





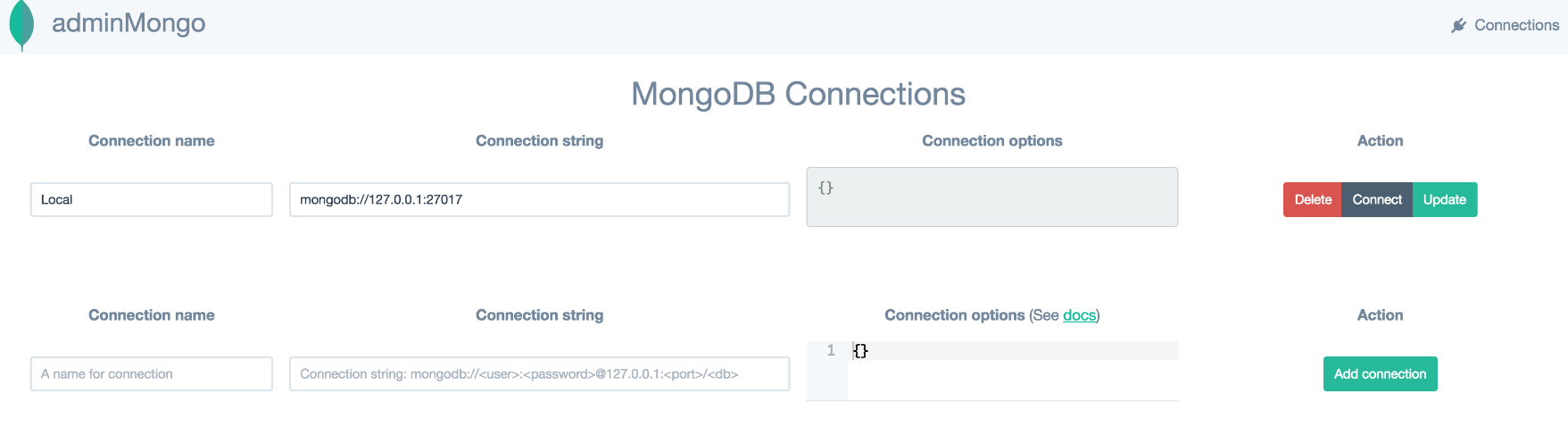
一、mongodb可视化工具 - adminMongo
https://www.cnblogs.com/shiweida/p/7692468.html
Installation
Navigate to folder & install adminMongo: git clone https://github.com/mrvautin/adminMongo.git && cd adminMongo
Install dependencies: npm install
Start application: npm start or node app
安装npm
https://blog.csdn.net/gaomengwang/article/details/77540429
sudo apt-get install nodejs
sudo ln -s /usr/bin/nodejs /usr/bin/node
sudo apt-get install npm
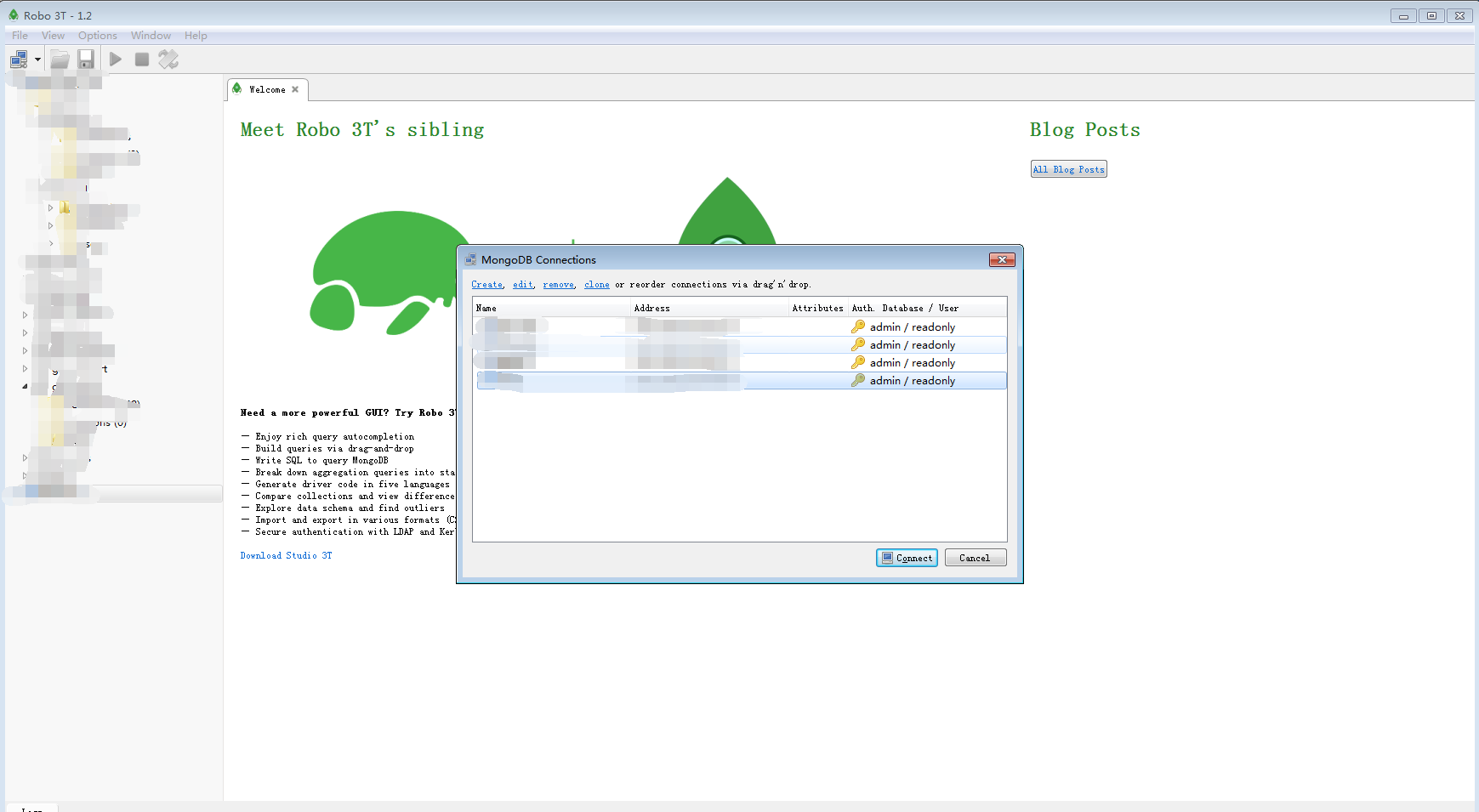
二、mongodb可视化工具 - Robo 3T
https://robomongo.org/
下载
点击:
create
Connection
name:
ip:
端口:
Authentication
Database 认证数据库
账号:
密码:
Auth Mechanism : MONGDB-CR
Test 测试,就可以连接成功!!!
三、pymongo使用方法
引用:
https://www.cnblogs.com/nixingguo/p/7260604.html
官方文档:
http://api.mongodb.com/python/current/api/pymongo/
http://api.mongodb.com/python/current/api/pymongo/collection.html
https://docs.mongodb.com/manual/reference/operator/query/
#!/usr/bin/env python#-*- coding:utf-8 -*-
"""MongoDB存储
在这里我们来看一下Python3下MongoDB的存储操作,在本节开始之前请确保你已经安装好了MongoDB并启动了其服务,另外安装好了Python
的PyMongo库。
连接MongoDB
连接MongoDB我们需要使用PyMongo库里面的MongoClient,一般来说传入MongoDB的IP及端口即可,第一个参数为地址host,
第二个参数为端口port,端口如果不传默认是27017。"""
importpymongo
client= pymongo.MongoClient(host='localhost', port=27017)"""这样我们就可以创建一个MongoDB的连接对象了。另外MongoClient的第一个参数host还可以直接传MongoDB的连接字符串,以mongodb开头,
例如:client = MongoClient('mongodb://localhost:27017/')可以达到同样的连接效果。"""
创建连接对象时,用client = pymongo.MongoClient('mongodb://user:password@localhost:27017/')这样的方式,增加权限认证
#指定数据库#MongoDB中还分为一个个数据库,我们接下来的一步就是指定要操作哪个数据库,在这里我以test数据库为例进行说明,所以下一步我们#需要在程序中指定要使用的数据库。
db=client.test#调用client的test属性即可返回test数据库,当然也可以这样来指定:#db = client['test']#两种方式是等价的。
#指定集合#MongoDB的每个数据库又包含了许多集合Collection,也就类似与关系型数据库中的表,下一步我们需要指定要操作的集合,#在这里我们指定一个集合名称为students,学生集合。还是和指定数据库类似,指定集合也有两种方式。
collection=db.students#collection = db['students']#插入数据,接下来我们便可以进行数据插入了,对于students这个Collection,我们新建一条学生数据,以字典的形式表示:
student={'id': '20170101','name': 'Jordan','age': 20,'gender': 'male'}#在这里我们指定了学生的学号、姓名、年龄和性别,然后接下来直接调用collection的insert()方法即可插入数据。
result=collection.insert(student)print(result)#在MongoDB中,每条数据其实都有一个_id属性来唯一标识,如果没有显式指明_id,MongoDB会自动产生一个ObjectId类型的_id属性。#insert()方法会在执行后返回的_id值。
#运行结果:#5932a68615c2606814c91f3d#当然我们也可以同时插入多条数据,只需要以列表形式传递即可,示例如下:
student1={'id': '20170101','name': 'Jordan','age': 20,'gender': 'male'}
