






前言:
如今的高速网络极大促进了信息的展示方式,高清图片,视频等成就了我们的视听盛宴。但是,我们获取到的图片或者视频可能是被压缩过的,所以总体上还是有点小瑕疵,今天呢,我给大家带来一篇使用Python爬取著名高清图片网站500px图片的文章,这个爬虫具有搜索功能哦。让你感受摄影魅力!
通过这篇文章的学习,你将学会:
- 使用requests库发起请求
- 将requests请求结果转化为json类型
- 提取json类型的数据
- 写入图像类型文件
Python环境搭建可以参考这里
蓝色衬衫:Python第一步---环境搭建zhuanlan.zhihu.com
整体流程图
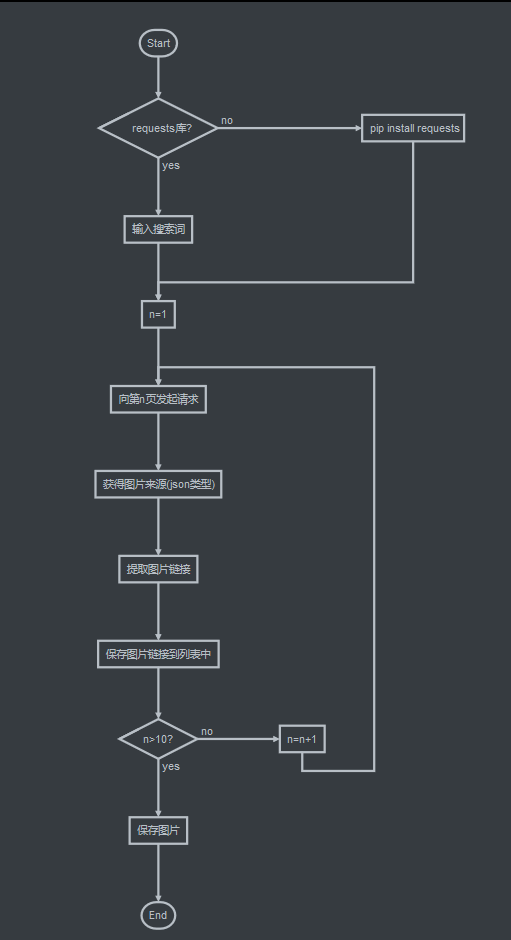
实战:
- 安装使用 pip 工具 安装requests库
pip install requests2.导入 requests库
import requests3. json数据类型介绍
json是一种数据存储方式,它可以看做字典和列表的组合,列表可以是字典的值,字典可以是列表中的项目 一下例子可能会让你更容易理解
# json是一种数据存储方式,类python的字典,例如下面
json_example={"name":"Mike",
"hoobby":["Ball","game"],
"address":[{"city":"New York"},{"street":"Center Street"}]
}
# 上面的json_example就是一个简单的json数据的实例
# 可以看到,json类型文件就是字典和列表的组合,列表可以是字典的值,字典
# 下面是获取指定数据的方法
name=json_example['name']
print(name)
# 输出: Mike
# 请注意下面的 0,这个0代表 adrress 这个 键 对应的值是一个列表
# 0代表列表的第一项,而第一项的键 city 所对于的值是New York,所以这样子可以获得city
city=json_example['address'][0]['city']
print(city)
# 输出 New York
# 下面演示在不知道键名的情况下遍历json数据中所有内容
for i in json_example:
print(i)
# 输出:hoobby address爬取图片完整代码
import requests
# 接受搜索
key=input("请输入关键词:")
pn=input("请输入要爬取的页数:")
# input获取的输入是字符串格式,而我们想要的页数是整数,所以使用 int() 函数进行类型转换
# pn代表爬取的图片总页数
pn=int(pn)
print('。。。。。。开始爬取。。。。。。')
# 定义一个列表来存放图片地址
image_list=[]
# 利用循环,依次访问不同页码
for i in range(1,pn+1):
print("。。。。。。正在提取第{}页。。。。。。".format(i))
# 这个url是我通过浏览器开发者工具抓取的,对初学者来说难度有点大,建议直接使用就行
# 传递页数和关键词即可使用
# 如果想知道怎么获取,可以私信我,或者在评论区留言,我教你。
url='https://api.500px.com/v1/photos/search?type=photos&term={}&image_size%5B%5D=1&image_size%5B%5D=2&image_size%5B%5D=32&image_size%5B%5D=31&image_size%5B%5D=33&image_size%5B%5D=34&image_size%5B%5D=35&image_size%5B%5D=36&image_size%5B%5D=2048&image_size%5B%5D=4&image_size%5B%5D=14&include_states=true&formats=jpeg%2Clytro&include_tags=true&exclude_nude=true&page={}&rpp=50'.format(key,i)
# 通过requests库获的get方法访问图片所在页的地址
# requests.get(url).json()表示将获得的访问结果转化为json类型
image_json=requests.get(url).json()
# print(requests.get(url).text)
# 取消上面这句代码的注释,再仔细看看json实例介绍,你就知道下面为什么这么写了
data=image_json.get('photos')
for i in data:
image_url=i.get('images')[8].get('url')
# 把图片地址添加到之前列表中
image_list.append(image_url)
# 定义一个变量来计算下载成功的图片个数,并且以它命名图片
count=0
for image in image_list:
print("正在下载第{}张图片!".format(count+1))
image_content=requests.get(image).content
# wb表示以二进制的方式写入文件,w表示覆盖写,即创建新文件,或者覆盖之前同名的文件
# b表示二进制方式写入,图片,视频等文件是二进制文件
# "{}.jpg".format(count) 表示文件名,count是变量,下载过程中,文件名为:1.jpg , 2.jpg ...
with open("{}.jpg".format(count),"wb") as f:
f.write(image_content)
# 每成功下载一张图片,count加1
count=count+1
print("成功下载第{}张图片!".format(count))
print("全部图片下载完毕,图片路径与当前文件相同!")爬取过程图片:
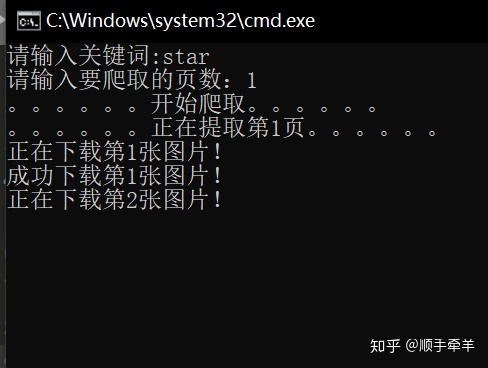


写在最后:
希望大家通过本文掌握前文提到的几个技能,有问题欢迎在评论区留言或者私信我















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









