





作者:蓝师傅_Android
(文章很长,不想看过程的朋友可以直接到最后看总结)这次来面试的是一个有着5年工作经验的小伙,截取了一段对话如下:
面试官:我看你写到Glide,为什么用Glide,而不选择其它图片加载框架?
小伙:Glide 使用简单,链式调用,很方便,一直用这个。
面试官:有看过它的源码吗?跟其它图片框架相比有哪些优势?
小伙:没有,只是在项目中使用而已~
面试官:假如现在不让你用开源库,需要你自己写一个图片加载框架,你会考虑哪些方面的问题,说说大概的思路。
小伙:额~,压缩吧。
面试官:还有吗?
小伙:额~,这个没写过。
说到图片加载框架,大家最熟悉的莫过于Glide了,但我却不推荐简历上写熟悉Glide,除非你熟读它的源码,或者参与Glide的开发和维护。
在一般面试中,遇到图片加载问题的频率一般不会太低,只是问法会有一些差异,例如:
- 简历上写Glide,那么会问一下Glide的设计,以及跟其它同类框架的对比 ;
- 假如让你写一个图片加载框架,说说思路;
- 给一个图片加载的场景,比如网络加载一张或多张大图,你会怎么做;
带着问题进入正文~
一、谈谈Glide
1.1 Glide 使用有多简单?
Glide由于其口碑好,很多开发者直接在项目中使用,使用方法相当简单
github.com/bumptech/gl…
1、添加依赖:
implementation 'com.github.bumptech.glide:glide:4.10.0'annotationProcessor 'com.github.bumptech.glide:compiler:4.10.02、添加网络权限
3、一句代码加载图片到ImageView
Glide.with(this).load(imgUrl).into(mIv1);进阶一点的用法,参数设置
RequestOptions options = new RequestOptions() .placeholder(R.drawable.ic_launcher_background) .error(R.mipmap.ic_launcher) .diskCacheStrategy(DiskCacheStrategy.NONE) .override(200, 100); Glide.with(this) .load(imgUrl) .apply(options) .into(mIv2);使用Glide加载图片如此简单,这让很多开发者省下自己处理图片的时间,图片加载工作全部交给Glide来就完事,同时,很容易就把图片处理的相关知识点忘掉。
1.2 为什么用Glide?
从前段时间面试的情况,我发现了这个现象:简历上写熟悉Glide的,基本都是熟悉使用方法,很多3年-6年工作经验,除了说Glide使用方便,不清楚Glide跟其他图片框架如Fresco的对比有哪些优缺点。
首先,当下流行的图片加载框架有那么几个,可以拿 Glide 跟Fresco对比,例如这些:
Glide:
- 多种图片格式的缓存,适用于更多的内容表现形式(如Gif、WebP、缩略图、Video)
- 生命周期集成(根据Activity或者Fragment的生命周期管理图片加载请求)
- 高效处理Bitmap(bitmap的复用和主动回收,减少系统回收压力)
- 高效的缓存策略,灵活(Picasso只会缓存原始尺寸的图片,Glide缓存的是多种规格),加载速度快且内存开销小(默认Bitmap格式的不同,使得内存开销是Picasso的一半)
Fresco:
- 最大的优势在于5.0以下(最低2.3)的bitmap加载。在5.0以下系统,Fresco将图片放到一个特别的内存区域(Ashmem区)
- 大大减少OOM(在更底层的Native层对OOM进行处理,图片将不再占用App的内存)
- 适用于需要高性能加载大量图片的场景
对于一般App来说,Glide完全够用,而对于图片需求比较大的App,为了防止加载大量图片导致OOM,Fresco 会更合适一些。并不是说用Glide会导致OOM,Glide默认用的内存缓存是LruCache,内存不会一直往上涨。
二、假如让你自己写个图片加载框架,你会考虑哪些问题?