student2={'id': '20170202','name': 'Mike','age': 21,'gender': 'male'}
result=collection.insert([student1, student2])print(result)#返回的结果是对应的_id的集合,运行结果:#[ObjectId('5932a80115c2606a59e8a048'), ObjectId('5932a80115c2606a59e8a049')]#实际上在PyMongo 3.X版本中,insert()方法官方已经不推荐使用了,当然继续使用也没有什么问题,#官方推荐使用insert_one()和insert_many()方法将插入单条和多条记录分开。
student={'id': '20170101','name': 'Jordan','age': 20,'gender': 'male'}
result=collection.insert_one(student)print(result)print(result.inserted_id)#运行结果:##5932ab0f15c2606f0c1cf6c5#返回结果和insert()方法不同,这次返回的是InsertOneResult对象,我们可以调用其inserted_id属性获取_id。
#对于insert_many()方法,我们可以将数据以列表形式传递即可,示例如下:
student1={'id': '20170101','name': 'Jordan','age': 20,'gender': 'male'}
student2={'id': '20170202','name': 'Mike','age': 21,'gender': 'male'}
result=collection.insert_many([student1, student2])print(result)print(result.inserted_ids)#insert_many()方法返回的类型是InsertManyResult,调用inserted_ids属性可以获取插入数据的_id列表,运行结果:
##[ObjectId('5932abf415c2607083d3b2ac'), ObjectId('5932abf415c2607083d3b2ad')]#查询,插入数据后我们可以利用find_one()或find()方法进行查询,find_one()查询得到是单个结果,find()则返回多个结果。
result= collection.find_one({'name': 'Mike'})print(type(result))print(result)#在这里我们查询name为Mike的数据,它的返回结果是字典类型,运行结果:##{'_id': ObjectId('5932a80115c2606a59e8a049'), 'id': '20170202', 'name': 'Mike', 'age': 21, 'gender': 'male'}#可以发现它多了一个_id属性,这就是MongoDB在插入的过程中自动添加的。
#我们也可以直接根据ObjectId来查询,这里需要使用bson库里面的ObjectId。
from bson.objectid importObjectId
result= collection.find_one({'_id': ObjectId('593278c115c2602667ec6bae')})print(result)#其查询结果依然是字典类型,运行结果:
#{' ObjectId('593278c115c2602667ec6bae'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}#当然如果查询_id':结果不存在则会返回None。
#对于多条数据的查询,我们可以使用find()方法,例如在这里查找年龄为20的数据,示例如下:
results= collection.find({'age': 20})print(results)for result inresults:print(result)#运行结果:
##{'_id': ObjectId('593278c115c2602667ec6bae'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}#{'_id': ObjectId('593278c815c2602678bb2b8d'), 'id': '20170102', 'name': 'Kevin', 'age': 20, 'gender': 'male'}#{'_id': ObjectId('593278d815c260269d7645a8'), 'id': '20170103', 'name': 'Harden', 'age': 20, 'gender': 'male'}#返回结果是Cursor类型,相当于一个生成器,我们需要遍历取到所有的结果,每一个结果都是字典类型。
#如果要查询年龄大于20的数据,则写法如下:
results= collection.find({'age': {'$gt': 20}})#在这里查询的条件键值已经不是单纯的数字了,而是一个字典,其键名为比较符号$gt,意思是大于,键值为20,这样便可以查询出所有#年龄大于20的数据。
