








引言

OCR 的全称是光学字符识别,如其名,主要利用了图像信息进行识别。然而人类在识字的时候,除了眼睛看,还会自动理解文字背后的含义。例如上面这个流传甚广的“测字”游戏,你一定不会说认不出来,而是给出“老虎”或者“考虑”这样的答案。
根据贝叶斯误差的相关理论,只有图像信息的数据集,和既有图像信息、又有语义信息的数据集相比,前者的贝叶斯误差应当不小于后者(因为后者包含了前者所没有的特征)。因此,我们希望能够利用上语义信息,并认为它一定能够提升OCR的准确率。
利用语义信息的方式有多种,可以直接训练多模态的识别模型[1][2],也是目前场景文字识别领域的热门方向。还有一种原始直接的方式就是在识别之后进行纠错,就是本项目的主要内容。
纠错的两个关键问题
纠错的两个关键问题分别为:语言模型,字形的相似度度量。语言模型给出当前识别结果最可能的几个真实值,字形的相似度度量给出真实值识别为当前结果的可能性。
可以用信道噪声模型表征这一问题[3][4]:

实际上就是HMM的思想,语言模型对应Input出现的概率P(I),字形的相似度度量对应Input 增加noise后转换为Output的概率P(O|I)。
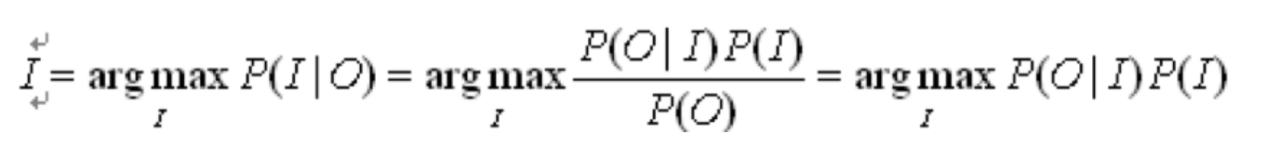
在近期的实践当中一般分开处理这两个问题。首先利用语言模型给出使P(I)最大的n个Input,然后再找到其中使P(O|I)最大的Input。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









