







PostgreSQL中如果查询需要连接两个或更多表,在所有扫描单个表的可能计划都被找到后,连接计划将会被考虑。和很多数据库一样,可供选择的三种表连接方式为:nested loop join、merge join、hash join。
nested loop join:
对左表中找到的每一行都要扫描右表一次。这种策略最容易实现但是可能非常耗时(不过,如果右表可以通过索引扫描,这将是一个不错的策略。因为可以用左表当前行的值来作为右表上索引扫描的键)。
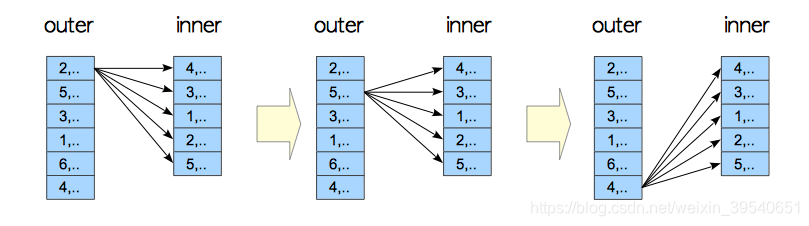
merge join:
在连接开始之前,每一个表都按照连接的列排好序。然后两个表会被并行扫描,匹配的行被整合成连接行。由于这种连接中每个表只被扫描一次。它所要求的排序可以通过一个显式的排序步骤得到,或使用一个连接键上的索引按适当顺序扫描关系得到。
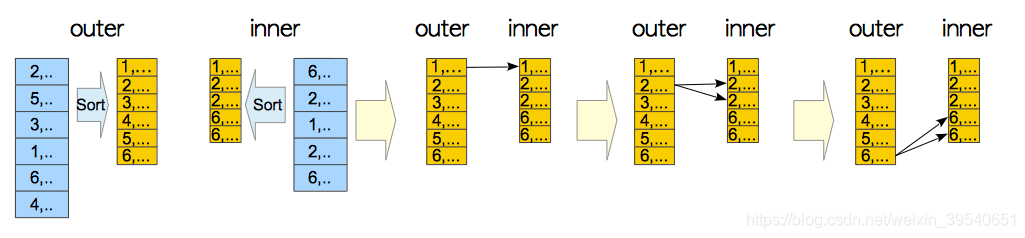
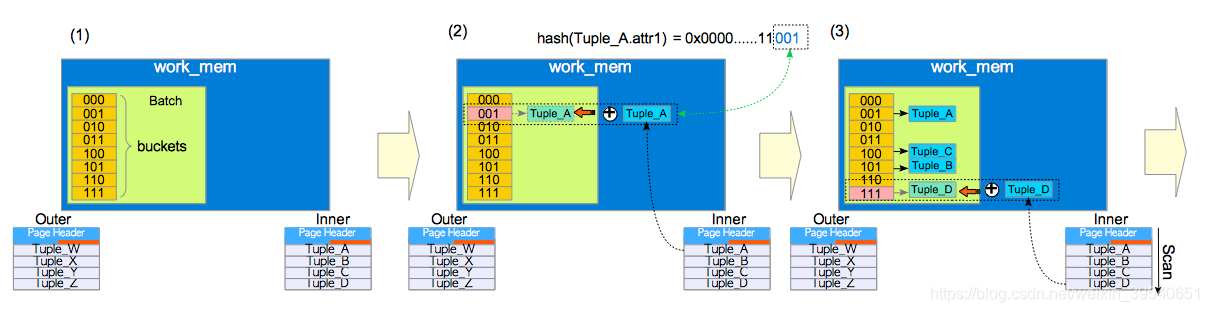
hash join:
右表会先被扫描并且被载入到一个哈希表,使用连接列作为哈希键。接下来左表被扫描,扫描中找到的每一行的连接属性值被用作哈希键在哈希表中查找匹配的行。
当查询涉及两个以上的表时,最终结果必须由一个连接步骤树构成,每个连接步骤有两个输入。规划器会检查不同可能的连接序列来找到代价最小的那一个。
例子:
建表:
bill@bill=>create table t1(id int,info text);
CREATE TABLE
bill@bill=>create table t2(id int,info text);
CREATE TABLE
bill@bill=>insert into t2 select generate_series(1,100000),'bill'||generate_series(1,100000);
INSERT 0 100000
bill@bill=>insert into t1 select generate_series(1,100000),'bill'||generate_series(1,100000);
INSERT 0 100000
–nested loop join:
nl连接大致过程为:1、t2表进行扫描, 过滤条件info = ‘bill’;2、t2表根据过滤条件输出的中间结果, 每一条中间结果, t1表都根据索引idx_t1_id扫一遍, 过滤条件id= t2.id。
bill@bill=>explain select * from t2 join t1 on (t1.id=t2.id) where t2.info='bill';
QUERY PLAN
---------------------------------------------------------------------------
Nested Loop (cost=0.29..1793.92 rows=1 width=26)
-> Seq Scan on t2 (cost=0.00..1791.00 rows=1 width=13)
Filter: (info = 'bill'::text)
-> Index Scan using idx_t1_id on t1 (cost=0.29..2.91 rows=1 width=13)
Index Cond: (id = t2.id)
(5 rows)
–merge join:
merge join的两张表需要按照连接列排序,因为这里用到了索引,所以没有排序过程;
相较于nl连接,merge join不需要多次扫描,两个表都只扫描一次。
bill@bill=>explain select * from t2 join t1 on (t1.id=t2.id) ;
QUERY PLAN
-----------------------------------------------------------------------------------