#在这里将比较符号归纳如下表:
"""符号含义示例
$lt小于{'age': {'$lt': 20}}
$gt大于{'age': {'$gt': 20}}
$lte小于等于{'age': {'$lte': 20}}
$gte大于等于{'age': {'$gte': 20}}
$ne不等于{'age': {'$ne': 20}}
$in在范围内{'age': {'$in': [20, 23]}}
$nin不在范围内{'age': {'$nin': [20, 23]}}"""
#另外还可以进行正则匹配查询,例如查询名字以M开头的学生数据,示例如下:
results= collection.find({'name': {'$regex': '^M.*'}})#在这里使用了$regex来指定正则匹配,^M.*代表以M开头的正则表达式,这样就可以查询所有符合该正则的结果。
#在这里将一些功能符号再归类如下:
"""符号含义示例示例含义
$regex匹配正则{'name': {'$regex': '^M.*'}}name以M开头
$exists属性是否存在{'name': {'$exists': True}}name属性存在
$type类型判断{'age': {'$type': 'int'}}age的类型为int
$mod数字模操作{'age': {'$mod': [5, 0]}}年龄模5余0
$text文本查询{'$text': {'$search': 'Mike'}}text类型的属性中包含Mike字符串
$where高级条件查询{'$where': 'obj.fans_count == obj.follows_count'}自身粉丝数等于关注数"""
#这些操作的更详细用法在可以在MongoDB官方文档找到:#https://docs.mongodb.com/manual/reference/operator/query/
#计数#要统计查询结果有多少条数据,可以调用count()方法,如统计所有数据条数:
count=collection.find().count()print(count)#或者统计符合某个条件的数据:
count= collection.find({'age': 20}).count()print(count)#排序#可以调用sort方法,传入排序的字段及升降序标志即可,示例如下:
results= collection.find().sort('name', pymongo.ASCENDING)print([result['name'] for result inresults])#运行结果:
#['Harden', 'Jordan', 'Kevin', 'Mark', 'Mike']#偏移,可能想只取某几个元素,在这里可以利用skip()方法偏移几个位置,比如偏移2,就忽略前2个元素,得到第三个及以后的元素。
results= collection.find().sort('name', pymongo.ASCENDING).skip(2)print([result['name'] for result inresults])#运行结果:#['Kevin', 'Mark', 'Mike']#另外还可以用limit()方法指定要取的结果个数,示例如下:
results= collection.find().sort('name', pymongo.ASCENDING).skip(2).limit(2)print([result['name'] for result inresults])#运行结果:#['Kevin', 'Mark']#如果不加limit()原本会返回三个结果,加了限制之后,会截取2个结果返回。
#值得注意的是,在数据库数量非常庞大的时候,如千万、亿级别,最好不要使用大的偏移量来查询数据,很可能会导致内存溢出,#可以使用类似find({'_id': {'$gt': ObjectId('593278c815c2602678bb2b8d')}}) 这样的方法来查询,记录好上次查询的_id。
#更新#对于数据更新可以使用update()方法,指定更新的条件和更新后的数据即可,例如:
condition= {'name': 'Kevin'}
student=collection.find_one(condition)
student['age'] = 25result=collection.update(condition, student)print(result)#在这里我们将name为Kevin的数据的年龄进行更新,首先指定查询条件,然后将数据查询出来,修改年龄,#之后调用update方法将原条件和修改后的数据传入,即可完成数据的更新。
#运行结果:
#{'ok': 1, 'nModified': 1, 'n': 1, 'updatedExisting': True}#返回结果是字典形式,ok即代表执行成功,nModified代表影响的数据条数。
#另外update()方法其实也是官方不推荐使用的方法,在这里也分了update_one()方法和update_many()方法,用法更加严格,#第二个参数需要使用$类型操作符作为字典的键名,我们用示例感受一下。
condition= {'name': 'Kevin'}
student=collection.find_one(condition)
