






书接上回:
Tao:Python处理数据常用方法(pandas版)2zhuanlan.zhihu.com
本文为我日常工作中常用功能的代码块,可以满足绝大部分文本数据处理的需求。
首先导入常用的包
import pandas as pd本文假设所使用的excel文件目录为 C:/Users/Administrator/Desktop
名称为 test.xlsx
df 为 定义好的Dataframe格式数据
27 保留(YYYY-MM-DD HH:MM:SS)格式中的日期,排除时间
df['时间']=pd.to_datetime(df['时间']).dt.normalize() 源数据及数据格式:
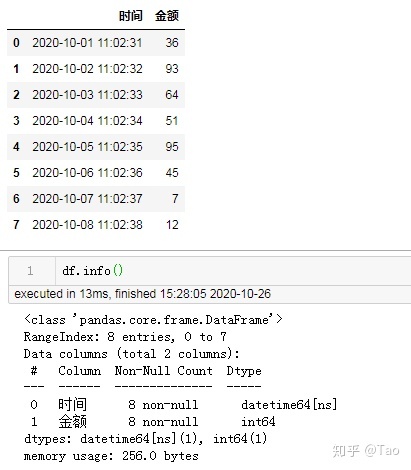
修改后格式:
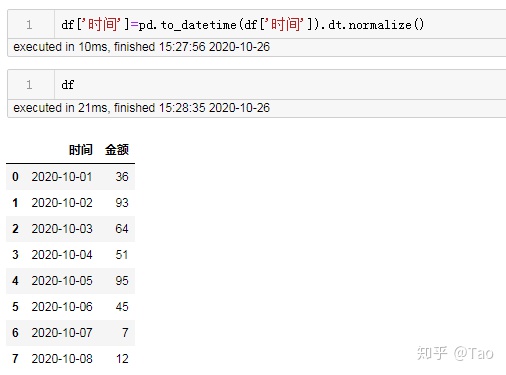
28 保留一列中值为数字的行
df[df.金额.apply(lambda x: str(x).isnumeric())]源数据:
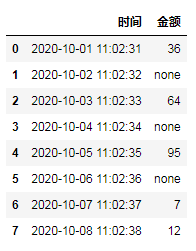
修改后:
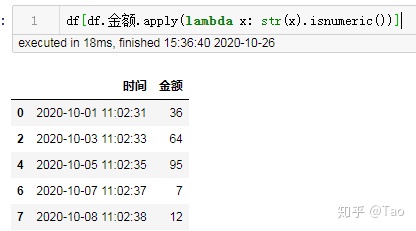
29 将存中文数据的dataframe保存到csv中并不乱码
df.to_csv(r'C:/Users/Administrator/Desktop/test.csv',index=False,encoding='utf_8_sig')源数据:
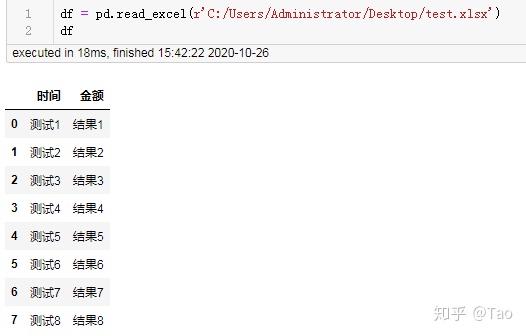
导出后:

添加encoding='utf_8_sig'后:

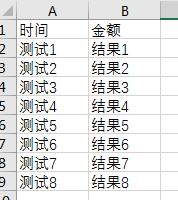
可正常显示中文
30 按照指定字符分列
df = df.drop('A', axis=1).join(df['A'].str.split('+', expand=True).reset_index(drop=True))源数据:

分列后:
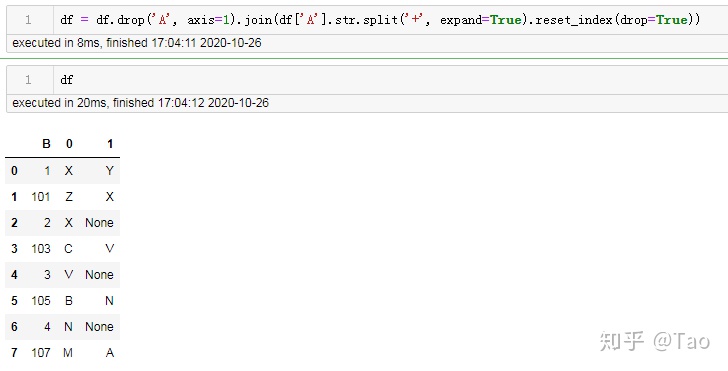
分列后表头的顺序会变,记得调整顺序和修改列名
31 将dataframe保存至csv文件中,并保持中文
df.to_csv(r'C:UsersAdministratorDesktop目标文件.csv',encoding='utf_8_sig')先创建一个dataframe:
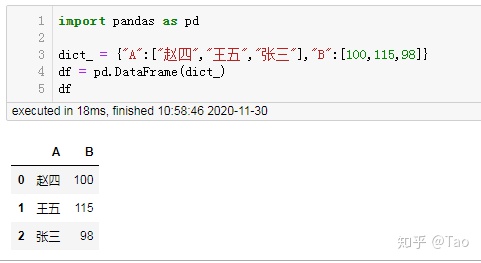
如果直接将其保存成csv,中文会变成乱码:
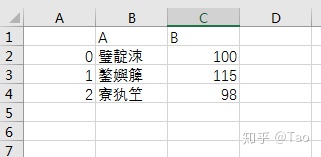
加上 encoding='utf_8_sig' 参数后,中文显示正常