首先,梳理一下必要的图片加载框架的需求:
- 异步加载:线程池
- 切换线程:Handler,没有争议吧
- 缓存:LruCache、DiskLruCache
- 防止OOM:软引用、LruCache、图片压缩、Bitmap像素存储位置
- 内存泄露:注意ImageView的正确引用,生命周期管理
- 列表滑动加载的问题:加载错乱、队满任务过多问题
当然,还有一些不是必要的需求,例如加载动画等。
2.1 异步加载:
线程池,多少个?
缓存一般有三级,内存缓存、硬盘、网络。
由于网络会阻塞,所以读内存和硬盘可以放在一个线程池,网络需要另外一个线程池,网络也可以采用Okhttp内置的线程池。
读硬盘和读网络需要放在不同的线程池中处理,所以用两个线程池比较合适。
Glide 必然也需要多个线程池,看下源码是不是这样
public final class GlideBuilder { ... private GlideExecutor sourceExecutor; //加载源文件的线程池,包括网络加载 private GlideExecutor diskCacheExecutor; //加载硬盘缓存的线程池 ... private GlideExecutor animationExecutor; //动画线程池Glide使用了三个线程池,不考虑动画的话就是两个。
2.2 切换线程:
图片异步加载成功,需要在主线程去更新ImageView,
无论是RxJava、EventBus,还是Glide,只要是想从子线程切换到Android主线程,都离不开Handler。
看下Glide 相关源码:
class EngineJob implements DecodeJob.Callback,Poolable { private static final EngineResourceFactory DEFAULT_FACTORY = new EngineResourceFactory(); //创建Handler private static final Handler MAIN_THREAD_HANDLER = new Handler(Looper.getMainLooper(), new MainThreadCallback());问RxJava是完全用Java语言写的,那怎么实现从子线程切换到Android主线程的? 依然有很多3-6年的开发答不上来这个很基础的问题,而且只要是这个问题回答不出来的,接下来有关于原理的问题,基本都答不上来。
有不少工作了很多年的Android开发不知道鸿洋、郭霖、玉刚说,不知道掘金是个啥玩意,内心估计会想是不是还有叫掘银掘铁的(我不知道有没有)。
我想表达的是,干这一行,真的是需要有对技术的热情,不断学习,不怕别人比你优秀,就怕比你优秀的人比你还努力,而你却不知道。
2.3 缓存
我们常说的图片三级缓存:内存缓存、硬盘缓存、网络。
2.3.1 内存缓存
一般都是用LruCache
Glide 默认内存缓存用的也是LruCache,只不过并没有用Android SDK中的LruCache,不过内部同样是基于LinkHashMap,所以原理是一样的。
// -> GlideBuilder#buildif (memoryCache == null) { memoryCache = new LruResourceCache(memorySizeCalculator.getMemoryCacheSize());}既然说到LruCache ,必须要了解一下LruCache的特点和源码:
为什么用LruCache?
LruCache 采用最近最少使用算法,设定一个缓存大小,当缓存达到这个大小之后,会将最老的数据移除,避免图片占用内存过大导致OOM。
LruCache 源码分析
public class LruCache {// 数据最终存在 LinkedHashMap 中 private final LinkedHashMap map;...public LruCache(int maxSize) { if (maxSize <= 0) { throw new IllegalArgumentException("maxSize <= 0"); } this.maxSize = maxSize;// 创建一个LinkedHashMap,accessOrder 传true this.map = new LinkedHashMap(0, 0.75f, true); } ...LruCache 构造方法里创建一个LinkedHashMap,accessOrder 参数传true,表示按照访问顺序排序,数据存储基于LinkedHashMap。
先看看LinkedHashMap 的原理吧
LinkedHashMap 继承 HashMap,在 HashMap 的基础上进行扩展,put 方法并没有重写,说明LinkedHashMap遵循HashMap的数组加链表的结构,
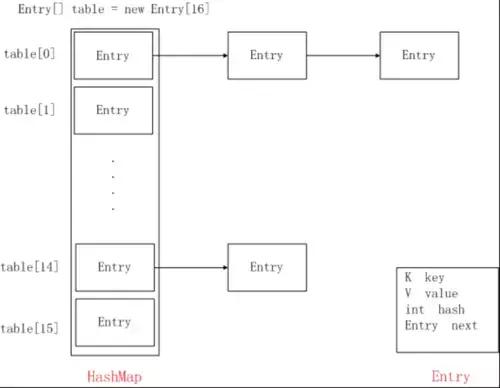
LinkedHashMap重写了 createEntry 方法。
看下HashMap 的 createEntry 方法
void createEntry(int hash, K key, V value, int bucketIndex) { HashMapEntry e = table[bucketIndex]; table[bucketIndex] = new HashMapEntry<>(hash, key, value, e); size++;}HashMap的数组里面放的是HashMapEntry 对象
看下LinkedHashMap 的 createEntry方法