student['age'] = 26result= collection.update_one(condition, {'$set': student})print(result)print(result.matched_count, result.modified_count)#在这里调用了update_one方法,第二个参数不能再直接传入修改后的字典,而是需要使用{'$set': student}这样的形式,#其返回结果是UpdateResult类型,然后调用matched_count和modified_count属性分别可以获得匹配的数据条数和影响的数据条数。
#运行结果:#
##1 0#我们再看一个例子:
condition= {'age': {'$gt': 20}}
result= collection.update_one(condition, {'$inc': {'age': 1}})print(result)print(result.matched_count, result.modified_count)#在这里我们指定查询条件为年龄大于20,然后更新条件为{'$inc': {'age': 1}},执行之后会讲第一条符合条件的数据年龄加1。
#运行结果:#
##1 1#可以看到匹配条数为1条,影响条数也为1条。
#如果调用update_many()方法,则会将所有符合条件的数据都更新,示例如下:
condition= {'age': {'$gt': 20}}
result= collection.update_many(condition, {'$inc': {'age': 1}})print(result)print(result.matched_count, result.modified_count)#这时候匹配条数就不再为1条了,运行结果如下:#
##3 3#可以看到这时所有匹配到的数据都会被更新。
#删除#删除操作比较简单,直接调用remove()方法指定删除的条件即可,符合条件的所有数据均会被删除,示例如下:
result= collection.remove({'name': 'Kevin'})print(result)#运行结果:#
#{'ok': 1, 'n': 1}#另外依然存在两个新的推荐方法,delete_one()和delete_many()方法,示例如下:
result= collection.delete_one({'name': 'Kevin'})print(result)print(result.deleted_count)
result= collection.delete_many({'age': {'$lt': 25}})print(result.deleted_count)#运行结果:
##1#4#delete_one()即删除第一条符合条件的数据,delete_many()即删除所有符合条件的数据,返回结果是DeleteResult类型,#可以调用deleted_count属性获取删除的数据条数。
#更多#另外PyMongo还提供了一些组合方法,如find_one_and_delete()、find_one_and_replace()、find_one_and_update(),#就是查找后删除、替换、更新操作,用法与上述方法基本一致。
#另外还可以对索引进行操作,如create_index()、create_indexes()、drop_index()等。
#详细用法可以参见官方文档:http://api.mongodb.com/python/current/api/pymongo/collection.html
#另外还有对数据库、集合本身以及其他的一些操作,在这不再一一讲解,可以参见#官方文档:http://api.mongodb.com/python/current/api/pymongo/
四、python - mongodb基本操作 - 补充
http://www.cnblogs.com/liuwei0824/p/8329705.html
数据库
增
use db1#有则切换,无则新增
查
show dbs#查看所有
db #当前
删
db.dropDatabase()
集合:
增:
db.user
db.user.info
db.user.auth
查看
show collections
show tables
删
db.user.info.drop()
文档:
增
db.user.insert({"_id":1,"name":"egon"})
user0={"name":"egon","age":10,'hobbies':['music','read','dancing'],'addr':{'country':'China','city':'BJ'}
}
db.user.insert(user0)
db.user.insertMany([user1,user2,user3,user4,user5])
db.t1.insert({"_id":1,"a":1,"b":2,"c":3})#有相同的_id则覆盖,无相同的_id则新增,必须指定_id
db.t1.save({"_id":1,"z":6})
db.t1.save({"_id":2,"z":6})
db.t1.save({"z":6})
save与insert的区别:
若新增的数据中存在主键 ,insert() 会提示错误,而save() 则更改原来的内容为新内容。
