







R学习往期回顾:
R学习:R for Data Science 向量(1)
R学习:R for Data Science 向量(2)
R学习 从Tidyverse学起,入门R语言 dplyr合并数据
R学习 流程控制 if,else,ifelse
R学习 从Tidyverse学起,入门R语言(tidyr和stringr)
R学习 从Tidyverse学起,入门R语言(tibble,readr和dplyr)
R学习:字符串
R学习:环境和函数
R学习:数据框的基本操作
R学习:R for Data Science(五)
R学习:R for Data Science(四)
R学习:R for Data Science(三)
R学习:R for Data Science(二)
R学习:R for Data Science(一)
函数是减少重复代码的一种工具,其减少重复代码的方法是,先识别出代码中的重复模式,然后将其提取出来,成为更容易修改和重用的独立部分。减少重复代码的另一种工具是迭代,它的作用在于可以对多个输入执行同一种处理,比如对多个列或多个数据集进行同样的操作。
for循环
假设我们有以下这样一个简单的 tibble
library(tidyverse)
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)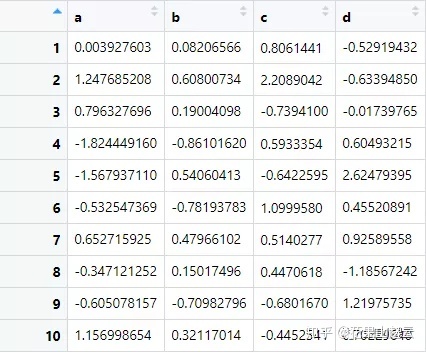
我们想要计算出每列的中位数。你完全可以使用复制粘贴来完成这个任务:
median(df$a)
median(df$b)
median(df$c)
median(df$d)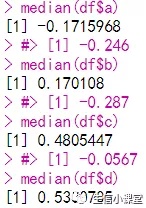
但这样做就违反了我们的经验法则:永远不要复制粘贴超过 2 次。相反,我们应该使用for 循环:
output <- vector("double", ncol(df)) # 1. 输出
for (i in seq_along(df)) { # 2. 序列
output[[i]] <- median(df[[i]]) # 3. 循环体
}
output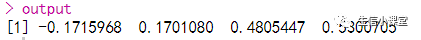
每个 for 循环都包括 3 个部分
输出: output <- vector("double", length(x))
在开始循环前,你必须为输出结果分配足够的空间。这对循环效率非常重要,如果在每次迭代中都使用 c() 来保存循环的结果,那么 for 循环的速度就会特别慢。创建给定长度的空向量的一般方法是使用 vector() 函数,该函数有两个参数:向量类型("logical"、 "integer"、 "double"、 "character" 等)和向量的长度。
序列: i in seq_along(df)
这部分确定了使用哪些值来进行循环:每一轮 for 循环都会赋予 i 一个来自于 seq_along(df) 的不同的值。我们可以将 i 看作一个代词,和 it 类似。
循环体: output[[i]] <- median(df[[i]])
这部分就是执行具体操作的代码。它们会重复运行,每次运行都使用一个不同的 i值。第一次迭代运行的是 output[[1]] <- median(df[[1]]),第二次迭代运行的是output[[2]] <- median[[2]],以此类推。
for循环的变体
如果已经掌握了基础的 for 循环,那么你就应该再熟悉一下它的几种变体。不管进行何种迭代,这些变体都非常重要。因此,即使在下一节中掌握了函数式编程技术,也不要忘了如何使用这些变体
在基础 for 循环之上有 4 种变体
• 修改现有对象,而不是创建新对象。
• 使用名称或值进行迭代,而不是使用索引。
• 处理未知长度的输出。
• 处理未知长度的序列。
1 修改现有对象
有时我们会希望使用 for 循环来修改现有的对象。例如,回想一下第 14 章中的一个问题,我们希望对数据框中的每列进行调整:
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}#将每一列数据标准化到0-1之间
df$a <- rescale01(df$a)
df$b <- rescale01(df$b)
df$c <- rescale01(df$c)
df$d <- rescale01(df$d)为了使用 for 循环解决这个问题,我们还是先思考一下 for 循环的 3 个部分
输出:
我们已经有了输出,和输入是相同的!