void createEntry(int hash, K key, V value, int bucketIndex) { HashMapEntry old = table[bucketIndex]; LinkedHashMapEntry e = new LinkedHashMapEntry<>(hash, key, value, old); table[bucketIndex] = e; //数组的添加 e.addBefore(header); //处理链表 size++;}LinkedHashMap的数组里面放的是LinkedHashMapEntry对象
LinkedHashMapEntry
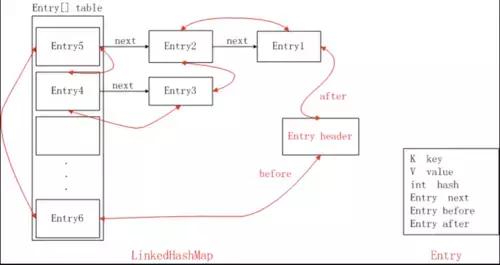
private static class LinkedHashMapEntry extends HashMapEntry { // These fields comprise the doubly linked list used for iteration. LinkedHashMapEntry before, after; //双向链表private void remove() { before.after = after; after.before = before; }private void addBefore(LinkedHashMapEntry existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; }LinkedHashMapEntry继承 HashMapEntry,添加before和after变量,所以是一个双向链表结构,还添加了addBefore和remove 方法,用于新增和删除链表节点。
LinkedHashMapEntry#addBefore
将一个数据添加到Header的前面
private void addBefore(LinkedHashMapEntry existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this;}existingEntry 传的都是链表头header,将一个节点添加到header节点前面,只需要移动链表指针即可,添加新数据都是放在链表头header 的before位置,链表头节点header的before是最新访问的数据,header的after则是最旧的数据。
再看下LinkedHashMapEntry#remove
private void remove() { before.after = after; after.before = before; }链表节点的移除比较简单,改变指针指向即可。
再看下LinkHashMap的put 方法
public final V put(K key, V value) { V previous; synchronized (this) { putCount++; //size增加 size += safeSizeOf(key, value); // 1、linkHashMap的put方法 previous = map.put(key, value); if (previous != null) { //如果有旧的值,会覆盖,所以大小要减掉 size -= safeSizeOf(key, previous); } } trimToSize(maxSize); return previous;}LinkedHashMap 结构可以用这种图表示
LinkHashMap 的 put方法和get方法最后会调用trimToSize方法,LruCache 重写trimToSize方法,判断内存如果超过一定大小,则移除最老的数据
LruCache#trimToSize,移除最老的数据
public void trimToSize(int maxSize) { while (true) { K key; V value; synchronized (this) { //大小没有超出,不处理 if (size <= maxSize) { break; } //超出大小,移除最老的数据 Map.Entry toEvict = map.eldest(); if (toEvict == null) { break; } key = toEvict.getKey(); value = toEvict.getValue(); map.remove(key); //这个大小的计算,safeSizeOf 默认返回1; size -= safeSizeOf(key, value); evictionCount++; } entryRemoved(true, key, value, null); }}对LinkHashMap 还不是很理解的话可以参考:图解LinkedHashMap原理
LruCache小结:
- LinkHashMap 继承HashMap,在 HashMap的基础上,新增了双向链表结构,每次访问数据的时候,会更新被访问的数据的链表指针,具体就是先在链表中删除该节点,然后添加到链表头header之前,这样就保证了链表头header节点之前的数据都是最近访问的(从链表中删除并不是真的删除数据,只是移动链表指针,数据本身在map中的位置是不变的)。
- LruCache 内部用LinkHashMap存取数据,在双向链表保证数据新旧顺序的前提下,设置一个最大内存,往里面put数据的时候,当数据达到最大内存的时候,将最老的数据移除掉,保证内存不超过设定的最大值。
2.3.2 磁盘缓存 DiskLruCache
依赖:
implementation 'com.jakewharton:disklrucache:2.0.2'
DiskLruCache 跟 LruCache 实现思路是差不多的,一样是设置一个总大小,每次往硬盘写文件,总大小超过阈值,就会将旧的文件删除。简单看下remove操作:
// DiskLruCache 内部也是用LinkedHashMapprivate final LinkedHashMap lruEntries = new LinkedHashMap(0, 0.75f, true);... public synchronized boolean remove(String key) throws IOException { checkNotClosed(); validateKey(key); Entry entry = lruEntries.get(key); if (entry == null || entry.currentEditor != null) { return false; } //一个key可能对应多个value,hash冲突的情况 for (int i = 0; i < valueCount; i++) { File file = entry.getCleanFile(i); //通过 file.delete() 删除缓存文件,删除失败则抛异常 if (file.exists() && !file.delete()) { throw new IOException("failed to delete " + file); } size -= entry.lengths[i]; entry.lengths[i] = 0; } ... return true; }可以看到 DiskLruCache 同样是利用LinkHashMap的特点,只不过数组里面存的 Entry 有点变化,Editor 用于操作文件。
private final class Entry { private final String key; private final long[] lengths; private boolean readable; private Editor currentEditor; private long sequenceNumber;...}2.4 防止OOM
加载图片非常重要的一点是需要防止OOM,上面的LruCache缓存大小设置,可以有效防止OOM,但是当图片需求比较大,可能需要设置一个比较大的缓存,这样的话发生OOM的概率就提高了,那应该探索其它防止OOM的方法。
方法1:软引用
回顾一下Java的四大引用:
- 强引用: 普通变量都属于强引用,比如 private Context context;
- 软应用: SoftReference,在发生OOM之前,垃圾回收器会回收SoftReference引用的对象。
- 弱引用: WeakReference,发生GC的时候,垃圾回收器会回收WeakReference中的对象。
- 虚引用: 随时会被回收,没有使用场景。
怎么理解强引用:
强引用对象的回收时机依赖垃圾回收算法,我们常说的可达性分析算法,当Activity销毁的时候,Activity会跟GCRoot断开,至于GCRoot是谁?这里可以大胆猜想,Activity对象的创建是在ActivityThread中,ActivityThread要回调Activity的各个生命周期,肯定是持有Activity引用的,那么这个GCRoot可以认为就是ActivityThread,当Activity 执行onDestroy的时候,ActivityThread 就会断开跟这个Activity的联系,Activity到GCRoot不可达,所以会被垃圾回收器标记为可回收对象。
软引用的设计就是应用于会发生OOM的场景,大内存对象如Bitmap,可以通过 SoftReference 修饰,防止大对象造成OOM,看下这段代码
private static LruCache> mLruCache = new LruCache>(10 * 1024){ @Override protected int sizeOf(String key, SoftReference value) { //默认返回1,这里应该返回Bitmap占用的内存大小,单位:K //Bitmap被回收了,大小是0 if (value.get() == null){ return 0; } return value.get().getByteCount() /1024; } };LruCache里存的是软引用对象,那么当内存不足的时候,Bitmap会被回收,也就是说通过SoftReference修饰的Bitmap就不会导致OOM。
当然,这段代码存在一些问题,Bitmap被回收的时候,LruCache剩余的大小应该重新计算,可以写个方法,当Bitmap取出来是空的时候,LruCache清理一下,重新计算剩余内存;
还有另一个问题,就是内存不足时软引用中的Bitmap被回收的时候,这个LruCache就形同虚设,相当于内存缓存失效了,必然出现效率问题。
方法2:onLowMemory
当内存不足的时候,Activity、Fragment会调用onLowMemory方法,可以在这个方法里去清除缓存,Glide使用的就是这一种方式来防止OOM。
