






Python项目–交通标志识别
您一定已经听说过自动驾驶汽车,乘客可以在其中完全依靠汽车行驶。但是要实现5级自动驾驶,车辆必须了解并遵守所有交通规则。
在人工智能和技术进步的世界中,许多研究人员和大公司,例如特斯拉,优步,谷歌,奔驰,丰田,福特,奥迪等,都在研究自动驾驶汽车和无人驾驶汽车。因此,为了实现该技术的准确性,车辆应该能够分辨交通标志并做出相应的决策。
什么是交通标志识别?
有几种不同类型的交通标志,例如限速,禁止进入,交通信号,左转或右转,行人横穿,重型车辆无法通过等。交通标志分类是识别交通标志属于哪个类别的过程。
交通标志识别–关于Python项目
在这个Python项目示例中,我们将构建一个深度神经网络模型,该模型可以将图像中出现的交通标志分类为不同的类别。通过这种模型,我们能够分辨和分析交通标志,这对于所有自动驾驶汽车都是非常重要的任务。
Python项目的数据集
对于此项目,我们使用Kaggle上可用的公共数据集:
(https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign)
数据集包含50,000多种不同交通标志的图像。它进一步分为43个不同的类别。数据集变化很大,有些类别的图像很多,而有些类别的图像很少。数据集的大小约为300 MB。数据集有一个train文件夹,其中包含每个类中的图像;还有一个test文件夹,我们将使用它来测试模型。
先决条件
该项目需要具备Keras,Matplotlib,Scikit-learn,Pandas,PIL和图像分类的先验知识。
要安装用于此Python数据科学项目的必要库,请在终端中输入以下命令:
pip install tensorflow keras sklearn matplotlib pandas pillow生成Python项目的步骤
创建一个Python脚本文件,并在项目文件夹中将其命名为traffic_signs.py。
我们分四个步骤讨论了我们建立交通标志分类模型的方法:
- 探索数据集
- 建立CNN模型
- 训练并验证模型
- 用测试数据集测试模型
步骤1:探索数据集
我们的“train”文件夹包含43个文件夹,每个文件夹代表一个不同的类别。文件夹的范围是0到42。在OS模块的帮助下,我们遍历所有类,并将图像及其各自的标签附加到数据和标签列表中。
PIL库用于将图像内容打开到数组中。
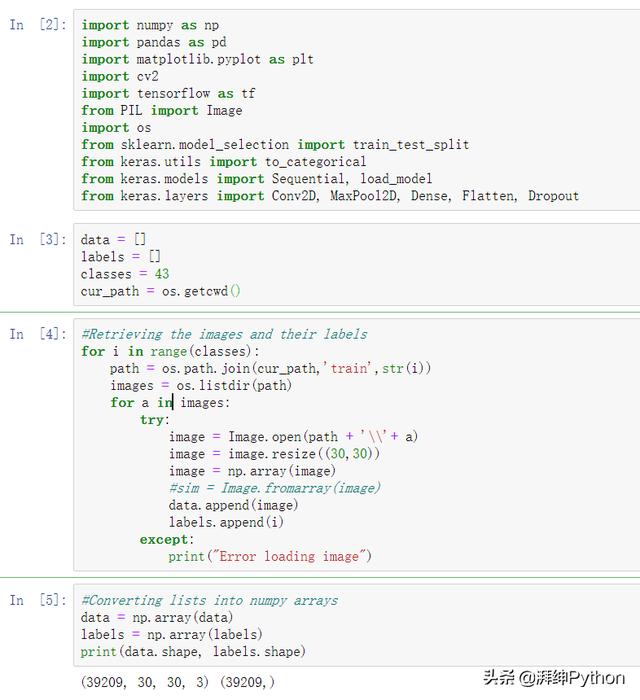
最后,我们将所有图像及其标签存储到列表(数据和标签)中。
我们需要将列表转换为numpy数组,以便提供给模型。
数据的形状为(39209、30、30、3),这意味着有39,209张图像的尺寸为30×30像素,最后的3意味着数据包含彩色图像(RGB值)。
通过sklearn库,我们使用train_test_split()方法来拆分训练和测试数据。
从keras.utils库中,我们使用to_categorical方法将y_train和t_test中存在的标签转换为独热编码。

步骤2:建立CNN模型
为了将图像分类为各自的类别,我们将建立一个CNN模型(卷积神经网络)。CNN最适合用于图像分类。
我们模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