如:
已存在数据: {_id :1, "name" : "n1"},再次进行插入操作时,
insert({_id :1, "name" : "n2"}) 会报主键重复的错误提示
save({ _id :1, "name" : "n2"}) 会把 n1 修改为 n2 。
相同点:
若新增的数据中没有主键时,会增加一条记录。
已存在数据: { _id :1, "name" : "n1"},再次进行插入操作时,
insert({"name" : "n2"}) 插入的数据因为没有主键,所以会增加一条数据
save({"name" : "n2"}) 增加一条数据。
查
比较运算:=,!=,>,<,>=,<=
#1、select * from db1.user where id = 3
db.user.find({"_id":3})#2、select * from db1.user where id != 3
db.user.find({"_id":{"$ne":3}})#3、select * from db1.user where id > 3
db.user.find({"_id":{"$gt":3}})#4、select * from db1.user where age < 3
db.user.find({"age":{"$lt":3}})#5、select * from db1.user where id >= 3
db.user.find({"_id":{"$gte":3}})#6、select * from db1.user where id <= 3
db.user.find({"_id":{"$lte":3}})#逻辑运算:$and,$or,$not
#1 select * from db1.user where id >=3 and id <=4;
db.user.find({"_id":{"$gte":3,"$lte":4}})#2 select * from db1.user where id >=3 and id <=4 and age >=40;
db.user.find({"_id":{"$gte":3,"$lte":4},"age":{"$gte":40}
})
db.user.find({"$and":[
{"_id":{"$gte":3,"$lte":4}},
{"age":{"$gte":40}}
]})#3 select * from db1.user where id >=0 and id <=1 or id >=4 or name = "yuanhao";
db.user.find({"$or":[
{"_id":{"$lte":1,"$gte":0}},
{"_id":{"$gte":4}},
{"name":"yuanhao"}
]})#4 select * from db1.user where id % 2 = 1;
db.user.find({"_id":{"$mod":[2,1]}})
db.user.find({"_id":{"$not":{"$mod":[2,1]}}
})#成员运算:$in,$nin
db.user.find({"name":{"$in":["alex","egon"]}})
db.user.find({"name":{"$nin":["alex","egon"]}})#正则匹配
select * from db1.user where name regexp "^jin.*?(g|n)$";
db.user.find({"name":/^jin.*?(g|n)$/i
})#查看指定字段
select name,age from db1.user where name regexp "^jin.*?(g|n)$";
db.user.find({"name":/^jin.*?(g|n)$/i
},
{"_id":0,"name":1,"age":1}
)#查询数组相关
db.user.find({"hobbies":"dancing"})
db.user.find({"hobbies":{"$all":["dancing","tea"]}
})
db.user.find({"hobbies.2":"dancing"})
db.user.find(
{},
{"_id":0,"name":0,"age":0,"addr":0,"hobbies":{"$slice":[1,2]},
}
)
db.user.find(
{},
{"_id":0,"name":0,"age":0,"addr":0,"hobbies":{"$slice":2},
}
)
db.user.find(
{"addr.country":"China"}
)
db.user.find().sort({"_id":1,"age":-1})
db.user.find().limit(2).skip(0)
db.user.find().limit(2).skip(2)
db.user.find().limit(2).skip(4)
db.user.find().distinct()
改
一 语法:
db.table.update(
条件,
修改字段,
其他参数
)
update db1.t1 set id=10 where name="egon";
db.table.update(
{},