//Glidepublic void onLowMemory() { clearMemory();}public void clearMemory() { // Engine asserts this anyway when removing resources, fail faster and consistently Util.assertMainThread(); // memory cache needs to be cleared before bitmap pool to clear re-pooled Bitmaps too. See #687. memoryCache.clearMemory(); bitmapPool.clearMemory(); arrayPool.clearMemory(); }方法3:从Bitmap 像素存储位置考虑
我们知道,系统为每个进程,也就是每个虚拟机分配的内存是有限的,早期的16M、32M,现在100+M,
虚拟机的内存划分主要有5部分:
- 虚拟机栈
- 本地方法栈
- 程序计数器
- 方法区
- 堆
而对象的分配一般都是在堆中,堆是JVM中最大的一块内存,OOM一般都是发生在堆中。
Bitmap 之所以占内存大不是因为对象本身大,而是因为Bitmap的像素数据, Bitmap的像素数据大小 = 宽 * 高 * 1像素占用的内存。
1像素占用的内存是多少?不同格式的Bitmap对应的像素占用内存是不同的,具体是多少呢?
在Fresco中看到如下定义代码
/** * Bytes per pixel definitions */ public static final int ALPHA_8_BYTES_PER_PIXEL = 1; public static final int ARGB_4444_BYTES_PER_PIXEL = 2; public static final int ARGB_8888_BYTES_PER_PIXEL = 4; public static final int RGB_565_BYTES_PER_PIXEL = 2; public static final int RGBA_F16_BYTES_PER_PIXEL = 8;如果Bitmap使用 RGB_565 格式,则1像素占用 2 byte,ARGB_8888 格式则占4 byte。在选择图片加载框架的时候,可以将内存占用这一方面考虑进去,更少的内存占用意味着发生OOM的概率越低。 Glide内存开销是Picasso的一半,就是因为默认Bitmap格式不同。
至于宽高,是指Bitmap的宽高,怎么计算的呢?看BitmapFactory.Options 的 outWidth
/** * The resulting width of the bitmap. If {@link #inJustDecodeBounds} is * set to false, this will be width of the output bitmap after any * scaling is applied. If true, it will be the width of the input image * without any accounting for scaling. * * outWidth will be set to -1 if there is an error trying to decode.
*/ public int outWidth;
看注释的意思,如果 BitmapFactory.Options 中指定 inJustDecodeBounds 为true,则为原图宽高,如果是false,则是缩放后的宽高。所以我们一般可以通过压缩来减小Bitmap像素占用内存。
扯远了,上面分析了Bitmap像素数据大小的计算,只是说明Bitmap像素数据为什么那么大。那是否可以让像素数据不放在java堆中,而是放在native堆中呢?据说Android 3.0到8.0 之间Bitmap像素数据存在Java堆,而8.0之后像素数据存到native堆中,是不是真的?看下源码就知道了~
- 8.0 Bitmap
java层创建Bitmap方法
public static Bitmap createBitmap(@Nullable DisplayMetrics display, int width, int height, @NonNull Config config, boolean hasAlpha, @NonNull ColorSpace colorSpace) { ... Bitmap bm; ... if (config != Config.ARGB_8888 || colorSpace == ColorSpace.get(ColorSpace.Named.SRGB)) { //最终都是通过native方法创建 bm = nativeCreate(null, 0, width, width, height, config.nativeInt, true, null, null); } else { bm = nativeCreate(null, 0, width, width, height, config.nativeInt, true, d50.getTransform(), parameters); } ... return bm; }Bitmap 的创建是通过native方法 nativeCreate
对应源码 8.0.0_r4/xref/frameworks/base/core/jni/android/graphics/Bitmap.cpp
//Bitmap.cppstatic const JNINativeMethod gBitmapMethods[] = { { "nativeCreate













 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