序列:
我们可以将数据框看作数据列的列表,因此可以使用 seq_along(df) 在每列中进行迭代。
函数体:
可以使用 rescale01() 函数。
因此可以写出以下代码:
for (i in seq_along(df)) {
df[[i]] <- rescale01(df[[i]])
}一般来说,你可以使用类似的循环来修改列表或数据框,要记住使用 [[,而不是 [。你或许已经发现了,我们在所有 for 循环中使用的都是 [[。我们认为甚至在原子向量中最好也使用 [[,因为它可以明确表示我们要处理的是单个元素。
2 循环模式
对向量进行循环的基本方式有 3 种,至此我们只介绍了最常用的一种方式:通过 for (iin seq_along(xs)) 使用数值索引进行循环,并使用 x[[i]] 提取出相应的值。另外两种循环方式如下
• 使用元素进行循环: for (x in xs)。如果只关心副作用,比如绘图或保存文件,那么这种方式是最适合的,因为有效率地保存输出结果是非常困难的。
• 使用名称进行循环: for (nm in names(xs))。这种方式会给出一个名称,你可以使用这个名称和 x[[nm]] 来访问元素的值。如果想要在图表标题或文件名中使用元素名称,那么你就应该使用这种方式。
如果想要创建命名的输出向量,请一定按照如下方式进行命名:
results <- vector("list", length(x))
names(results) <- names(x)使用数值索引进行循环是最常用的方式,因为给定位置后,就可以提取出元素的名称和值
for (i in seq_along(x)) {
name <- names(x)[[i]]
value <- x[[i]]
}3 未知的输出长度
有时你可能不知道输出的长度。例如,假设你想模拟长度随机的一些随机向量。你或许想要通过逐渐增加向量长度的方式来解决这个问题:
means <- c(0, 1, 2)
output <- double()
for (i in seq_along(means)) {
n <- sample(100, 1)
output <- c(output, rnorm(n, means[[1]]))
}
str(output)但这并不是一种非常高效的方式,因为 R 要在每次迭代中复制上一次迭代中的所有数据。从技术角度来看,你执行了一种“平方”(O(n2))操作,这意味着,如果元素数量增加到原来的 3 倍,那么循环时间就要增加到原来的 9 倍。
更好的解决方式是将结果保存在一个列表中,循环结束后再组合成一个向量
means <- c(0, 1, 2)
out <- vector("list", length(means))
for (i in seq_along(means)) {
n <- sample(100, 1)
out[[i]] <- rnorm(n, means[[i]])
}
str(out)
str(unlist(out))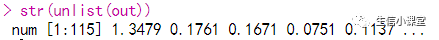
这里我们使用了 unlist() 函数将一个向量列表转换为单个向量。更严格的一种转换方式是使用 purrr::flatten_dbl() 函数,如果输入不是双精度型列表,那么它就会抛出一个错误。
其他情况下也可以使用这种编码模式
• 你或许会生成一个很长的字符串。不要使用 paste() 函数将每次迭代的结果与上一次连接起来,而应该将每次迭代结果保存在字符向量中,然后再使用 paste(output,collapse = "") 将这个字符向量组合成一个字符串。
• 你或许会生成一个很大的数据框。不要在每次迭代中依次使用 rbind() 函数,而应该将每次迭代结果保存在列表中,再使用dplyr::bind_rows(output) 将结果组合成数据框。
注意这种模式。只要遇到类似情况,就应该使用一个更复杂的对象来保存每次迭代的结果,最后再一次性组合起来。
4 未知的序列长度
有时你甚至不知道输入序列的长度。这种情况在模拟时很常见。例如,在掷硬币时,你想要循环到连续 3 次掷出正面向上。这种迭代不能使用 for 循环来实现,而应该使用 while循环。 while 循环比 for 循环更简单,因为前者只需要 2 个部分:条件和循环体。
while (condition) {
# 循环体
}while 循环也比 for 循环更常用,因为任何 for 循环都可以使用 while 循环重新实现,但不是所有 while 循环都能使用 for 循环重新实现
for (i in seq_along(x)) {
# 循环体
}
# 等价于
i <- 1
while (i <= length(x)) {
# 循环体
i <- i + 1
}在以下示例中,我们使用 while 循环找出了连续 3 次掷出正面向上的硬币所需的投掷次数:
flip <- function() sample(c("T", "H"), 1)
flips <- 0
nheads <- 0
while (nheads < 3) {
if (flip() == "H") {
nheads <- nheads + 1
} else {
nheads <- 0
}
flips <- flips + 1
}
flips下回继续
单基因泛癌分析链接
TCGA单基因免疫相关泛癌分析,懒人福音, 重磅来袭mp.weixin.qq.com
公众号“生信小课堂”

TCGA数据分析课程:生物信息学教学
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