{"age":11},
{"multi":true,"upsert":true
}
)1、update db1.user set age=23,name="武大郎" where name="wupeiqi";#覆盖式
db.user.update(
{"name":"wupeiqi"},
{"age":23,"name":"武大郎"}
)#局部修改:$set
db.user.update(
{"name":"alex"},
{"$set":{"age":73,"name":"潘金莲-alex"}}
)#改多条
db.user.update(
{"_id":{"$gte":1,"$lte":2}},
{"$set":{"age":53,}},
{"multi":true}
)#有则修改,无则添加
db.user.update(
{"name":"EGON"},
{"$set":{"name":"EGON","age":28,}},
{"multi":true,"upsert":true}
)#修改嵌套文档
db.user.update(
{"name":"潘金莲-alex"},
{"$set":{"addr.country":"Japan"}}
)#修改数组
db.user.update(
{"name":"潘金莲-alex"},
{"$set":{"hobbies.1":"Piao"}}
)#删除字段
db.user.update(
{"name":"潘金莲-alex"},
{"$unset":{"hobbies":""}}
)2、$inc
db.user.update(
{},
{"$inc":{"age":1}},
{"multi":true}
)
db.user.update(
{},
{"$inc":{"age":-10}},
{"multi":true}
)3、$push, $pop $pull
db.user.update(
{"name":"yuanhao"},
{"$push":{"hobbies":"tangtou"}},
{"multi":true}
)
db.user.update(
{"name":"yuanhao"},
{"$push":{"hobbies":{"$each":["纹身","抽烟"]}}},
{"multi":true}
)#从头删-1,从尾删1
db.user.update(
{"name":"yuanhao"},
{"$pop":{"hobbies":-1}},
{"multi":true}
)
db.user.update(
{"name":"yuanhao"},
{"$pop":{"hobbies":1}},
{"multi":true}
)#按条件删
db.user.update(
{"name":"yuanhao"},
{"$pull":{"hobbies":"纹身"}},
{"multi":true}
)#3、$addToSet
db.t3.insert({"urls":[]})
db.t3.update(
{},
{"$addToSet":{"urls":{"$each":["http://www.baidu.com","http://www.baidu.com","http://www.baidu.com","http://www.baidu.com","http://www.baidu.com"]}}},
{"multi":true}
)
删
db.user.deleteOne({"_id":{"$gte":3}})
db.user.deleteMany({"_id":{"$gte":3}})
db.user.deleteMany({})
聚合
一:$match
例:
select postfrom db1.emp where age > 20 group by post having avg(salary) > 10000;#$match
#1、select * from db1.emp where age > 20
db.emp.aggregate({"$match":{"age":{"$gt":20}}})#$group
#2、select post from db1.emp where age > 20 group by post;
db.emp.aggregate(
{"$match":{"age":{"$gt":20}}},
{"$group":{"_id":"$post"}}
)#3、select post,avg(salary) as avg_salary from db1.emp where age > 20 group by post;
db.emp.aggregate(
{"$match":{"age":{"$gt":20}}},
{"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}}
)#select post from db1.emp where age > 20 group by post having avg(salary) > 10000;
db.emp.aggregate(
{"$match":{"age":{"$gt":20}}},
{"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}
)
二: 投射