Merge Join (cost=0.69..6300.71 rows=100000 width=26)
Merge Cond: (t2.id = t1.id)
-> Index Scan using idx_t2_id on t2 (cost=0.29..2400.39 rows=100000 width=13)
-> Index Scan using idx_t1_id on t1 (cost=0.29..2400.39 rows=100000 width=13)
(4 rows)
如果没有索引,则需要先进行排序,则代价会很大。
bill@bill=>explain select * from t2 join t1 on (t1.id=t2.id);
QUERY PLAN
-----------------------------------------------------------------------
Merge Join (cost=19691.64..21691.64 rows=100000 width=26)
Merge Cond: (t2.id = t1.id)
-> Sort (cost=9845.82..10095.82 rows=100000 width=13)
Sort Key: t2.id
-> Seq Scan on t2 (cost=0.00..1541.00 rows=100000 width=13)
-> Sort (cost=9845.82..10095.82 rows=100000 width=13)
Sort Key: t1.id
-> Seq Scan on t1 (cost=0.00..1541.00 rows=100000 width=13)
(8 rows)
–hash join
hash join过程:
1、首先扫描t2表, 过滤条件是t2.id between 1 and 1000, 这里由于t2上id有索引, 所以是走的index scan, 扫描后的结果放到一个Hash表中. Hash key就是两个表关联的列, 这里也就是id列;
2、然后扫描t1表, 扫描到的ID列的值用于去匹配Hash表的KEY值, 匹配到则输出。
bill@bill=>explain select * from t1 join t2 on (t1.info=t2.info) where t2.id between 1 and 1000;
QUERY PLAN
------------------------------------------------------------------------------------
Hash Join (cost=41.95..1967.63 rows=968 width=26)
Hash Cond: (t1.info = t2.info)
-> Seq Scan on t1 (cost=0.00..1541.00 rows=100000 width=13)
-> Hash (cost=29.85..29.85 rows=968 width=13)
-> Index Scan using idx_t2_id on t2 (cost=0.29..29.85 rows=968 width=13)
Index Cond: ((id >= 1) AND (id <= 1000))
(6 rows)
总结:
hash join和merge join被关联的两个表都只扫描一次, nested loop join则被关联的表其中一个扫描一次, (如果前一个表的扫描结果有多行输出)另一个扫描多次。
参考资料:
https://www.postgresql.org/docs/devel/planner-optimizer.html
http://www.interdb.jp/pg/pgsql03.html#_3.5.

















 2209
2209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









