模型,但没有足够的预算用于RTX 8000提供的面向未来的证明。
- Quadro RTX 8000(48 GB):您正在投资未来,甚至可能有幸在2020年研究SOTA深度学习。
Footnotes
Image Models
Language Models
老规矩还是给大家介绍一下租用GPU做实验的方法,我们是在智星云租用的GPU,使用体验很好。具体大家可以参考:智星云官网: http://www.ai-galaxy.cn/,淘宝店:https://shop36573300.taobao.com/公众号: 智星AI,

参考文献:
https://lambdalabs.com/blog/choosing-a-gpu-for-deep-learning/















 1715
1715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