{"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表达式"}}
例1:
db.emp.aggregate(
{"$project":{"_id":0,"name":1,"post":1,"annual_salary":{"$multiply":[12,"$salary"]}}},
{"$group":{"_id":"$post","平均年薪":{"$avg":"$annual_salary"}}},
{"$match":{"平均年薪":{"$gt":1000000}}},
{"$project":{"部门名":"$_id","平均年薪":1,"_id":0}}
)
例2:
db.emp.aggregate(
{"$project":{"_id":0,"name":1,"hire_period":{"$subtract":[new Date(),"$hire_date"]}}}
)
db.emp.aggregate(
{"$project":{"_id":0,"name":1,"hire_year":{"$year":"$hire_date"}}}
)
db.emp.aggregate(
{"$project":{"_id":0,"name":1,"hire_period":{"$subtract":[{"$year":new Date()},{"$year":"$hire_date"}]}}}
)
例3:
db.emp.aggregate(
{"$project":{"_id":0,"new_name":{"$toUpper":"$name"},}}
)
db.emp.aggregate(
{"$match":{"name":{"$ne":"egon"}}},
{"$project":{"_id":0,"new_name":{"$concat":["$name","_SB"]},}}
)
db.emp.aggregate(
{"$match":{"name":{"$ne":"egon"}}},
{"$project":{"_id":0,"new_name":{"$substr":["$name",0,3]},}}
)
三:{"$group":{"_id":分组字段,"新的字段名":聚合操作符}}#select post,max,min,sum,avg,count,group_concat from db1.emp group by post;
db.emp.aggregate(
{"$group":{"_id":"$post","max_age":{"$max":"$age"},"min_id":{"$min":"$_id"},"avg_salary":{"$avg":"$salary"},"sum_salary":{"$sum":"$salary"},"count":{"$sum":1},"names":{"$push":"$name"}
}
}
)
四:排序:$sort、限制:$limit、跳过:$skip
db.emp.aggregate(
{"$match":{"name":{"$ne":"egon"}}},
{"$project":{"_id":1,"new_name":{"$substr":["$name",0,3]},"age":1}},
{"$sort":{"age":1,"_id":-1}},
{"$skip":5},
{"$limit":5}
)#补充
db.emp.aggregate({"$sample":{"size":3}}) #随机选取3个文档
补充:
db.tb1.find() //查询全部,用it查看下一页。
db.tb1.find({"age":1}) //查询年龄==1的记录
db.tb1.find({},{"age":1}) //查询年龄==1的记录
db.tb1.find({"name":{$all:["a","b"]}}) //查询name含有a,b的记录
db.tb1.find({"name":{$exists:true}}) //查询存在name字段的记录。
db.tb1.find({"age":{$nin:[12,14]}}) //查询age不含12,14值的记录。
db.tb1.find({name) //查询name含a字母的记录
.......
总结如下:
查询格式如下:Db.collection.find({“field”: { operator: val}})
field为colleciton的字段名,operator为操作符,val为比较值。
operator有如下:
$gt,$gte,$lt,$lte: val v1.
$all :都有, val {v1,v2,v3...}
$exists:存在, val true/false;
$ne :不等于, val v1
$mod: 取模。 Val [v1取模数,v2余数]
$in :包含某值,val [v1,v2,v3...]
$nin :不包含某值,val [v1,v2,v3...]
$size: 指定长度数组, val v1
$regex: 正则查询,val v1 :通配符查询:/s/ ,但是s/,/是这样语法错误。
Javascript查询: 编写function,然后查询。
>Find(条件).count() / limit(v) /skip(v) /sort({“field”: 1/-1},{“field2”: 1/-1}...)