32 将其他格式的数值转化为日期
df['日期']=pd.to_datetime(df['日期'],format="%Y%m%d")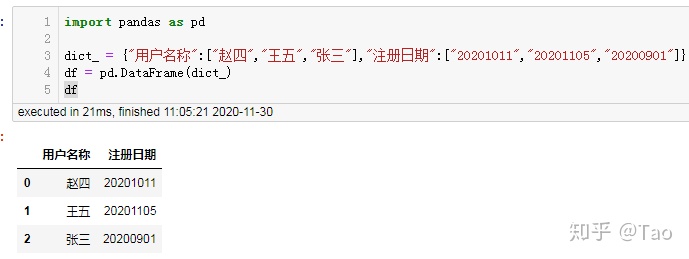
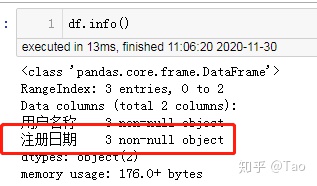
此时注册日期字段为字符串格式
使用to_datetime()方法:

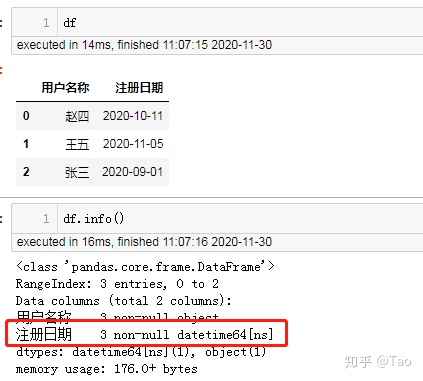
成功将其转化为日期格式
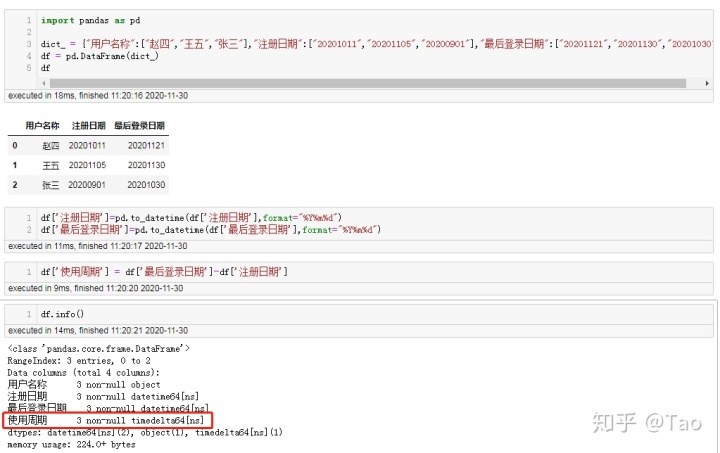
33 将timedelta格式日期转化为数字
df['使用周期'] = df['使用周期'].map(lambda x: x.days)参考上一个例子,除了注册日期外我又加了最后登录日期,两个日期之差即为用户的使用周期
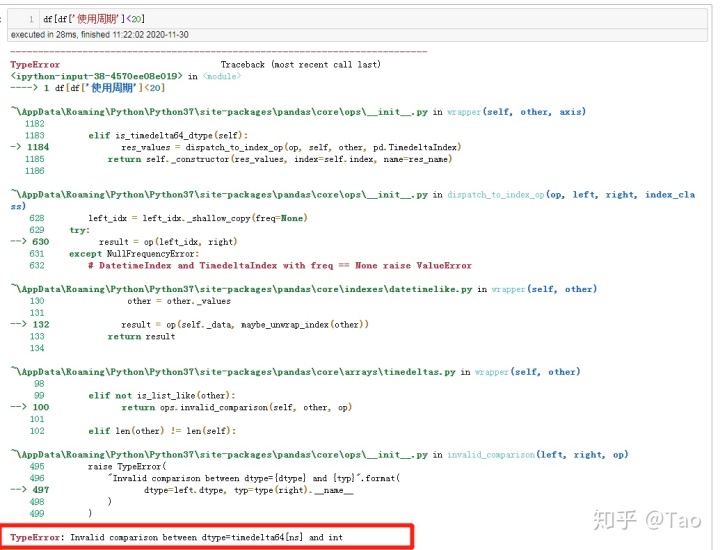
这时候 使用周期 这一列的数据格式为 timedelta64 ,无法直接和数字做比较
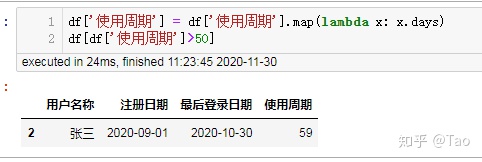
使用timedelta模块自带的days属性可以获得数值型的天数
34 在DataFrame的指定位置插入指定的一列
DataFrame.insert(loc,column,value,allow_duplicates=False)
loc:想要插入的位置
column:插入的列的列名
value:插入的列的值
allow_duplicates:是否允许重复插入,默认为否现在有两个dataframe:
第一个login_date:
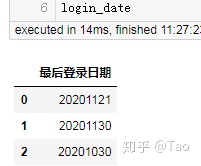
第二个df:
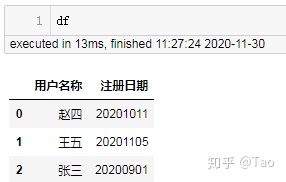
现在讲login_date插入到df的第二列中:
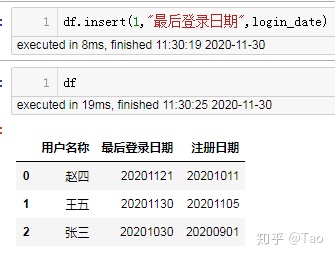
注意第二列的索引是1
这篇先更这么多吧,点赞破20开始下一期~















 3334
3334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