分页查询,通过limit,skip,sort组合进行分页查询。
如每页X条,第N页
> Find(条件).SKIP * X).Limit(X).SORT.
distinct: 查询指定键的不同值。db.runCommand({"distinct":”集合名","key":"字段名"})
group: 较复杂。
五、mongodb聚合利用日期分组
参考:https://blog.csdn.net/u013066244/article/details/53842355
$dayOfYear: 返回该日期是这一年的第几天。(全年366天)
$dayOfMonth: 返回该日期是这一个月的第几天。(1到31)
$dayOfWeek: 返回的是这个周的星期几。(1:星期日,7:星期六)
$year: 返回该日期的年份部分
$month: 返回该日期的月份部分(between1 and 12.)
$week: 返回该日期是所在年的第几个星期(between 0and 53)
$hour: 返回该日期的小时部分
$minute: 返回该日期的分钟部分
$second: 返回该日期的秒部分(以0到59之间的数字形式返回日期的第二部分,但可以是60来计算闰秒。)
$millisecond:返回该日期的毫秒部分(between 0and 999.)
$dateToString:
{ $dateToString: { format:, date: } }
%Y Year (4 digits, zero padded) 0000-9999
%m Month (2 digits, zero padded) 01-12
%d Day of Month (2 digits, zero padded) 01-31
%H Hour (2 digits, zero padded, 24-hour clock) 00-23
%M Minute (2 digits, zero padded) 00-59
%S Second (2 digits, zero padded) 00-60
%L Millisecond (3 digits, zero padded) 000-999
%j Day of year (3 digits, zero padded) 001-366
%w Day of week (1-Sunday, 7-Saturday) 1-7
%U Week of year (2 digits, zero padded) 00-53
%% Percent Character as a Literal %
假设有这么一个集合
{"_id" : 1,"item" : "abc","price" : 10,"quantity" : 2,"date" : ISODate("2014-01-01T08:15:39.736Z")
}
我们在执行:
$project yearMonthDay format 都要加 “ ” 才行。
db.sales.aggregate(
[
{
$project: {
yearMonthDay: { $dateToString: { format:"%Y-%m-%d", date: "$date"} },
time: { $dateToString: { format:"%H:%M:%S:%L", date: "$date"} }
}
}
]
)
结果就是:
{ "_id" : 1, "yearMonthDay" : "2014-01-01", "time" : "08:15:39:736" }
$dateToString,这个需要mongodb3.0+支持。
再执行:
注意:year 和 $year 。。。 要加 “ ” 才能正常显示
db.sales.aggregate(
[
{
$project:
{
year: { $year:"$date"},
month: { $month:"$date"},
day: { $dayOfMonth:"$date"},
hour: { $hour:"$date"},
minutes: { $minute:"$date"},
seconds: { $second:"$date"},
milliseconds: { $millisecond:"$date"},
dayOfYear: { $dayOfYear:"$date"},
dayOfWeek: { $dayOfWeek:"$date"},
week: { $week:"$date"}
}
}
]
)
得到的结果就是:
{"_id" : 1,"year" : 2014,"month" : 1,"day" : 1,"hour" : 8,"minutes" : 15,"seconds" : 39,"milliseconds" : 736,"dayOfYear" : 1,"dayOfWeek" : 4,"week": 0
}
六、pymongo处理正则表达式的情况
在python里使用pymongo处理mongodb数据库,在插入或者查询的时候,我们有时需要使用操作符号,如set,in,
需求:需要用到正则表达式 来插入 或查询,如何操作?
1.首先要了解一下,mongodb里面的正则表达式怎么用
使用如下语法:
{ : { $regex: /pattern/, $options: '' } }
{ : { $regex: 'pattern', $options: '' } }
{ : { $regex: /pattern/ } }
或者
{ : /pattern/ }
当然option的含义是对正则表达式的一种选择,有
i 不区分大小写
m 包含锚的模式(即起始为 ^,结束为 $)
x 扩展
s 允许.点字符
详细的参考官网,这只是很简单的介绍
2.在pymongo里如何使用
mongodb默认使用的是bson数据,所以要在python里转换为该格式的数据
import bson
>>> pattern = re.compile('.*')
>>> regex = Regex.from_native(pattern)
>>> regex.flags ^= re.UNICODE
>>> db.collection.insert({'pattern': regex})
这里注意一下,Regex是bson的类,可以导入
我的实例:

for collection in col_list:
pattern = re.compile(time.strftime('%Y-%m-%d'))
regex = bson.regex.Regex.from_native(pattern)
regex.flags ^= re.UNICODE
for item in db[collection].find({"insert_time":regex}):
for j in item['value']:
...















 4351
4351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









